работа с графами в Python
Будет использоваться ненаправленный связный граф V=6 E=6. Существует две популярные методики представления графов: матрица смежности (эффективна с плотными графами) и список связей (эффективно с разряженными графами). Будем использовать второй способ.
graph = 'A': ['B', 'C'], 'B': ['A', 'D', 'E'], 'C': ['A', 'F'], 'D': ['B'], 'E': ['B', 'F'], 'F': ['C', 'E']>
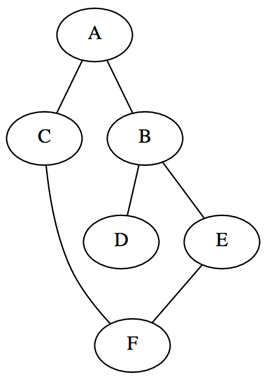
2 Depth-First Search — Поиск вглубину
Алгоритм поиска вглубину: исследуем сначала все возможные вершины (из выбранного корня) доступные из текущей, прежде чем возвращаться назад. Данный алгоритм можно реализовать как рекурсивно, так и итеративно. Последовательность действий:
- Помечаем текущую вершину как посещённую
- Исследуем каждую соседнюю вершину не включённую в список уже посещённых
- Вариант с DFS and BFS in Python (модифицированный, т.к. set не поддерживает упорядоченность элементов)
graph = 'A': ['B', 'C'], 'B': ['A', 'D', 'E'], 'C': ['A', 'F'], 'D': ['B'], 'E': ['B', 'F'], 'F': ['C', 'E']> def dfs(graph, start): visited, stack = [], [start] while stack: vertex = stack.pop() if vertex not in visited: visited.append(vertex) stack.extend(set(graph[vertex]) - set(visited)) return visited print(dfs(graph, 'A'))
['A', 'C', 'F', 'E', 'B', 'D']
- Вариант с DFS and BFS graph traversal (Python recipe) (модифицированный, т.к. для реализации стека нам необходимо добавлять элементы в конец списка, а не в начало)
graph = 'A': ['B', 'C'], 'B': ['A', 'D', 'E'], 'C': ['A', 'F'], 'D': ['B'], 'E': ['B', 'F'], 'F': ['C', 'E']> def iteractive_dfs(graph, start, path=None): """iterative depth first search from start""" if path is None: path = [] q = [start] while q: v = q.pop() if v not in path: path = path + [v] q += graph[v] return path print(iteractive_dfs(graph, 'A'))
['A', 'C', 'F', 'E', 'B', 'D']
3 DFS Paths — поиск пути между двумя вершинами
graph = 'A': ['B', 'C'], 'B': ['A', 'D', 'E'], 'C': ['A', 'F'], 'D': ['B'], 'E': ['B', 'F'], 'F': ['C', 'E']> def dfs_paths(graph, start, goal): stack = [(start, [start])] # (vertex, path) while stack: (vertex, path) = stack.pop() for next in set(graph[vertex]) - set(path): if next == goal: yield path + [next] else: stack.append((next, path + [next])) print(list(dfs_paths(graph, 'A', 'F')))
[['A', 'C', 'F'], ['A', 'B', 'E', 'F']]
4 Bread-Firsth Search — Поиск вширину
Позволяет найти кратчайший путь между двумя вершинами. Довольно сложно реализовать рекурсивно, гораздо проще реализовать его с использованием очереди.
graph = 'A': ['B', 'C'], 'B': ['A', 'D', 'E'], 'C': ['A', 'F'], 'D': ['B'], 'E': ['B', 'F'], 'F': ['C', 'E']> from queue import deque def bfs(graph, start): visited, queue = [], deque([start]) while queue: vertex = queue.pop() if vertex not in visited: visited.append(vertex) queue.extendleft(set(graph[vertex]) - set(visited)) return visited print(bfs(graph, 'A'))
['A', 'B', 'C', 'D', 'E', 'F']
5 BFS Paths
from queue import deque graph = 'A': ['B', 'C'], 'B': ['A', 'D', 'E'], 'C': ['A', 'F'], 'D': ['B'], 'E': ['B', 'F'], 'F': ['C', 'E']> def bfs_paths(graph, start, goal): queue = deque([(start, [start])]) while queue: (vertex, path) = queue.pop() for next in set(graph[vertex]) - set(path): if next == goal: yield path + [next] else: queue.appendleft((next, path+[next])) print(list(bfs_paths(graph, 'A', 'F'))) def shortest_path(graph, start, goal): try: return next(bfs_paths(graph, start, goal)) except StopIteration: return None print(shortest_path(graph, 'A', 'F')) print(shortest_path(graph, 'E', 'D')) print(shortest_path(graph, 'A', 'D')) print(shortest_path(graph, 'F', 'D'))
[['A', 'C', 'F'], ['A', 'B', 'E', 'F']] ['A', 'C', 'F'] ['E', 'B', 'D'] ['A', 'B', 'D'] ['F', 'E', 'B', 'D']
Author: Pavel Vavilin
Created: 2017-11-09 Thu 19:40
5 графов, которые должен знать каждый Data Scientist

Если вы анализируете поведение пользователей, выстраиваете сети или решаете другие динамические задачи, вам не обойтись без структур, которые специально созданы для визуализации взаимоотношений между различными объектами. Речь, разумеется, о графах. Рассказываем про пять разных типов графов: как они применяются в Data Science и как реализованы в Python.

Освойте профессию «Data Scientist»
Графы в Python
Граф состоит из отдельных точек (вершин) и соединяющих их линий (ребер). Вершины могут обозначать любые объекты: пользователей сайта, компьютеры корпоративной сети, населенные пункты на карте. Ребра отображают связи между этими объектами: каких пользователей тот или иной человек добавил в друзья, какие компьютеры объединяются прямым подключением, между какими городами проложены дороги. Такая схема позволяет решать множество прикладных задач, и для каждой из них есть много подходящих графов.
Профессия / 24 месяца
Data Scientist
Дата-сайентисты решают поистине амбициозные задачи. Научитесь создавать искусственный интеллект, обучать нейронные сети, менять мир и при этом хорошо зарабатывать. Программа рассчитана на новичков и плавно введет вас в Data Science.
5 491 ₽/мес 9 983 ₽/мес

Такие структуры гораздо сложнее привычных таблиц баз данных. Представьте себе, что вам нужно создать карту значимых объектов обычного городского района, чтобы понять, где чаще всего бывают его жители. Вам нужно отметить все магазины, школы, МФЦ, и определить вес каждой из точки. Такой код непросто написать с нуля, а полученный результат очень сложно визуализировать в пригодном для работы формате — хаос повседневности формирует очень запутанные связи, даже если мы говорим про район, а не про город или страну. К счастью, Python-программистам не приходится заниматься подготовительной работой. Они могут воспользоваться специальной библиотекой, которая объединяет все необходимые инструменты для создания и анализа графов — NetworkX. Мы также используем этот пакет в следующих примерах.

Станьте дата-сайентистом и решайте амбициозные задачи с помощью нейросетей
1. Разбивка вершин на группы
Анализ связных компонентов (connected components) позволяет вам определить внутренние множества внутри вашего графа. Например, вы можете разбить посетителей интернет-магазина на группы по их предпочтениям или географической принадлежности. Или связать между собой подозрительные транзакции в банковской системе, чтобы предположить, что все эти действия провела одна группа мошенников.  Технически алгоритм объединяет в себе два метода, с помощью которых можно найти кратчайший путь между вершинами графа: поиск по ширине (Breadth First Search, BFS) и поиск по глубине (Depth First Search, DFS). Самые старательные ученики Data Science могут подробнее прочитать о них здесь, а мы сразу перейдем к коду. Допустим, вам нужно распределить города по континентам, используя информацию о расстоянии между ними. Исходный граф выглядит следующим образом:
Технически алгоритм объединяет в себе два метода, с помощью которых можно найти кратчайший путь между вершинами графа: поиск по ширине (Breadth First Search, BFS) и поиск по глубине (Depth First Search, DFS). Самые старательные ученики Data Science могут подробнее прочитать о них здесь, а мы сразу перейдем к коду. Допустим, вам нужно распределить города по континентам, используя информацию о расстоянии между ними. Исходный граф выглядит следующим образом: 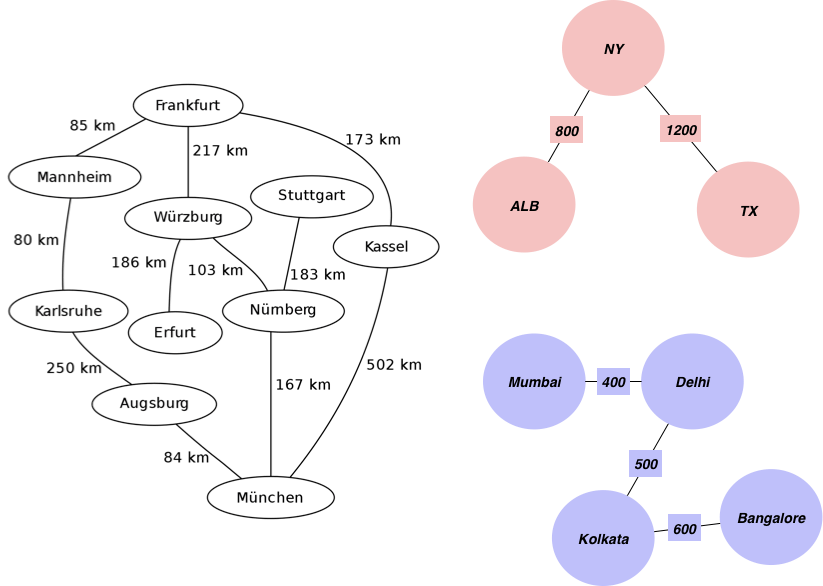 Сначала мы создаем список граней графа, где расстояния будут использоваться в качестве весов:
Сначала мы создаем список граней графа, где расстояния будут использоваться в качестве весов: 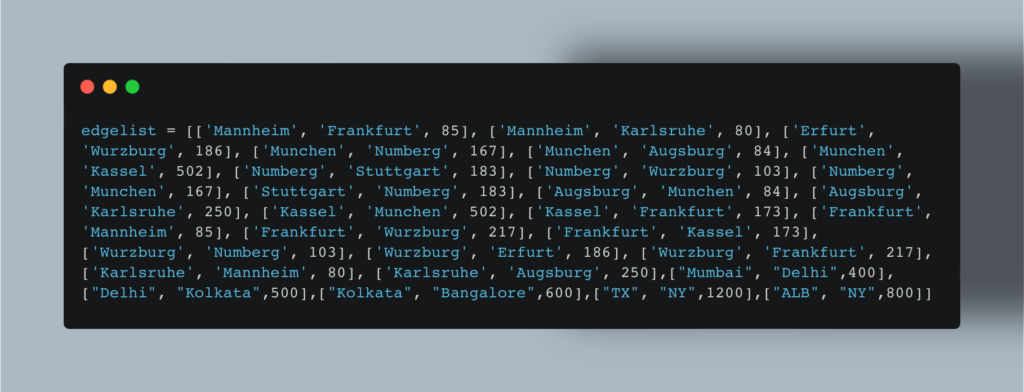 Теперь строим граф с помощью Networkx:
Теперь строим граф с помощью Networkx:  Остается применить к полученной структуре алгоритм связных компонент:
Остается применить к полученной структуре алгоритм связных компонент:  Готово — мы получили три группы городов, объединенных по континентальному принципу. Эту модель можно применять для самых разных целей. Если бы вместо городов у нас были, например, идентификаторы пользователей, а вместо расстояний — их траты в разных товарных категориях, алгоритм сгруппировал бы их по предпочтениям.
Готово — мы получили три группы городов, объединенных по континентальному принципу. Эту модель можно применять для самых разных целей. Если бы вместо городов у нас были, например, идентификаторы пользователей, а вместо расстояний — их траты в разных товарных категориях, алгоритм сгруппировал бы их по предпочтениям.
2. Поиск кратчайшего пути
Вычисление наименьшего расстояния между двумя точками — одна из старейших задач программирования. Один из наилучших алгоритмов для ее решения еще в конце 50-х разработал нидерландский математик Эдсгер Дейкстра (Edsger Dijkstra), причем человечество может благодарить за это открытие… его невесту. Как рассказывал сам Дейкстра, однажды его так утомили походы по магазинам вместе с молодой женой, что во время краткой передышки он задумался — как оптимизировать этот процесс? Буквально за 20 минут он разработал метод, который теперь называется алгоритмом Дейкстры. Метод прост, как все гениальное. Для начала Data Scientist узнает расстояния от начальной точки до каждой точки в пути. Эти значения присваиваются граням графа. Далее алгоритм поочередно проходит по каждой вершине, на каждом шаге определяя наименьшее расстояние до очередной точки. Когда все точки посещены, вы получаете наименьший маршрут. По словам самого математика, метод оказался так прост потому, что у него под рукой не было ни клочка бумаги — все калькуляции приходилось вести в голове. Такой способ не дает углубиться в вычисления, поэтому итоговое решение настолько просто, насколько это вообще возможно. Теперь о том, как алгоритм Дейкстры реализован в Python. Для решения задачи достаточно двух строчек кода: 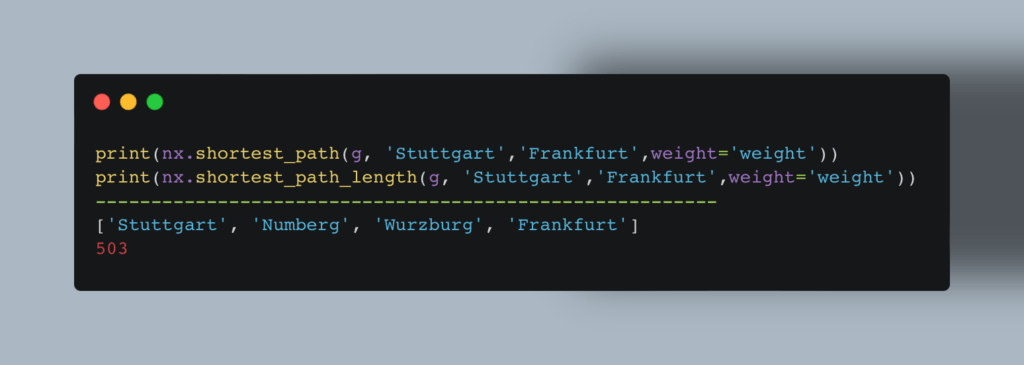 Мы также можем найти кратчайшее расстояние между всеми парами:
Мы также можем найти кратчайшее расстояние между всеми парами: 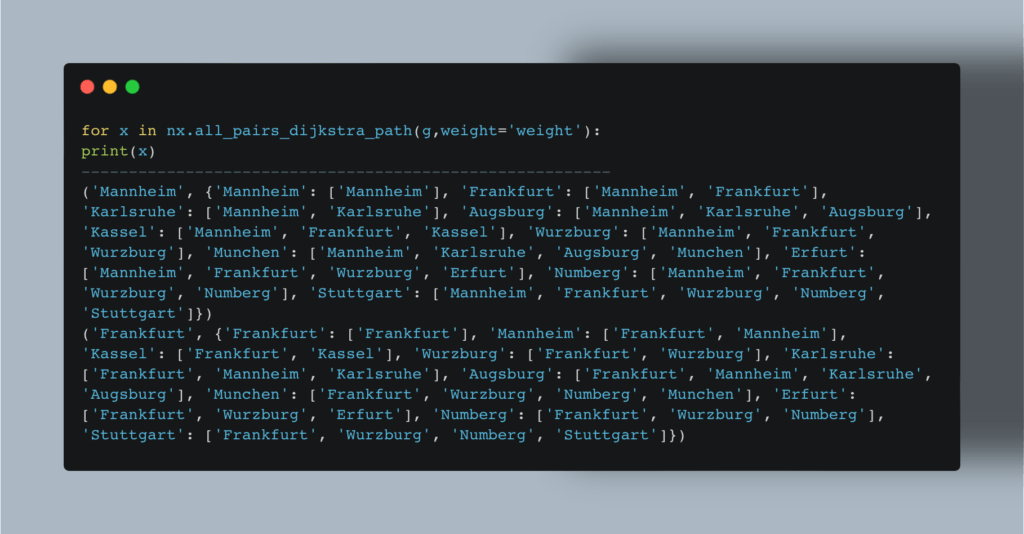 В нашем примере мы определили маршруты между городами, но этот же метод можно использовать и для выстраивания связей между пользователями соцсети, и для планирования оптимального маршрута покупателя в торговом зале, и для любых прочих подобных проблем.
В нашем примере мы определили маршруты между городами, но этот же метод можно использовать и для выстраивания связей между пользователями соцсети, и для планирования оптимального маршрута покупателя в торговом зале, и для любых прочих подобных проблем.
Читайте также 8 причин стать дата-сайентистом в 2023 году
3. Поиск оптимального пути
Всем знакомы головоломки, в которых нужно начертить какую-либо фигуру, не проходя дважды через одну точку. В профессии Data Scientist такие задачи возникают, когда нужно проложить оптимальный путь для кабеля, помочь торговым представителям или мастерам по обслуживанию банкоматов спланировать маршрут, и так далее. В каждом случае помогает алгоритм минимального остовного дерева (Minimum Spanning Tree). Этот термин обозначает подграф, который объединяет ребра с минимально возможной суммой весов. Это не всегда означает, что одна вершина не может иметь больше двух ребер — главное значение имеет итоговая сумма их значений. 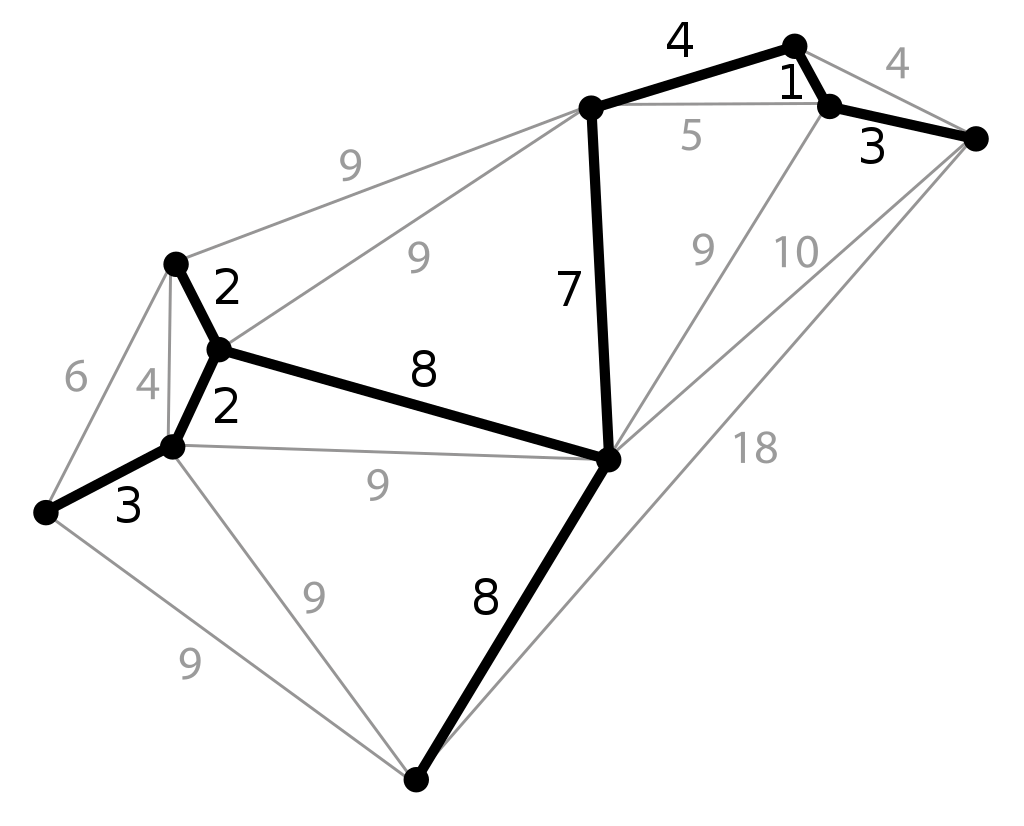 Чтобы построить такую структуру, используйте команду:
Чтобы построить такую структуру, используйте команду: 
4. Рейтинг вершин графа
Еще одна нередкая задача — найти, какие вершины имеют самое важное значение в рамках того или иного явления. Например, поисковики определяют вес разных интернет-страниц, академики считают, какие научные работы чаще всего ссылаются исследователи, социальные сети отслеживают пользователей с наибольшим количеством подписок. На примере социальных сетей мы и рассмотрим метод. Достаем из хранилища данных список пользователей Фейсбук*:  И построим граф:
И построим граф: 
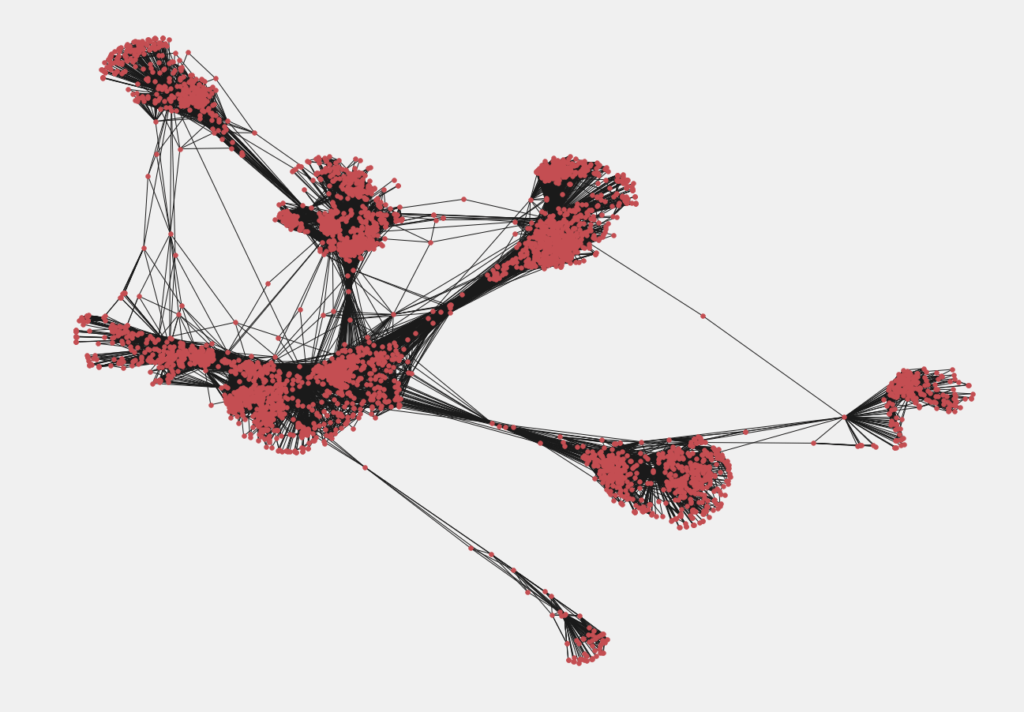 Теперь посмотрим, у каких пользователей наибольшее влияние. Алгоритм Pagerank умеет сам это делать, опираясь на количество онлайн-друзей:
Теперь посмотрим, у каких пользователей наибольшее влияние. Алгоритм Pagerank умеет сам это делать, опираясь на количество онлайн-друзей: 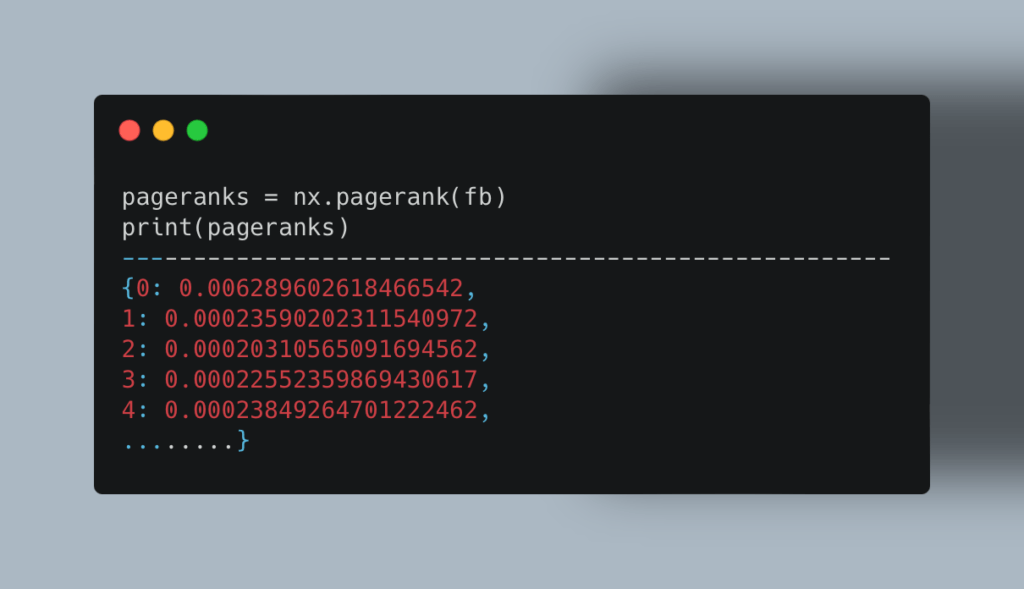 Чтобы узнать пользователей с наибольшим весом, мы используем этот код:
Чтобы узнать пользователей с наибольшим весом, мы используем этот код: 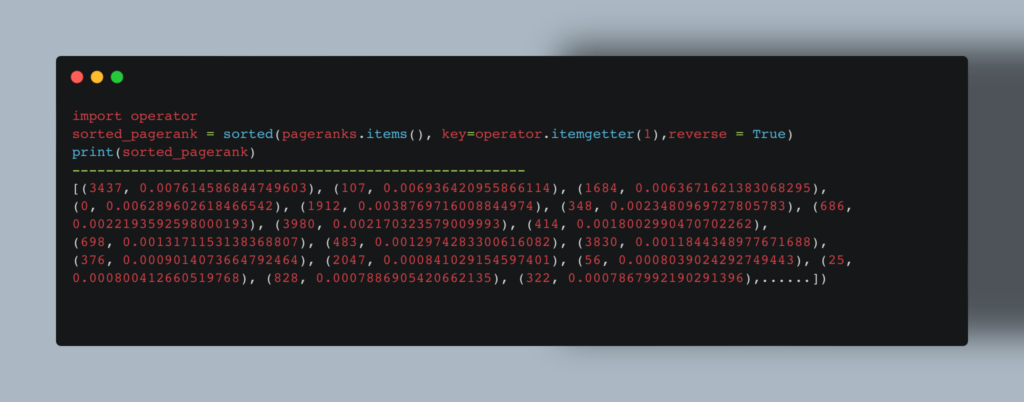 А чтобы определить «самого крутого парня», можно построить подграф:
А чтобы определить «самого крутого парня», можно построить подграф: 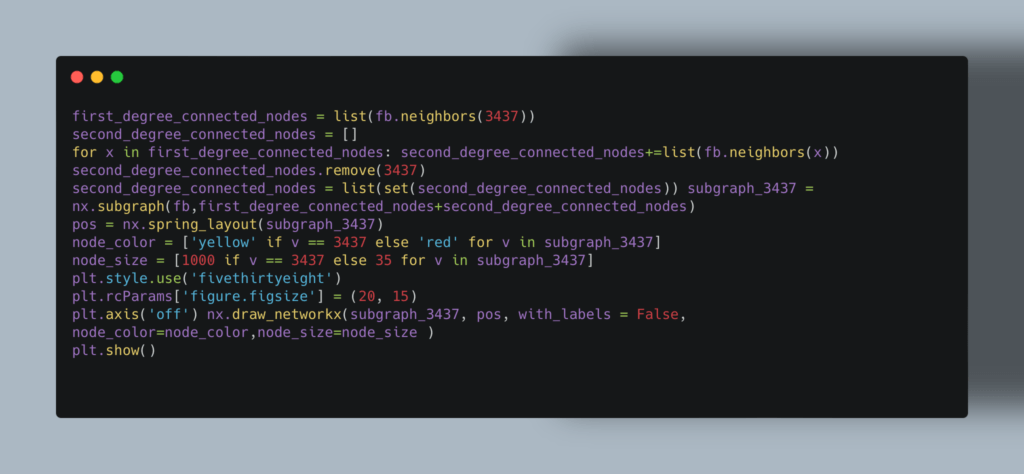
 *деятельность компании Meta Platforms Inc., которой принадлежит Инстаграм / Фейсбук, запрещена на территории РФ в части реализации данной (-ых) социальной (-ых) сети (-ей) на основании осуществления ею экстремистской деятельности
*деятельность компании Meta Platforms Inc., которой принадлежит Инстаграм / Фейсбук, запрещена на территории РФ в части реализации данной (-ых) социальной (-ых) сети (-ей) на основании осуществления ею экстремистской деятельности
5. Центральность вершин
Понятие центральности обозначает расстояние какой-либо вершины графа до его центра. Измерение центральности — это еще один способ определить влияние разных участников базы данных. В отличие от предыдущего метода, определение центральности направлено на выявление не самой главной вершины, а локальных «лидеров», которых может быть и пять, и десять. Таким образом Data Scientist может изучать распространение информации в сообществе (определять изначальное сообщение и следить за его распространением через несколько точек входа), отслеживать развитие болезней (строить карту заражений с нулевыми пациентами), контролировать телекоммуникационные и прочие сети. Существует множество метрик центральности. В нашем примере мы расскажем, как найти на графе вершины, которые чаще всего связывают между собой разрозненные группы точек. На практике это может быть перевалочный пункт на географическом маршруте, «бутылочное горлышко» в каких-либо процессах, человек-посредник, который знакомит между собой других людей. В теории графов это и называется степенью посредничества (Betweenness Centrality). Чтобы найти такие вершины, используйте следующий код: 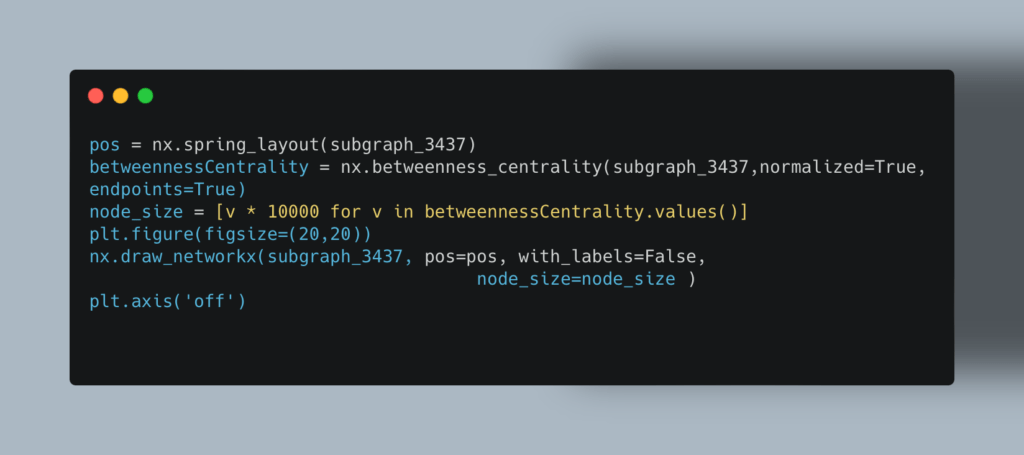
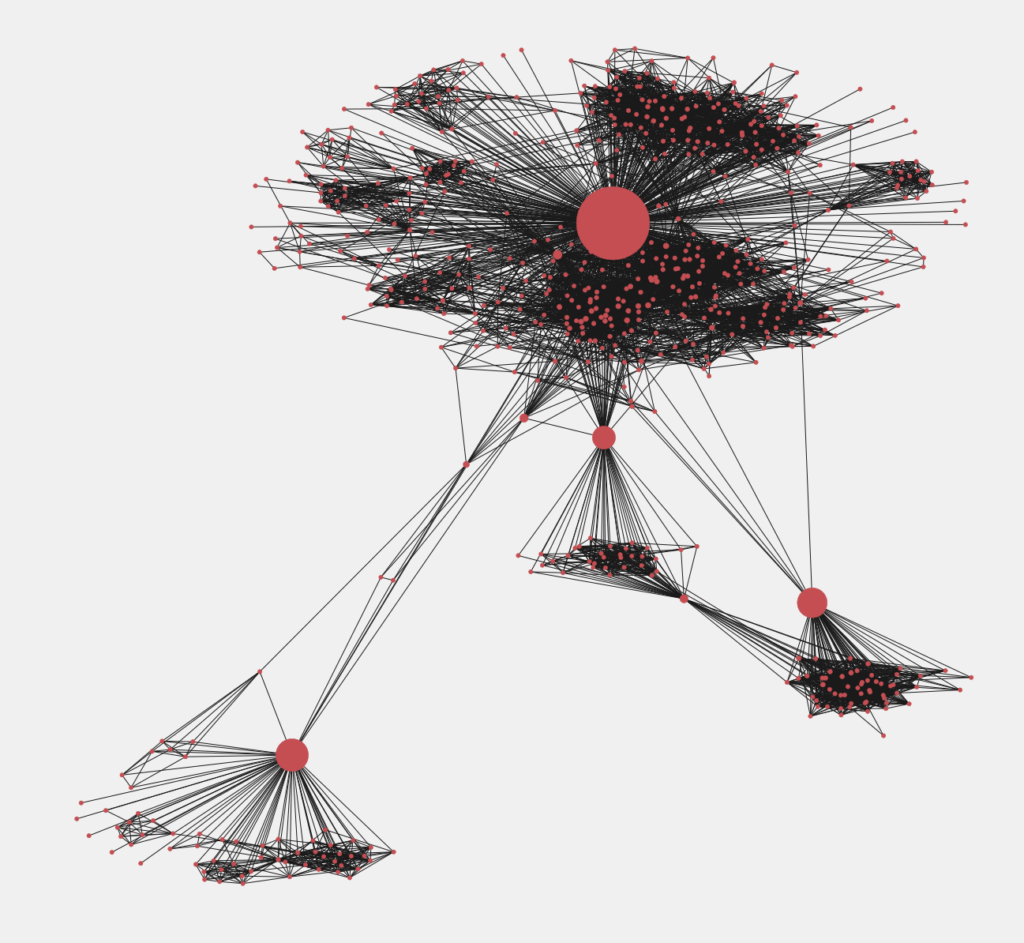 Чем больше диаметр круга, тем больше его степень посредничества. Если устранить эти узлы из системы, большой граф разобьется на несколько малых. Мы рассмотрели всего пять графов, но даже такой краткий экскурс дает представление о том, какой это мощный инструмент Data Science. Изучайте графы, используйте их в своих проектах, и вы получите множество инсайтов о том, как работает наш постоянно меняющийся мир.
Чем больше диаметр круга, тем больше его степень посредничества. Если устранить эти узлы из системы, большой граф разобьется на несколько малых. Мы рассмотрели всего пять графов, но даже такой краткий экскурс дает представление о том, какой это мощный инструмент Data Science. Изучайте графы, используйте их в своих проектах, и вы получите множество инсайтов о том, как работает наш постоянно меняющийся мир.
Data Scientist
Дата-сайентисты решают поистине амбициозные задачи. Научитесь создавать искусственный интеллект, обучать нейронные сети, менять мир и при этом хорошо зарабатывать. Программа рассчитана на новичков и плавно введет вас в Data Science.
Графы: разные виды представления графов. Алгоритмы Дейкстры и Флойда: реализация на Python. Минимальное остовное дерево
Метод обхода графа при котором в первую очередь переход делается из последней посещённой вершины (вершины хранятся в стеке). Обход в глубину получается естественным образом при рекурсивном обходе графа.
# Смежность вершин inc = < 1: [2, 8], 2: [1, 3, 8], 3: [2, 4, 8], 4: [3, 7, 9], 5: [6, 7], 6: [5], 7: [4, 5, 8], 8: [1, 2, 3, 7], 9: [4], >visited = set() # Посещена ли вершина? # Поиск в глубину - ПВГ (Depth First Search - DFS) def dfs(v): if v in visited: # Если вершина уже посещена, выходим return visited.add(v) # Посетили вершину v for i in inc[v]: # Все смежные с v вершины if not i in visited: dfs(i) start = 1 dfs(start) # start - начальная вершина обхода print(visited)
Поиск в ширину — ПВШ (Breadth First Search — BFS)
Метод обхода графа при котором в первую очередь переход делается из первой вершины, из которой мы ещё не ходили (вершины хранятся в очереди). Обход в глубину получается естественным образов при рекурсивном обходе графа.
Порядок обхода вершин при поиске в ширину

# Смежность вершин inc = < 1: [2, 8], 2: [1, 3, 8], 3: [2, 4, 8], 4: [3, 7, 9], 5: [6, 7], 6: [5], 7: [4, 5, 8], 8: [1, 2, 3, 7], 9: [4], >visited = set() # Посещена ли вершина? Q = [] # Очередь BFS = [] # Поиск в ширину - ПВШ (Breadth First Search - BFS) def bfs(v): if v in visited: # Если вершина уже посещена, выходим return visited.add(v) # Посетили вершину v BFS.append(v) # Запоминаем порядок обхода # print("v = %d" % v) for i in inc[v]: # Все смежные с v вершины if not i in visited: Q.append(i) while Q: bfs(Q.pop(0)) start = 1 bfs(start) # start - начальная вершина обхода print(BFS) # Выводится: [1, 2, 8, 3, 7, 4, 5, 9, 6]
Поиск кратчайших путей в графах (объединение разделов по Дейкстре и Флойду)
Алгоритм Дейкстры
Алгоритм Дейкстры (Dijkstra’s algorithm) — алгоритм на графах, находящий кратчайшее расстояние от одной из вершин графа до всех остальных. Алгоритм работает только для графов без рёбер отрицательного веса (без рёбер с отрицательной «длиной»).
Примеры формулировки задачи
Вариант 1. Дана сеть автомобильных дорог, соединяющих города. Некоторые дороги односторонние. Найти кратчайшие пути от заданного города до каждого другого города (если двигаться можно только по дорогам).
Вариант 2. Имеется некоторое количество авиарейсов между городами мира, для каждого известна стоимость. Стоимость перелёта из A в B может быть не равна стоимости перелёта из B в A. Найти маршрут минимальной стоимости (возможно, с пересадками) от Копенгагена до Барнаула.
Идея алгоритма Дейкстры
Алгоритм состоит и 2 повторяющихся шагов:
- Добавление новой вершины («Расти» — GROW)
- «Релаксация», т.е. пересчёт расстояний до других вершин с учётом добавленной вершины (RELAX).
Более подробное описание:
Обозначения:
Граф $G = (V,E)$, где $V$ — вершины, $E$ — рёбра.
$v_0$ — начальная вершина (от которой мы ищем кратчайшее растояние до всех остальных)
$R_i$ — известное нам расстояние от вершиеы $v_0$ до вершины $i$-ой.
$D$ — множество вершин до которых мы знаем кратчайшее расстояние от $v_0$.
Граф $G=(V,E)$, где $V$ — вершины, $E$ — рёбра.
$v_0$ — начальная вершина
$R_i$ — кратчайщее расстояние от $v_0$ до $i$-ой вершины
Инициализация алгоритма:
$D = \$ — пустое множество.
$R_ = 0$ — расстояние от $v_0$ до $v_0$ = 0.
$v = v_0$ — расти будем от вершины $v$.
Повторять (общий шаг алгоритма)
$GROW(V/D,v)$ — Добавляем вершину $v$ из множества $V/D$ в множество $D$.
$RELAX(V/D,v)$ — пробегаем достижимые из $v$ вершины до которых мы ещё не знаем кратчайшее расстояние и обновляем расстояния $R_i$ от вершины $v$.
$v$ — вершина с минимальным $R$ из множества $V/D$.
Пока удаётся расти (операция $GROW$ добавляет вершину).
Алгоритм
Каждой вершине $v$ из $V$ сопоставим значение $a[v]$ — минимальное известное расстояние от этой вершины до начальной $s$. Алгоритм работает пошагово — на каждом шаге он рассматривает одну вершину и пытается улучшить текущее расстояние до этой вершины. Работа алгоритма завершается, когда все вершины посещены, либо когда вычислены расстояния до всех вершин, достижимых из начальной.
Инициализация. Значение $a[s]$ самой начальной вершины полагается равным 0, значение остальных вершин — бесконечности (в программировании это реализуется присваиванием большого, к примеру, максимально возможного для данного типа, значения). Это отражает то, что расстояния от $s$ до других вершин пока неизвестны.
Шаг алгоритма. Если все вершины посещены, алгоритм завершается. В противном случае, из ещё не посещённых вершин выбирается вершина v, имеющая минимальное расстояние от начальной вершины $s$ и добавляется в список посещенных. Эта вершина находится, используя перебор всех непосещенных вершин. При этом суммируется расстояние от старта до одной из посещенных вершин u до непосещенной $v$. Для первого шага $s$ — единственная посещенная вершина с расстоянием от старта (то есть от себя самой), равным 0.
const MaxN = 1000; < Максимальное количество вершин >var a : array [1..MaxN] of extended; < Найденные кратчайшие расстояния >b : array [1..MaxN] of boolean; < Вычислено ли кратчайшее расстояние до вершины >p : array [1..MaxN,1..MaxN] of extended; < Матрица смежности >begin < До всех вершин расстояние - бесконечность >for i := 1 to n do a[i] := Inf; a[s] := 0.0; < И только до начальной вершины расстояние 0 >for i := 1 to n do b[i] := false; < Ни до одной вершины мы ещё не нашли кратчайшее расстояние >j := s; < Добавляемая вершина (стартовая) >repeat l := j; b[l] := True; < Добавили вершину > < Оббегаем все вершины смежные с только что добавленной >min := Inf; < Будем искать вершину с минимальным расстоянием от стартовой >for i := 1 to n do if not b[i] then begin < Если есть путь короче чем известный в i-ую вершину через l-тую, то запоминаем его >if a[i] < a[l] + p[l][i] then a[i] := a[l] + p[l][i]; < Если расстояние в эту вершину минимально, то запоминаем её как следующий кандидат на добавление >if a[i] < min then begin min := a[i]; j := i; end; end; until min = Inf; for i := 1 to n do if a[i] >= Inf then write('-1 ') < Вершины нельзя достичь из начальной >else write(a[i],' '); < Расстояние от начальной вершины = a[i] >end;
Алгоритм Флойда
Алгоритм Флойда — Уоршелла — динамический алгоритм для нахождения кратчайших расстояний между всеми вершинами взвешенного ориентированного графа. Разработан в 1962 году Робертом Флойдом и Стивеном Уоршеллом.
Пусть вершины графа пронумерованы от 1 до $n$ и введено обозначение $d_^k$ для длины кратчайшего пути от $i$ до $j$, который кроме самих вершин $i,\; j$ проходит только через вершины $1 \ldots k$. Очевидно, что $d_^$ — длина (вес) ребра $(i,\;j)$, если таковое существует (в противном случае его длина может быть обозначена как $\infty$)
Существует два варианта значения $d_^,\;k \in \mathbb (1,\;\ldots,\;n)$:
- Кратчайший путь между $i,\;j$ не проходит через вершину $k$, тогда $d_^=d_^$
- Существует более короткий путь между $i,\;j$, проходящий через $k$, тогда он сначала идёт от $i$ до $k$, а потом от $k$ до $j$. В этом случае, очевидно, $d_^=d_^ + d_^$
Таким образом, для нахождения значения функции достаточно выбрать минимум из двух обозначенных значений.
$d_^0$ — длина ребра $(i,\;j)$
Алгоритм Флойда — Уоршелла последовательно вычисляет все значения $d_^$, $\forall i,\; j$ для $k$ от 1 до $n$. Полученные значения $d_^$ являются длинами кратчайших путей между вершинами $i,\; j$.
for k := 1 to n do < k - промежуточная вершина >for i := 1 to n do < из i-ой вершины >for j := 1 to n do < в j-ую вершину >W[i][j] = min(W[i][j], W[i][k] + W[k][j]);
Алгоритм Прима
Алгоритм Прима — алгоритм построения минимального остовного дерева взвешенного связного неориентированного графа. Алгоритм впервые был открыт в 1930 году чешским математиком Войцехом Ярником, позже переоткрыт Робертом Примом в 1957 году, и, независимо от них, Э. Дейкстрой в 1959 году.
Построение начинается с дерева, включающего в себя одну (произвольную) вершину. В течение работы алгоритма дерево разрастается, пока не охватит все вершины исходного графа. На каждом шаге алгоритма к текущему дереву присоединяется самое лёгкое из рёбер, соединяющих вершину из построенного дерева, и вершину не из дерева.
Вход: Связный неориентированный граф $G(V,E)$
Выход: Множество $T$ рёбер минимального остовного дерева
Обозначения:
- $d_i$ — расстояние от $i$-й вершины до построенной части дерева
- $p_i$ — предок $i$-й вершины, то есть такая вершина $u$, что $(i,u)$ самое короткое рёбро соединяющее $i$ с вершиной из построенного дерева.
- $w(i,j)$ — вес ребра $(i,j)$
- $Q$ — приоритетная очередь вершин графа, где ключ — $d_i$
- $T$ — множество ребер минимального остовного дерева
Псевдокод:
Для каждой вершины $i \in V$: $d_i \gets \infty$, $p_i \gets nil$
$v \gets\ Extract.min(Q) $
Пока $Q$ не пуста:
Для каждой вершины $u$ смежной с $v$:
Реализация алгоритма Дейкстры на Python
Что общего у устройств GPS‑навигации с веб‑сайтами для бронирования рейсов? Оказывается, очень много! Во‑первых, обе технологии используют алгоритм Дейкстры для поиска кратчайшего пути.
В этой статье я познаколю вас с алгоритмом Дейкстры и покажу его простую реализацию на Python. После простого русского языка, на котором всё будет понятно, вы увидите, что кодирование на Python не представляет больших сложностей.
Что такое алгоритм Дейкстры?
В 1956 году у голландского программиста Эдсгера В. Дейкстры возникла практическая задача — найти самый короткий путь из Роттердама в Гронинген. Однако, он не просто сверился с картой для рассчёта расстояния, которые ему нужно было пройти, использую длину дорог. Вместо этого, Дейкстра поступил, как информатик એ : он абстрагировался от проблемы, отбросив такие мелочи, как путешествие из города А в город Б. Он сформулировал более общую проблему поиска по графу. Вот так и родился алгоритм Дейкстры એ .
Алгоритм Дейкстры — это популярный алгоритм поиска, используемый для определения кратчайшего пути между двумя узлами в графе. В исходном сценарии граф представлял Нидерланды, узлы графа представляли разные голландские города, а рёбра представляли дороги между городами. Алгоритм Дейкстры можно использовать для решения любой задачи, которая может быть представлена в виде графа. Предложения друзей в социальных сетях, маршрутизация пакетов через Интернет или поиск пути через лабиринт — все это может сделать алгоритмом Дейкстры. Но как на самом деле это работает?
Напомним, что алгоритм Дейкстры для графов, а это означает, что он может решить проблему, только если она может быть представлена в графоподобном виде. Пример, который будет здесь показан, возможно, самый интуитивно понятный — кратчайший путь между двумя городами.

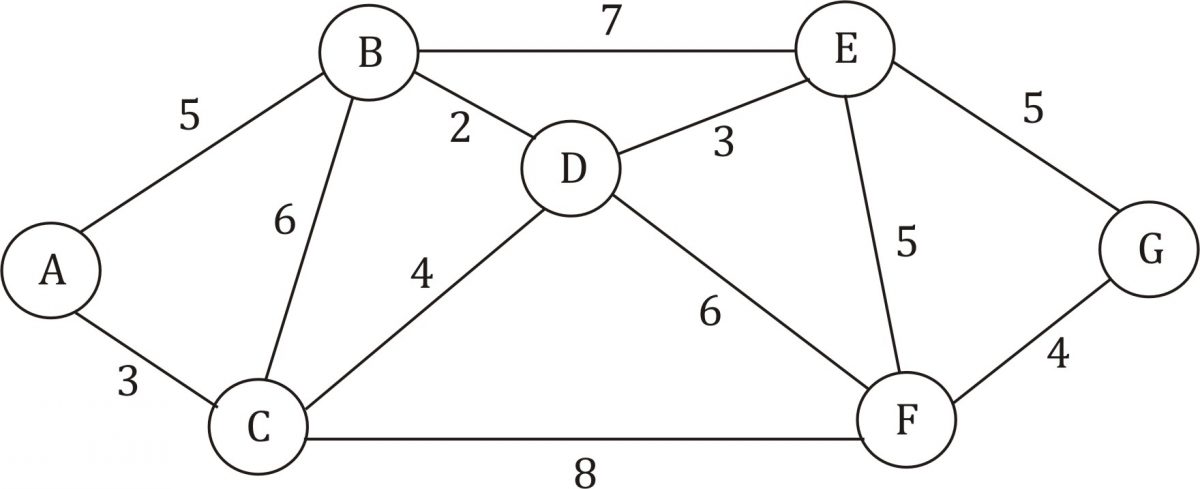
Мы будем работать с картой, показаной ниже, для поиска налучшего маршрута между двумя европейскими городами Рейкьявиком и Белградом. Для простоты представим, что все города связаны дорогами (реальный маршрут должен включать как минимум один паром).
Обратите внимание на следующее:
- Каждый город — это узел.
- Каждая дорога — это ребро.
- У каждой дороги есть своя ценность. Это может быть расстояние между городами, плата за проезд или интенсивностью движения. Как правило, мы отдаем предпочтение рёбрам с более низкими значениями. В нашем конкретном случае связанное значение определяется расстоянием между двумя городами.
Вы должны уже заметить, что добраться из Рейкьявика до Белграда напрямую невозможно. Это сделало бы наши упражнения бессмысленными. Но есть несколько путей из Рейкьявика в Белград, которые проходят через другие города:
- Reykjavik → Oslo → Berlin → Belgrade
- Reykjavik → London → Berlin → Rome → Athens → Belgrade
- Reykjavik → London → Berlin → Rome → Athens → Moscow → Belgrade
Каждый из этих путей заканчивается в Белграде, но все они имеют разные ценности. Мы можем использовать алгоритм Дейкстры, чтобы найти путь с наименьшим общим значением.
Прежде чем погрузиться в код, посмотрим на алгоритм Дейкстры с высоты птичьего полета.
Сначала инициализируем алгоритм:
- Устанавливаем Рейкьявик в качестве начального узла.
- Устанавливаем расстояния между Рейкьявиком и всеми другими городами в ∞ (бесконечность), за исключением расстояния между Рейкьявиком и самим собой, которое принимаем равным 0.
После этого, итеративно выполняем следующие шаги:
- Выбираем узел с наименьшим значением в качестве «текущего узла» и посещаем всех соседей. При посещении каждого соседа, обновляем их ориентировочное расстояние от начального узла.
- Как только мы посетим всех соседей текущего узла и обновили их расстояния, помечаем текущий узел как «visited»«посещенный»). Отметка узла как «посещенного» означает, что найдена его окончательная ценность.
- Вернемся к первому шагу и повторяем до тех пор, пока не посетим все узлы графа.

В нашем примере начинаем с отметки Рейкьявика, поскольку его значение равно 0, как «текущего узла». Далее посетим два соседних узла Рейкьявика: Лондон и Осло. В начале алгоритма их значения устанавливаются на бесконечность, но, когда мы посещаем узлы, то обновляем значение для Лондона до 4 и Осло до 5.
Затем отмечаем Рейкьявик как «посещенный». Мы знаем, что его окончательная стоимость равна нулю, и нам больше не нужно его посещать. Продолжаем со следующего узла с наименьшим значением, которым является Лондон.

Посещаем все соседние узлы Лондона, которые не помечены как «посещенные». Соседи Лондона — Рейкьявик и Берлин. Но мы игнорируем Рейкьявик, потому что мы уже были в нем. Вместо этого обновляем значение Берлина, добавляя значение ребра, соединяющего Лондон и Берлин (3), к значению Лондона (4), что дает нам значение 7.

Отмечаем Лондон как посещенный и выбираем следующий узел — Осло. Посещаем соседей Осло и обновляем их ценности. Оказывается, можно лучше добраться до Берлина через Осло (со значением 6), чем через Лондон, поэтому соответствующим образом обновляем его значение. Также обновляем текущее значение Москвы с бесконечности до 8.

Отмечаем Осло как «посещенный» и обновляем его окончательное значение до 5. Между Берлином и Москвой выбираем Берлин в качестве следующего узла, потому что его значение (6) ниже, чем у Москвы (8). Действуем так же, как и раньше: посещаем Рим и Белград и обновляем их предварительные значения, прежде чем пометить Берлин как «посещенный» и перейти к следующему городу.
Обратите внимание, что мы уже нашли путь из Рейкьявика в Белград со значением 15! Но лучший ли он?
В конце концов, это не так. Пропустим остальные шаги, а для вас это упражнение. Лучшим путем оказывается Рейкьявик → Осло → Берлин → Рим → Афины → Белград со значением 11.
Теперь, посмотрим, как это реализовать на Python.
Алгоритм Дейкстры на Python
1) Класс Graph
Сначала создадим класс Graph . Этот класс не охватывает никакой логики алгоритма Дейкстры, но сделает реализацию алгоритма более лаконичной.
Реализуем граф как словарь Python. Ключи словаря будут соответствовать городам, а его значения будут соответствовать рёбрам, где записывают расстояния до других городов на графе.
import sys class Graph(object): def __init__(self, nodes, init_graph): self.nodes = nodes self.graph = self.construct_graph(nodes, init_graph) def construct_graph(self, nodes, init_graph): ''' Этот метод обеспечивает симметричность графика. Другими словами, если существует путь от узла A к B со значением V, должен быть путь от узла B к узлу A со значением V. ''' graph = <> for node in nodes: graph[node] = <> graph.update(init_graph) for node, edges in graph.items(): for adjacent_node, value in edges.items(): if graph[adjacent_node].get(node, False) == False: graph[adjacent_node][node] = value return graph def get_nodes(self): "Возвращает узлы графа" return self.nodes def get_outgoing_edges(self, node): "Возвращает соседей узла" connections = [] for out_node in self.nodes: if self.graph[node].get(out_node, False) != False: connections.append(out_node) return connections def value(self, node1, node2): "Возвращает значение ребра между двумя узлами." return self.graph[node1][node2]
2) Алгоритм Дейкстры
Далее реализуем алгоритм Дейкстры. Начнем с определения функции.
def dijkstra_algorithm(graph, start_node):
Функция принимает два аргумента: graph и start_node . graph — это экземпляр класса Graph , который мы создали на предыдущем шаге, тогда как start_node — это узел, с которого мы начнем вычисления. Мы вызовем метод get_nodes() для инициализации списка непосещенных узлов:
unvisited_nodes = list(graph.get_nodes())
Затем создадим два словаря, shorttest_path и previous_nodes :
- Shorttest_path будет хранить наиболее известную стоимость посещения каждого города на графике, начиная с start_node. Вначале стоимость начинается с бесконечности, но мы будем обновлять значения по мере продвижения по графику.
- previous_nodes будет хранить траекторию текущего наиболее известного пути для каждого узла. Например, если нам известен лучший способ добраться до Берлина через Осло, previous_nodes[«Берлин»] вернет «Осло», а previous_nodes[«Осло»] вернет «Рейкьявик». Мы будем использовать этот словарь, чтобы найти кратчайший путь.
shortest_path = <> previous_nodes = <> # Мы будем использовать max_value для инициализации значения "бесконечности" непосещенных узлов max_value = sys.maxsize for node in unvisited_nodes: shortest_path[node] = max_value # Однако мы инициализируем значение начального узла 0 shortest_path[start_node] = 0
Теперь можно запустить алгоритм. Помните, что алгоритм Дейкстры выполняется до тех пор, пока не посетит все узлы в графе, поэтому представим это как условие выхода из цикла while .
while unvisited_nodes:
Теперь алгоритм может начать посещать узлы. Приведенный ниже блок кода сначала инструктирует алгоритм найти узел с наименьшим значением.
current_min_node = None for node in unvisited_nodes: # Iterate over the nodes if current_min_node == None: current_min_node = node elif shortest_path[node] < shortest_path[current_min_node]: current_min_node = node
После этого алгоритм посещает всех соседей узла, которые еще не посещены. Если новый путь к соседу лучше, чем текущий лучший путь, алгоритм вносит корректировки в словари shorttest_path и previous_nodes .
# Приведенный ниже блок кода извлекает соседей текущего узла и обновляет их расстояния. neighbors = graph.get_outgoing_edges(current_min_node) for neighbor in neighbors: tentative_value = shortest_path[current_min_node] + graph.value(current_min_node, neighbor) if tentative_value < shortest_path[neighbor]: shortest_path[neighbor] = tentative_value # Мы также обновляем лучший путь к текущему узлу previous_nodes[neighbor] = current_min_node
После посещения всех его соседей мы можем пометить текущий узел как «посещенный»:
unvisited_nodes.remove(current_min_node
Наконец, мы можем вернуть два словаря:
return previous_nodes, shortest_path
3) Вспомогательная функция
Наконец, нам нужно создать функцию, которая печатает результаты. Эта функция будет принимать два словаря, возвращаемые функцией dijskstra_algorithm , а также имена начального и целевого узлов. Он будет использовать два словаря, чтобы найти лучший путь и сделать его оценку.
def print_result(previous_nodes, shortest_path, start_node, target_node): path = [] node = target_node while node != start_node: path.append(node) node = previous_nodes[node] # Add the start node manually path.append(start_node) print("Найден следующий лучший маршрут <>.".format(shortest_path[target_node])) print(" -> ".join(reversed(path)))
Алгоритм в действии
Теперь посмотрим, как работает алгоритм. Dручную инициализируем узлы и их рёбра.
nodes = ["Reykjavik", "Oslo", "Moscow", "London", "Rome", "Berlin", "Belgrade", "Athens"] init_graph = <> for node in nodes: init_graph[node] = <> init_graph["Reykjavik"]["Oslo"] = 5 init_graph["Reykjavik"]["London"] = 4 init_graph["Oslo"]["Berlin"] = 1 init_graph["Oslo"]["Moscow"] = 3 init_graph["Moscow"]["Belgrade"] = 5 init_graph["Moscow"]["Athens"] = 4 init_graph["Athens"]["Belgrade"] = 1 init_graph["Rome"]["Berlin"] = 2 init_graph["Rome"]["Athens"] = 2
Будем использовать эти значения для создания объекта класса Graph .
graph = Graph(nodes, init_graph)
Когда наш граф полностью построен, можно передать его функции dijkstra_algorithm() .
previous_nodes, shortest_path = dijkstra_algorithm(graph=graph, start_node="Reykjavik")
А теперь распечатываем результаты:
print_result(previous_nodes, shortest_path, start_node="Reykjavik", target_node="Belgrade")
Вот и все! Не стесняйтесь экспериментировать с кодом. Например, можно добавить больше узлов к графу, настроить значения ребер или выбрать разные начальный и конечный города, считать города и расстояния из файла или базы данных.
Полный код приложения для проверки алгоритма Дейкстры
import sys class Graph(object): def __init__(self, nodes, init_graph): self.nodes = nodes self.graph = self.construct_graph(nodes, init_graph) def construct_graph(self, nodes, init_graph): ''' Этот метод обеспечивает симметричность графика. Другими словами, если существует путь от узла A к B со значением V, должен быть путь от узла B к узлу A со значением V. ''' graph = <> for node in nodes: graph[node] = <> graph.update(init_graph) for node, edges in graph.items(): for adjacent_node, value in edges.items(): if graph[adjacent_node].get(node, False) == False: graph[adjacent_node][node] = value return graph def get_nodes(self): "Возвращает узлы графа" return self.nodes def get_outgoing_edges(self, node): "Возвращает соседей узла" connections = [] for out_node in self.nodes: if self.graph[node].get(out_node, False) != False: connections.append(out_node) return connections def value(self, node1, node2): "Возвращает значение ребра между двумя узлами." return self.graph[node1][node2] def dijkstra_algorithm(graph, start_node): unvisited_nodes = list(graph.get_nodes()) # Мы будем использовать этот словарь, чтобы сэкономить на посещении каждого узла и обновлять его по мере продвижения по графику shortest_path = <> # Мы будем использовать этот dict, чтобы сохранить кратчайший известный путь к найденному узлу previous_nodes = <> # Мы будем использовать max_value для инициализации значения "бесконечности" непосещенных узлов max_value = sys.maxsize for node in unvisited_nodes: shortest_path[node] = max_value # Однако мы инициализируем значение начального узла 0 shortest_path[start_node] = 0 # Алгоритм выполняется до тех пор, пока мы не посетим все узлы while unvisited_nodes: # Приведенный ниже блок кода находит узел с наименьшей оценкой current_min_node = None for node in unvisited_nodes: # Iterate over the nodes if current_min_node == None: current_min_node = node elif shortest_path[node] < shortest_path[current_min_node]: current_min_node = node # Приведенный ниже блок кода извлекает соседей текущего узла и обновляет их расстояния neighbors = graph.get_outgoing_edges(current_min_node) for neighbor in neighbors: tentative_value = shortest_path[current_min_node] + graph.value(current_min_node, neighbor) if tentative_value < shortest_path[neighbor]: shortest_path[neighbor] = tentative_value # We also update the best path to the current node previous_nodes[neighbor] = current_min_node # После посещения его соседей мы отмечаем узел как "посещенный" unvisited_nodes.remove(current_min_node) return previous_nodes, shortest_path def print_result(previous_nodes, shortest_path, start_node, target_node): path = [] node = target_node while node != start_node: path.append(node) node = previous_nodes[node] # Добавить начальный узел вручную path.append(start_node) print("Найден следующий лучший маршрут с ценностью <>.".format(shortest_path[target_node])) print(" -> ".join(reversed(path))) nodes = ["Reykjavik", "Oslo", "Moscow", "London", "Rome", "Berlin", "Belgrade", "Athens"] init_graph = <> for node in nodes: init_graph[node] = <> init_graph["Reykjavik"]["Oslo"] = 5 init_graph["Reykjavik"]["London"] = 4 init_graph["Oslo"]["Berlin"] = 1 init_graph["Oslo"]["Moscow"] = 3 init_graph["Moscow"]["Belgrade"] = 5 init_graph["Moscow"]["Athens"] = 4 init_graph["Athens"]["Belgrade"] = 1 init_graph["Rome"]["Berlin"] = 2 init_graph["Rome"]["Athens"] = 2 graph = Graph(nodes, init_graph) previous_nodes, shortest_path = dijkstra_algorithm(graph=graph, start_node="Reykjavik") print_result(previous_nodes, shortest_path, start_node="Reykjavik", target_node="Belgrade")

Реализация алгоритма Дейкстры на Python , опубликовано К ВВ, лицензия — Creative Commons Attribution-NonCommercial 4.0 International.
1 нравится это
Автор К ВВ Опубликовано 21/10/2021 22/10/2021 Рубрики Follow me, Python, Рецепты
Добавить комментарий Отменить ответ
Для отправки комментария вам необходимо авторизоваться.
Ограничение ответственности
Информация на сайте предоставляется «как есть», без всяких гарантий, включая гарантию применимости в определенных целях, коммерческой пригодности и т.п. В текстах могут быть технические неточности и ошибки. Автор не может гарантировать полноты, достоверности и актуальности всей информации, не несет ответственности за последствия использования сайта третьими лицами. Автор не делает никаких заявлений, не дает никаких гарантий и оценок относительно того, что результаты, размещенные на сайте и описанные в заявлениях относительно будущих результатов, будут достигнуты. Автор не несет ответственности за убытки, возникшие у пользователей или третьих лиц в результате использования ими сайта, включая упущенную выгоду. Автор не несет ответственности за убытки, возникшие в результате действий пользователей, явно не соответствующих обычным правилам работы с информацией в сети Интернет. Пользуясь сайтом, вы принимаете и соглашаетесь со всеми нашими правилами, включая «Ограничение ответственности».