Триггеры
Триггеры представляют специальный тип хранимой процедуры, которая вызывается автоматически при выполнении определенного действия над таблицей или представлением, в частности, при добавлении, изменении или удалении данных, то есть при выполнении команд INSERT, UPDATE, DELETE.
Формальное определение триггера:
CREATE TRIGGER имя_триггера ON [INSERT | UPDATE | DELETE] AS выражения_sql
Для создания триггера применяется выражение CREATE TRIGGER , после которого идет имя триггера. Как правило, имя триггера отражает тип операций и имя таблицы, над которой производится операция.
Каждый триггер ассоциируется с определенной таблицей или представлением, имя которых указывается после слова ON .
Затем устанавливается тип триггера. Мы можем использовать один из двух типов:
- AFTER : выполняется после выполнения действия. Определяется только для таблиц.
- INSTEAD OF : выполняется вместо действия (то есть по сути действие — добавление, изменение или удаление — вообще не выполняется). Определяется для таблиц и представлений
После типа триггера идет указание операции, для которой определяется триггер: INSERT , UPDATE или DELETE .
Для триггера AFTER можно применять сразу для нескольких действий, например, UPDATE и INSERT. В этом случае операции указываются через запятую. Для триггера INSTEAD OF можно определить только одно действие.
И затем после слова AS идет набор выражений SQL, которые собственно и составляют тело триггера.
Создадим триггер. Допустим, у нас есть база данных productsdb со следующим определением:
CREATE DATABASE productdb; GO USE productdb; CREATE TABLE Products ( Id INT IDENTITY PRIMARY KEY, ProductName NVARCHAR(30) NOT NULL, Manufacturer NVARCHAR(20) NOT NULL, ProductCount INT DEFAULT 0, Price MONEY NOT NULL );
Определим триггер, который будет срабатывать при добавлении и обновлении данных:
USE productdb; GO CREATE TRIGGER Products_INSERT_UPDATE ON Products AFTER INSERT, UPDATE AS UPDATE Products SET Price = Price + Price * 0.38 WHERE Id FROM inserted)
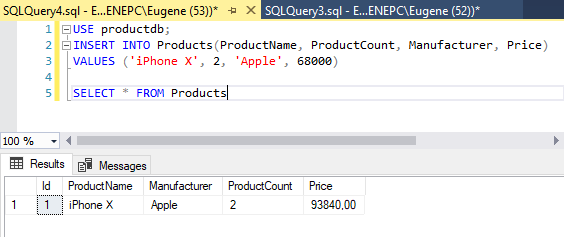
Допустим, в таблице Products хранятся данные о товарах. Но цена товара нередко содержит различные надбавки типа налога на добавленную стоимость, налога на добавленную коррупцию и так далее. Человек, добавляющий данные, может не знать все эти тонкости с налоговой базой, и он определяет чистую цену. С помощью триггера мы можем поправить цену товара на некоторую величину.
Таким образом, триггер будет срабатывать при любой операции INSERT или UPDATE над таблицей Products. Сам триггер будет изменять цену товара, а для получения того товара, который был добавлен или изменен, находим этот товар по Id. Но какое значение должен иметь Id такой товар? Дело в том, что при добавлении или изменении данные сохраняются в промежуточную таблицу inserted. Она создается автоматически. И из нее мы можем получить данные о добавленных/измененных товарах.
И после добавления товара в таблицу Products в реальности товар будет иметь несколько большую цену, чем та, которая была определена при добавлении:
Удаление триггера
Для удаления триггера необходимо применить команду DROP TRIGGER :
DROP TRIGGER Products_INSERT_UPDATE
Отключение триггера
Бывает, что мы хотим приостановить действие триггера, но удалять его полностью не хотим. В этом случае его можно временно отключить с помощью команды DISABLE TRIGGER :
DISABLE TRIGGER Products_INSERT_UPDATE ON Products
А когда триггер понадобится, его можно включить с помощью команды ENABLE TRIGGER :
ENABLE TRIGGER Products_INSERT_UPDATE ON Products
Триггер (базы данных)
Три́ггер (англ. trigger ) — это хранимая процедура особого типа, которую пользователь не вызывает непосредственно, а исполнение которой обусловлено действием по модификации данных: добавлением INSERT , удалением DELETE строки в заданной таблице, или изменением UPDATE данных в определенном столбце заданной таблицы реляционной базы данных. Триггеры применяются для обеспечения целостности данных и реализации сложной бизнес-логики. Триггер запускается сервером автоматически при попытке изменения данных в таблице, с которой он связан. Все производимые им модификации данных рассматриваются как выполняемые в транзакции, в которой выполнено действие, вызвавшее срабатывание триггера. Соответственно, в случае обнаружения ошибки или нарушения целостности данных может произойти откат этой транзакции.
Момент запуска триггера определяется с помощью ключевых слов BEFORE (триггер запускается до выполнения связанного с ним события; например, до добавления записи) или AFTER (после события). В случае, если триггер вызывается до события, он может внести изменения в модифицируемую событием запись (конечно, при условии, что событие — не удаление записи). Некоторые СУБД накладывают ограничения на операторы, которые могут быть использованы в триггере (например, может быть запрещено вносить изменения в таблицу, на которой «висит» триггер, и т. п.)
Кроме того, триггеры могут быть привязаны не к таблице, а к представлению (VIEW). В этом случае с их помощью реализуется механизм «обновляемого представления». В этом случае ключевые слова BEFORE и AFTER влияют лишь на последовательность вызова триггеров, так как собственно событие (удаление, вставка или обновление) не происходит.
В некоторых серверах триггеры могут вызываться не для каждой модифицируемой записи, а один раз на изменение таблицы. Такие триггеры называются табличными.
/* Триггер на уровне таблицы */ CREATE OR REPLACE TRIGGER DistrictUpdatedTrigger AFTER UPDATE ON district BEGIN INSERT INTO info VALUES ('table "district" has changed'); END;
В этом случае для отличия табличных триггеров от строчных вводится дополнительные ключевые слова при описании строчных триггеров. В Oracle это словосочетание FOR EACH ROW.
/* Триггер на уровне строки */ CREATE OR REPLACE TRIGGER DistrictUpdatedTrigger AFTER UPDATE ON district FOR EACH ROW BEGIN INSERT INTO info VALUES ('one string in table "district" has changed'); END;
SQL-Ex blog

Триггер представляет собой блок кода, который автоматически выполняется после исполнения некоторой операции с таблицей или представлением базы данных, точнее, после операции Insert, Update, Delete. Например, в приложении банка триггер может использоваться для вставки данных в таблицу истории/аудита для всех имеющих место исходных транзакций.
Некоторые ключевые моменты:
- Триггер может вызываться до или после события. Триггеры весьма полезны, когда база данных используется множеством приложений, и важно постоянно сохранять базу данных в согласованном состоянии, когда бы ни изменялись определенные данные.
- Хотя триггеры очень полезны для автоматизации изменений данных и позволяют легко вести аудит, у триггеров имеются также и недостатки. Поскольку триггеры выполняются при всякой модификации данных, это может привести к избыточной нагрузке на систему.
- Еще одним недостатком триггеров является сложность отслеживания и понимания их логики.
Триггер уровня строки
Триггер уровня строки срабатывает всякий раз, когда строка в таблице подвергается воздействию. Например, если триггер уровня строки определен на таблице, в которую одним оператором вставляется 100 строк, то триггер выполнится 100 раз — по разу на каждую строку.
Триггер уровня оператора
Как подразумевает имя, триггер уровня оператора выполняется только один раз на оператор или на транзакцию. Другими словами, если некий оператор выполняется на таблице, то вне зависимости от количества строк, на которые он воздействует, триггер сработает только один раз. Возвращаясь к предыдущему примеру, если на таблице определен триггер уровня оператора, и в эту таблице одним оператором вставляется 100 строк, триггер выполнится один раз.
Триггеры в PostgreSQL
- Триггеры в PostgreSQL поддерживают операции truncate.
- PostgreSQL не поддерживает триггеры, не имеющие связанной триггерной функции.
- Create trigger — используется для создания триггера
- Drop trigger — используется для удаления триггера
- Alter trigger — используется для изменения имени существующего триггера
- Disable trigger — используется для отключения заданного или всех триггеров, связанных с таблицей
- Enable trigger — используется для включения конкретного или всех триггеров, связанных с таблицей
Базовый синтаксис триггера в PostgreSQL:
CREATE TRIGGER trigger_name
< событие >
ON table_name
[FOR [EACH] < ROW | STATEMENT >]
EXECUTE PROCEDURE trigger_function
Давайте рассмотрим этот синтаксис.
Для начала триггеру дается имя — trigger_name. За ним следует время срабатывания триггера, которым может быть либо before (до), либо after (после), в зависимости от операции, которая должна быть выполнена на целевой таблице. Затем указывается одно из следующих событий — insert, update, delete, truncate. Затем указывается имя таблицы с последующим типом триггера, которым является row (на строку) или statement (на оператор). Наконец, указывается связанная с триггером функция — trigger_function:
Базовый синтаксис триггерной функции PostgreSQL
CREATE FUNCTION trigger_function()
RETURNS TRIGGER
LANGUAGE PLPGSQL
AS $$
BEGIN
-- логика триггера
END;
$$
Триггерная функция не имеет аргументов, а возвращаемое значение имеет тип trigger. После определения триггерной функции она должна быть связана с одним или более событий, вызывающих срабатывание триггера, таких как insert, update и delete.
Пример триггера уровня строки
Сценарий: Имеется две таблицы stocks и stock_audits; для каждой строки данных, вставленных в таблицу stocks выполняется триггер stocks_trigger и вставляет одну строку данных в другую таблицу stock_audits.
CREATE TRIGGER stocks_trigger
AFTER INSERT ON public."Stocks"
FOR EACH ROW
EXECUTE PROCEDURE stock_auditfunc();
CREATE OR REPLACE FUNCTION stock_auditfunc() RETURNS TRIGGER AS $my_table$
BEGIN
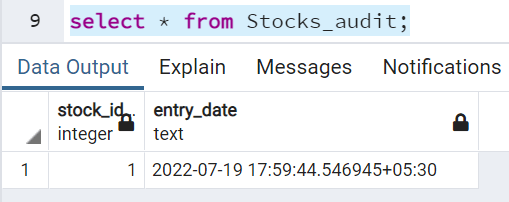
INSERT INTO stocks_audit(stock_id, entry_date) VALUES (new.ID, current_timestamp);
RETURN NEW;
END;
$my_table$ LANGUAGE plpgsql;
Таблицы до вставки:
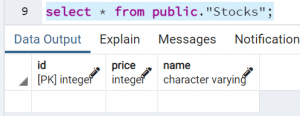
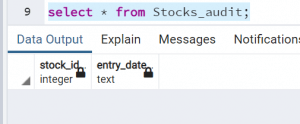
Таблица после вставки и выполнения триггера:
INSERT INTO public."Stocks"
VALUES (1,3000,'TCS');

Замечание: Для массовой операции, например, когда сразу обрабатывается 100 строк, триггер уровня строки выполняется 100 раз.
Триггер уровня оператора
Можно модифицировать определение предыдущего триггера следующим образом. Триггер должен выполняться один раз на операцию вне зависимости от числа обрабатываемых строк.
CREATE TRIGGER stocks_trigger
AFTER INSERT ON public."Stocks"
FOR EACH STATEMENT
EXECUTE PROCEDURE stock_auditfunc();
Доступ к триггерам PostgreSQL с помощью PgAdmin и консольного приложения PSQL
С триггерами в PostgreSQL можно эффективно работать либо с помощью PgAdmin, либо посредством psql-терминала, как показывается ниже.
Доступ к триггерам посредством PgAdmin:
Триггеры имеют отношение к таблицам и перечисляются в ветке каждой таблицы, как показано ниже,
Servers->User Server->Databases->User Database->Schemas->User Schema->Tables-> User Tables->Triggers
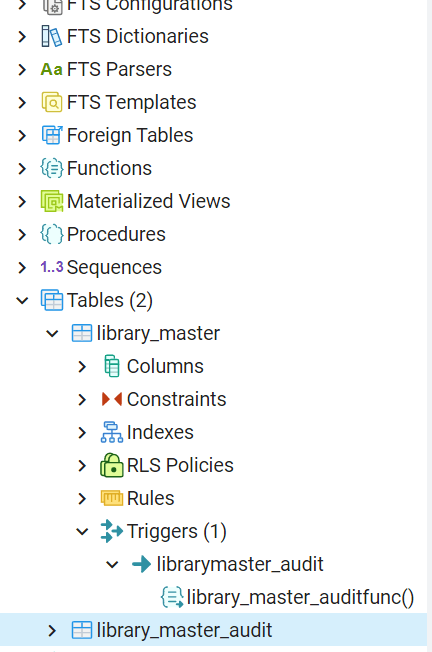
Доступ к триггерам посредством psql:
Чтобы получить список триггеров конкретной таблицы в базе данных в psql, имеются следующие команды:
Вы не любите триггеры?

При проектировании достаточно объёмных реляционных баз данных часто принимается решение об отступлении от нормальной формы — «денормализации».
Причины могут быть разными. От попытки ускорения доступа к определённым данным, ограничений используемой платформы/фреймворка/средств разработки и до недостатка квалификации разработчика/проектировщика БД.
Впрочем, строго говоря, ссылка на ограничения фреймфорка и т.п. — по сути попытка оправдать недостаток квалификации.
Денормализованные данные — слабое звено, через которое легко можно привести нашу базу в неконсистентное (нецелостное) состояние.
Что с этим делать?
Пример
В базе данных есть таблица с какими-то финансовыми операциями: поступление и списание средств по разным счетам.
Нужно всегда знать остаток средств на счёте.
В нормализованных данных остаток средств — всегда рассчитываемая величина. Суммируем все поступления минус списания.
Однако, когда количество операций ну очень большое, то каждый раз рассчитывать остаток слишком затратно.
Поэтому принято решение хранить актуальные остатки в отдельной таблице. Как обновлять данные в этой таблице?
Решение «как обычно»
Практически во всех информационных системах, с которыми мне приходилось работать, эту задачу выполняло внешнее приложение, в котором реализована бизнес логика. Хорошо, если приложение несложное и точек изменения данных — одна, из формы в пользовательском интерфейсе. А если есть какие-то импорты, API, сторонние приложения и так далее? И эти вещи делают разные люди, команды? А если не одна таблица с итогами, а их несколько в разных разрезах? А если ещё и не одна таблица с операциями (встречал и такое)?
Тут уследить за тем, что разработчик при обновлении операции не забыл обновить ещё кучку таблиц, становится всё сложнее и сложнее. Данные теряют целостность. Остатки по счёту не соответствуют операциям. Конечно, тестирование должно выявить такие ситуации. Но мы живём не в таком идеальном мире.
Кошки Триггеры
В качестве альтернативы для контроля целостности денормализованных данных «взрослой» СУБД используют триггеры.
Часто приходилось слышать, что триггеры жутко замедляют базу данных, поэтому их использование нецелесообразно.
Вторым аргументом было то, что вся логика находится в отдельном приложении и держать бизнес логику в разных местах тоже нецелесообразно.
Тормоза
Триггер срабатывает внутри транзакции, изменяющей данные в таблице. Транзакция не может быть завершена, если триггер не произвёл необходимых действий. Отсюда вывод: триггеры должны быть как можно «легче». Пример «тяжёлого» запроса в триггере:
update totals set total = select sum(operations.amount) from operations where operations.account = current_account where totals.account = current_accountЗапрос обращается к таблице операций (operations) и суммирует все суммы операций (amount) для счёта (account).
Такой запрос с ростом базы данных будет съедать всё больше и больше времени и ресурсов. Но того же результата можно добиться, используя «лёгкий» запрос типа:
update totals set total = totals.total + current_amount where totals.account = current_accountТакой триггер при добавлении новой строки просто увеличит итог по счёту, не рассчитывая его заново, он не зависит от объёма данных в таблицах. Рассчитывать итог заново нет смысла, так как мы можем быть уверены, что триггер срабатывает ВСЕГДА при добавлении новой операции.
Аналогично обрабатывается удаление и изменение строк. Такого типа триггеры практически не замедлят операции, но будут гарантировать связность и целостностность данных.
Всегда, когда я наблюдал «тормоза» при вставке данных в таблицу с триггером, это был образчик такого «тяжёлого» запроса. И в подавляющем большинстве случаев удавалось переписать его в «лёгком» стиле.
Бизнес логика
Тут стоит отделить мух от котлет. Есть смысл отличать функции, обеспечивающие целостность данных, от собственно бизнес логики. В каждом таком случае задаю вопрос: если бы данные были нормализованы, то была бы нужна такая функция? Если ответ положительный — это бизнес логика. Отрицательный — обеспечение целостности данных. Смело заворачивайте эти функции в триггеры.
Впрочем, есть мнение, что всю бизнес логику легко можно реализовать средствами современной СУБД, такой как PostgreSQL или Oracle. Подтверждение нахожу в своём just-for-fun проекте.
Надеюсь, эта статья поможет уменьшить количество багов в вашей информационной системе.
Конечно, я далёк от мысли, что всё здесь написанное, является истиной в последней инстанции. В реальной жизни, конечно же, всё сложнее. Поэтому решения в каждом конкретном случае принимать вам. Используйте своё инженерное мышление!
P.S.
- В статье автор обратил внимание лишь на один аспект использования триггеров с целью обратить внимание на использование такого мощного инструмента. Тема, конечно же, значительно обширнее.
- Подход, описанный в статье, может позволить отказаться от индексов на таблице operations, что может ускорить вставку данных в эту таблицу. На больших объёмах этот эффект легко компенсирует в том числе и временнЫе затраты на работу триггера, не говоря уже о затратах памяти на индексы.
- Важно понимать какой инструмент для чего использовать, тогда вы избежите многих проблем, например, со statement restart в BEFORE триггерах
- Для логов триггеры — вообще мастхев