Pandas: как добавить данные в существующий файл CSV
Вы можете использовать следующий синтаксис в pandas для добавления данных в существующий файл CSV:
df.to_csv('existing.csv', mode='a', index= False , header= False ) Вот как интерпретировать аргументы в функции to_csv() :
- «existing.csv»: имя существующего CSV-файла.
- mode=’a’: используйте режим «добавления» вместо «w» — режима «записи» по умолчанию.
- index=False: не включать столбец индекса при добавлении новых данных.
- header=False: не включать заголовок при добавлении новых данных.
В следующем пошаговом примере показано, как использовать эту функцию на практике.
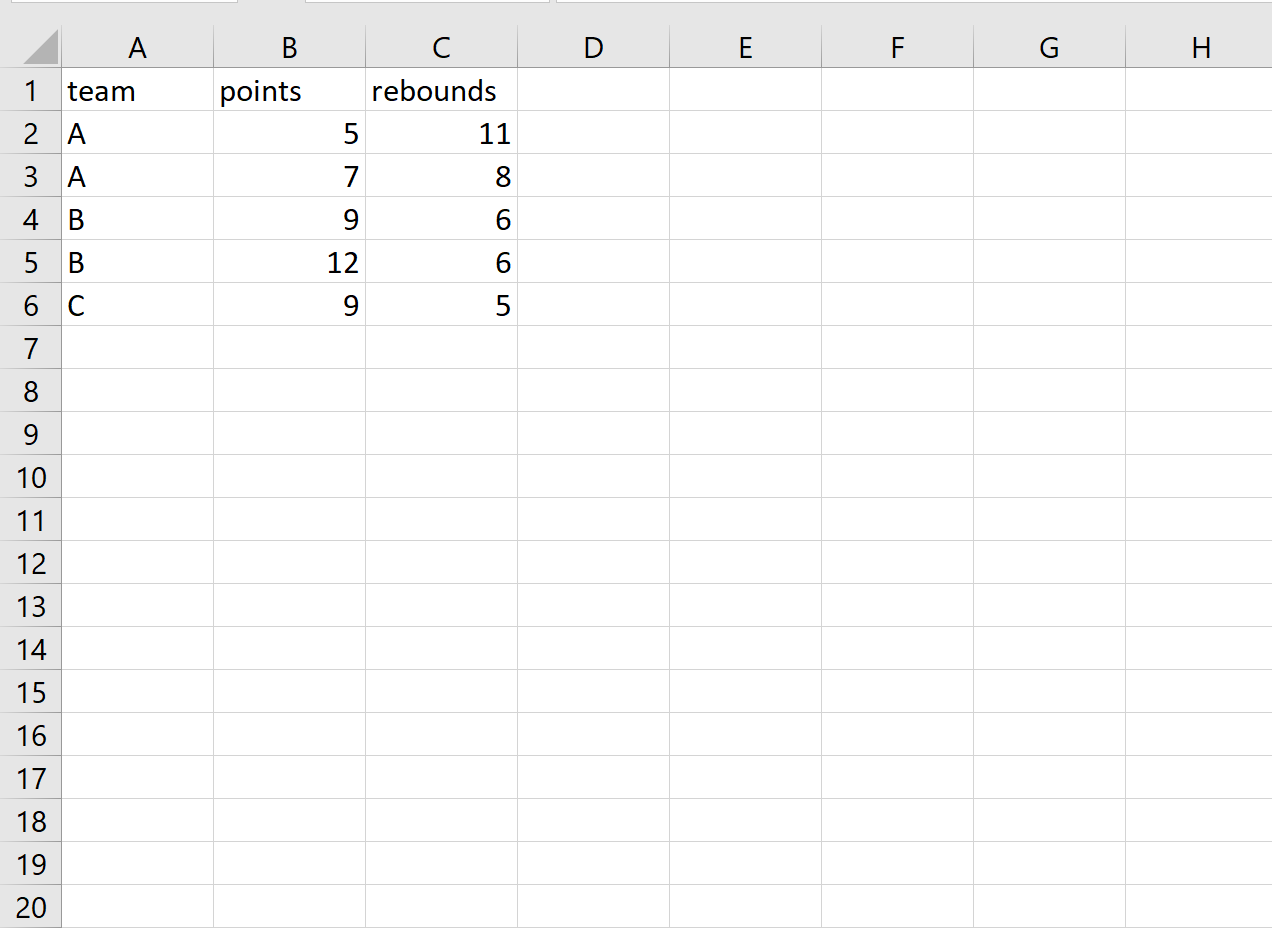
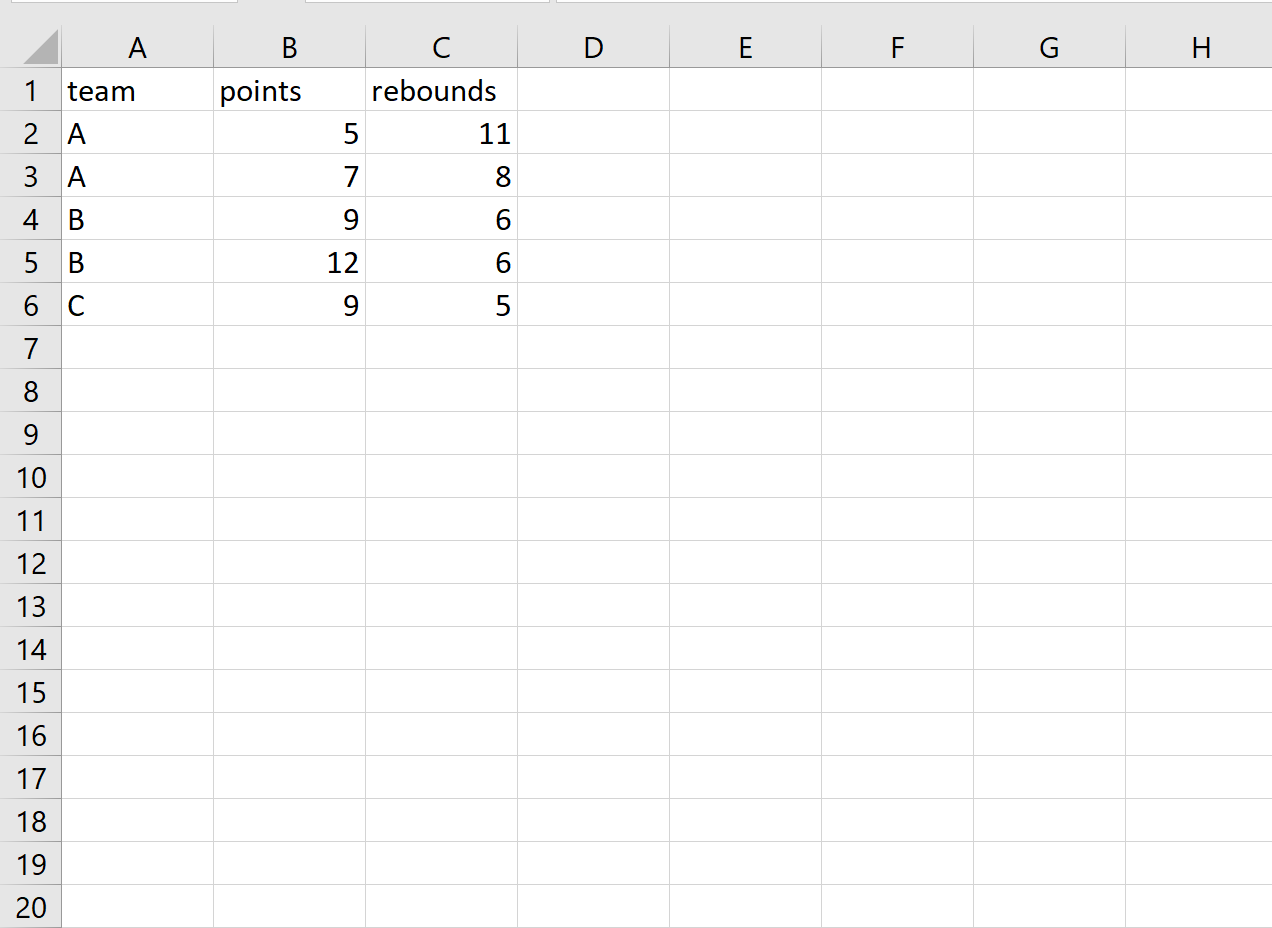
Шаг 1. Просмотр существующего CSV-файла
Предположим, у нас есть следующий существующий файл CSV:
Шаг 2: Создайте новые данные для добавления
Давайте создадим новый кадр данных pandas для добавления к существующему файлу CSV:
import pandas as pd #create DataFrame df = pd.DataFrame() #view DataFrame df team points rebounds 0 D 6 15 1 D 4 18 2 E 4 9 3 E 7 12 Шаг 3. Добавьте новые данные в существующий CSV-файл.
В следующем коде показано, как добавить эти новые данные в существующий CSV-файл:
df.to_csv('existing.csv', mode='a', index= False , header= False ) Шаг 4. Просмотрите обновленный файл CSV
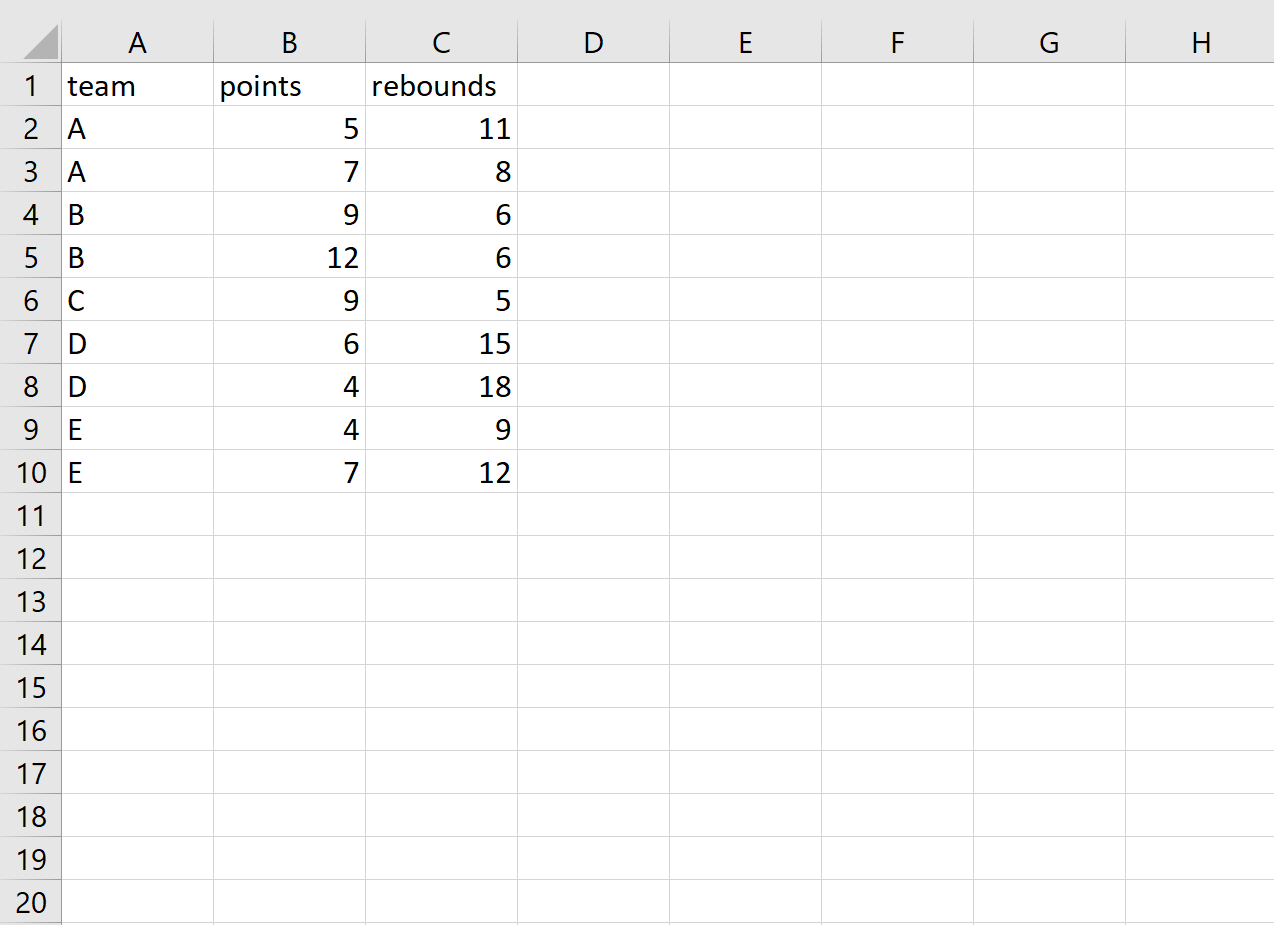
Когда мы открываем существующий файл CSV, мы видим, что новые данные были добавлены:
Примечания по добавлению данных
При добавлении данных в существующий CSV-файл обязательно проверьте, есть ли в существующем CSV-файле столбец индекса или нет.
Если в существующем CSV-файле нет индексного файла, вам нужно указать index=False в функции to_csv() при добавлении новых данных, чтобы Pandas не добавляли индексный столбец.
Вывод в csv по столбцам (python)
Как записать имеющие списки в csv файл по разным столбцам, чтобы еще вначале название столбцов (хедеры) написать. А то у меня код записывает все в один столбец построчно. Вот код:
import csv from mypars import all_id_z from mypars import all_href_z id_z = all_id_z href_z = all_href_z with open('zakup.csv', 'w', newline='') as csv_file: csv_writer = csv.writer(csv_file) for item in id_z: csv_writer.writerow([item]) for item in href_z: csv_writer.writerow([item]) Благодарю за ответы!
Отслеживать
задан 17 июл 2018 в 14:08
Nikita Afanasev Nikita Afanasev
57 1 1 серебряный знак 7 7 бронзовых знаков
длина у списков одинаковая?
17 июл 2018 в 14:11
@MaxU да одинаковая
17 июл 2018 в 14:17
2 ответа 2
Сортировка: Сброс на вариант по умолчанию
Если длина списков одинаковая то можно воспользоваться модулем Pandas:
import pandas as pd lst1 = [1,2,3,4,5] lst2 = [3,5,8,9,1] lst3 = [3,-11,0,2,7] data = dict(col1=lst1, col2=lst2, col3=lst3) df = pd.DataFrame(data) df.to_csv(r'c:/temp/res.csv', sep=';', index=False) from pathlib import Path print(Path(r'c:/temp/res.csv').read_text()) col1;col2;col3 1;3;3 2;5;-11 3;8;0 4;9;2 5;1;7 Модуль csv — чтение и запись CSV файлов

Формат CSV (Comma Separated Values) является одним из самых распространенных форматов импорта и экспорта электронных таблиц и баз данных. CSV использовался в течение многих лет до того, как был стандартизирован в RFC 4180. Запоздание четко определенного стандарта означает, что в данных, создаваемых различными приложениями, часто существуют незначительные различия. Эти различия могут вызвать раздражение при обработке файлов CSV из нескольких источников. Тем не менее, хотя разделители, символы кавычек и некоторые другие свойства различаются, общий формат достаточно универсален. Значит, возможно написать один модуль, который может эффективно манипулировать такими данными, скрывая детали чтения и записи данных от программиста.
Функции обработки CSV-файлов
csv.reader(csvfile, dialect=’excel’, **fmtparams) — возвращает объект reader, который построчно итерирует csvfile. Если csvfile является файловым объектом, то его нужно открыть с параметром newline=». Дополнительный параметр dialect используется для определения ряда параметров, характерных для специфического CSV диалекта. Он может быть подклассом Dialect или одной из строк, возвращаемой функцией list_dialects(). Также могут передаваться дополнительные ключевые аргументы fmtparams для переопределения отдельных параметров форматирования в текущем диалекте.
Каждая строка, считанная из файла csv, возвращается в виде списка строк. Автоматическое преобразование типов данных не выполняется, если не указан параметр формата QUOTE_NONNUMERIC (в этом случае все поля без кавычек преобразуются в числа с плавающей точкой).
Короткий пример использования:
csv.writer(csvfile, dialect=’excel’, **fmtparams) — возвращает объект writer, конвертирующий пользовательские данные в CSV-файл csvfile. csvfile может быть любым объектом с методом write(). Если csvfile является файловым объектом, то его нужно открыть с параметром newline=». Параметры dialect и fmtparams идентичны параметрам в функции csv.reader.
Необходимые методы экземпляра класса writer:
csvwriter.writerow(row) — записывает данные, представляющие одну строку CSV в файл, форматируя согласно текущему диалекту writer.
csvwriter.writerows(rows) — записывает данные, представляющие несколько строк CSV в файл, форматируя согласно текущему диалекту writer.
Пример использования writer :
csv.field_size_limit([new_limit]) — текущий максимальный размер поля. Если задан new_limit, то он становится новым макс. размером.
class csv.DictReader(f, fieldnames=None, restkey=None, restval=None, dialect=’excel’, *args, **kwds) — как reader, но отображает информацию о столбцах в словарь, ключи которого заданы в параметре fieldnames.
fieldnames это последовательность ключей. Если параметр опущен, в качестве ключей используются значения из первой строки файла. Если строка имеет больше полей, чем длина fieldnames , оставшиеся данные будут помещены в список с ключом из переменной restkey . Если строка имеет меньше полей, оставшиеся значения будут установлены в значение restval .
Остальные аргументы пробрасываются далее в экземпляр reader.
class csv.DictWriter(f, fieldnames, restval=», extrasaction=’raise’, dialect=’excel’, *args, **kwds) — как writer, но отображает словари в CSV-файл.
Обязательный параметр fieldnames — последовательность ключей, определяющие порядок, в котором значения из словаря будут записаны в строке CSV-файла f.
Параметр restval определяет значение в случае, если в словаре будет отсутствовать запись с данным ключом. Если словарь содержит лишние ключи, то поведение определяется параметром extrasaction . Если он ‘raise’, то выдаст ошибку. Если ‘ignore’, то такие ключи игнорируются.
Остальные аргументы пробрасываются далее в экземпляр writer.
Помимо методов writerow и writerows, DictWriter имеет также метод
DictWriter.writeheader() — записывает данные строки заголовка в CSV-файл, форматируя согласно текущему диалекту writer.
Пример использования DictWriter:
class csv.Dialect — для упрощения задания формата входных и выходных записей, конкретные параметры форматирования группируются в диалекты, подклассы csv.Dialect . Диалекты поддерживают следующие атрибуты:
Dialect.delimiter — разделитель столбцов в строке CSV-файла. По умолчанию ‘,’.
Dialect.quotechar — символ, использующийся для «склейки» поля, содержащего специальные символы, такие как delimiter, quotechar, или символы новой строки. По умолчанию используется значение ‘»‘.
Dialect.doublequote — как Dialect.quotechar , появляющийся внутри поля, должен экранироваться. Когда True, символ удваивается. Когда False, Dialect.escapechar используется как префикс к quotechar. По умолчанию True.
При записи файла, если doublequote=False и не установлен escapechar, выдаст ошибку при обнаружении quotechar в столбце.
Dialect.escapechar — символ, используемый writer для экранирования delimiter , если quoting установлен в QUOTE_NONE и quotechar , если doublequote=False . При чтении escapechar удаляет какое-либо особое значение со следующего символа. По умолчанию используется значение None, которое отключает экранирование.
Dialect.lineterminator — символы, используемые для завершения строки при записи. По умолчанию ‘\r\n’.
Dialect.skipinitialspace — если True, пробелы, непосредственно следующие за delimiter, игнорируются. Значение по умолчанию — False.
Dialect.strict — когда True, поднимает исключение если CSV файл не распознается. По умолчанию — False.
Dialect.quoting — контролирует, когда кавычки должны генерироваться writer и распознаваться reader. Он может принимать любые константы QUOTE_* и по умолчанию имеет значение QUOTE_MINIMAL.
csv.QUOTE_ALL — writer оборачивает в кавычки все поля.
csv.QUOTE_MINIMAL — writer оборачивает в кавычки только поля, содержащие специальные символы (delimiter, quotechar, lineterminator).
csv.QUOTE_NONNUMERIC — writer оборачивает в кавычки все поля, не являющиеся числами. reader преобразует все поля без кавычек к типу float.
csv.QUOTE_NONE — writer не оборачивает никакие поля в кавычки. Если в данных попадается delimiter или lineterminator, он предваряется символом escapechar, если установлен (исключение, если не установлен). reader не обрабатывает кавычки.
csv.register_dialect(name[, dialect[, **fmtparams]]) — связывает dialect с именем name. Подробности о диалектах см. в разделе «Диалекты и параметры форматирования»
csv.unregister_dialect(name) — удаляет связь диалекта с данным именем.
csv.get_dialect(name) — возвращает класс диалекта, свзанного с именем name.
csv.list_dialects() — список доступных диалектов. На данный момент это ‘excel’, ‘excel-tab’, ‘unix’.
Предустановленные диалекты
class csv.excel — диалект CSV-файла, обычно генерируемого программой Excel.
class csv.excel_tab — диалект CSV-файла, обычно генерируемого программой Excel с настройкой «разделитель с помощью TAB».
class csv.unix_dialect — диалект CSV-файла, обычно генерируемого в UNIX-системах (‘\n’ для новой строки, закавычивание всех полей).
Определение диалекта
class csv.Sniffer — используется для угадывания диалекта CSV-файла. Имеет следующие методы:
csvsniffer.sniff(sample, delimiters=None) — анализирует пример и возвращает Dialect, соответствующий обнаруженным параметрам. Если задан параметр delimiters , он интерпретируется как все возможные разделители.
csvsniffer.has_header(sample) — анализирует текст и возвращает True, если первая строка похожа на строку заголовков.
Методы определения диалекта являются эвристическими; это означает, что Sniffer может ошибаться.
Пример использования Sniffer:
Примеры
Простейший пример чтения CSV файла:
Чтение файла формата passwd:
Простейший пример записи CSV файла:
Для вставки кода на Python в комментарий заключайте его в теги
- Модуль csv - чтение и запись CSV файлов
- Создаём сайт на Django, используя хорошие практики. Часть 1: создаём проект
- Онлайн-обучение Python: сравнение популярных программ
- Книги о Python
- GUI (графический интерфейс пользователя)
- Курсы Python
- Модули
- Новости мира Python
- NumPy
- Обработка данных
- Основы программирования
- Примеры программ
- Типы данных в Python
- Видео
- Python для Web
- Работа для Python-программистов
- Сделай свой вклад в развитие сайта!
- Самоучитель Python
- Карта сайта
- Отзывы на книги по Python
- Реклама на сайте
На Python Как записать данные в несколько столбцов CSV?
Добрый день, написал код, который позволяет собирать данные с конфига XML и записывает эти данные в CSV - Таблицу. Не получается разобраться, почему у меня все данные записываются в один столбец. Решение есть, что в Excel я сделал "Разделить по столбцам" ориентир запятая и данные записались верно. Но хотелось бы узнать, где проблема в коде.
import xmltodict import csv with open("XML-FILE", "r") as cfg: dict = xmltodict.parse(cfg.read()) num = 1 with open('ACL.csv', 'w', newline="") as acl_file: fieldnames = ["ID","Order","Enabled", "Name", "Description", "IpVersion", "Src", "Dst", "Proxy", "Service", "ValidTime", "Action", "NAT", "SNAT", "DNAT"] listitem = dict['config']['list']['listitem'] writer = csv.DictWriter(acl_file, fieldnames=fieldnames, delimiter=',') writer.writeheader() for i in listitem: Dubl_name_ID = False Dubl_name_Order = False Dubl_name_Enabled = False Dubl_name_Name = False Dubl_name_Description = False Dubl_name_IpVersion = False Dubl_name_Src = False Dubl_name_Dst = False Dubl_name_Proxy = False Dubl_name_Service = False Dubl_name_Validtime = False Dubl_name_Action = False Dubl_name_NAT = False Dubl_name_SNAT = False Dubl_name_DNAT = False line = <> for j in i['variable']: try: text = j["#text"] except KeyError: text = "None" if j["@name"] == "Id": if Dubl_name_ID is False: line["ID"] = text elif Dubl_name_ID is True: line["ID"] = line["ID"] + "*" + text Dubl_name_ID is True if j["@name"] == "Order": if Dubl_name_Order is False: line["Order"] = text elif Dubl_name_Order is True: line["Order"] = line["Order"] + "*" + text Dubl_name_Order = True if j["@name"] == "Enabled": if Dubl_name_Enabled is False: line["Enabled"] = text elif Dubl_name_Enabled is True: line["Enabled"] = line["Enabled"] + "*" + text Dubl_name_Enabled = True if j["@name"] == "Name": if Dubl_name_Name is False: line["Name"] = text elif Dubl_name_Name is True: line["Name"] = line["Name"] + "*" + text Dubl_name_Name = True if j["@name"] == "Description": if Dubl_name_Description is False: line["Description"] = text elif Dubl_name_Description is True: line["Description"] = line["Description"] + "*" + text Dubl_name_Description = True if j["@name"] == "IpVersion" : if Dubl_name_IpVersion is False: line["IpVersion"] = text elif Dubl_name_IpVersion is True: line["IpVersion"] = line["IpVersion"] + "*" + text Dubl_name_IpVersion = True if j["@name"] == "Src": if Dubl_name_Src is False: line['Src'] = text elif Dubl_name_Src is True: line['Src'] = line['Src'] + "*" + text Dubl_name_Src = True if j["@name"] == "Dst" : if Dubl_name_Dst is False: line['Dst'] = text elif Dubl_name_Dst is True: line['Dst'] = line['Dst'] + "*" + text Dubl_name_Dst = True if j["@name"] == "Proxy": if Dubl_name_Proxy is False: line['Proxy'] = text elif Dubl_name_Proxy is True: line['Proxy'] = line['Proxy'] + "*" + text Dubl_name_Proxy = True if j["@name"] == "Service" : if Dubl_name_Service is False: line['Service'] = text elif Dubl_name_Service is True: line['Service'] = line['Service'] + "*" + text Dubl_name_Service = True if j["@name"] == "ValidTime" : if Dubl_name_Validtime is False: line['ValidTime'] = text elif Dubl_name_Validtime is True: line['ValidTime'] = line['ValidTime'] + text Dubl_name_Validtime = True if j["@name"] == "Action" : if Dubl_name_Action is False: line['Action'] = text elif Dubl_name_Action is True: line['Action'] = line['Action'] + "*" + text Dubl_name_Action = True if j["@name"] == "NAT": if Dubl_name_NAT is False: line['NAT'] = text elif Dubl_name_NAT is True: line['NAT'] = line['NAT'] + "*" + text Dubl_name_NAT = True if j["@name"] == "SNAT" : if Dubl_name_SNAT is False: line['SNAT'] = text elif Dubl_name_SNAT is True: line['SNAT'] = line['SNAT'] + "*" + text Dubl_name_SNAT = True if j["@name"] == "DNAT" : if Dubl_name_DNAT is False: line['DNAT'] = text elif Dubl_name_DNAT is True: line['DNAT'] = line['DNAT'] + "*" + text Dubl_name_DNAT = True num+=1 writer.writerow(line) acl_file.close() cfg.close()
P.S. Я не умею хорошо писать коды. Если покажите, как бы стоило более читабельно его написать, будет замечательно.
- Вопрос задан более двух лет назад
- 1202 просмотра
Комментировать
Решения вопроса 1
О каком "столбце" идет речь? CSV - файл, это обычный ТЕКСТОВЫЙ файл, в котором просто "по договоренности" все данные делятся разделителем. Не более.
Поэтому если вы просто открываете этот файл в MS EXCEL совершенно очевидно, что каждая запись будет представляться одной строчкой, которая попадает в один - как правило первый - столбец таблицы.
Если вы хотите с таким файлом в дальнейшем работать именно как с таблицей, то уже в EXCEL вам надо осуществить импорт данных их csv в xslx формат. Делается этот так:
Вкладка "Данные" -> Получение внешних данных ->Из текста->указываете имя вашего csv- файла ->выбераете формат "с разделителем"->Далее->выбираете используемый разделитель (например "запятая")->Далее->Готово->указываете место на листе, с которого импортированная таблица должна начинаться (обычно "=$A$1")->ОК
и смотрите, что у вас получилось в вашей теперь уже настоящей таблице EXCEL.
Ответ написан более двух лет назад
Maloyyy @Maloyyy Автор вопроса
Спасибо за ответ, да я так и сделал. До этого не знал, что CSV это просто текстовый файл.
Ответы на вопрос 0
Ваш ответ на вопрос
Войдите, чтобы написать ответ

- Python
- +1 ещё
Как открывать браузер у конкретного пользователя?
- 1 подписчик
- 7 часов назад
- 32 просмотра