Что такое CUDA
В статье мы расскажем о том, что такое CUDA и для чего нужна эта технология. Чтобы вам было проще понять принципы работы CUDA, в начале опишем как работают разные типы процессоров.
Какие типы процессоров существуют
CPU (Central Processing Unit) — это центральный процессор. Его можно считать “сердцем” устройства: он получает вводные данные, переводит их в машиночитаемый формат и распределяет сообщения по другим частям архитектуры. Также это работает и в обратную сторону. Когда ответ на запрос готов, процессор приводит его в человекочитаемый вид и “отдает” пользователю. Например, когда вы запустили операционную систему и хотите открыть файл, то дважды кликаете по нему. Двойной клик по файлу — это запрос, который отправляется центральному процессору. Ответ на этот запрос — файл, который отображается на экране.
CPU работает по следующему алгоритму:
- Задача разбивается на несколько параллельных потоков — это значит, что каждый поток обрабатывается отдельно. В каждом отдельном потоке процессор отправляет или принимает данные в порядке очереди.
- Когда вся информация обработана, параллельные потоки снова объединяются и выстраиваются в нужном порядке.
Эти действия увеличивают скорость последовательной обработки данных.
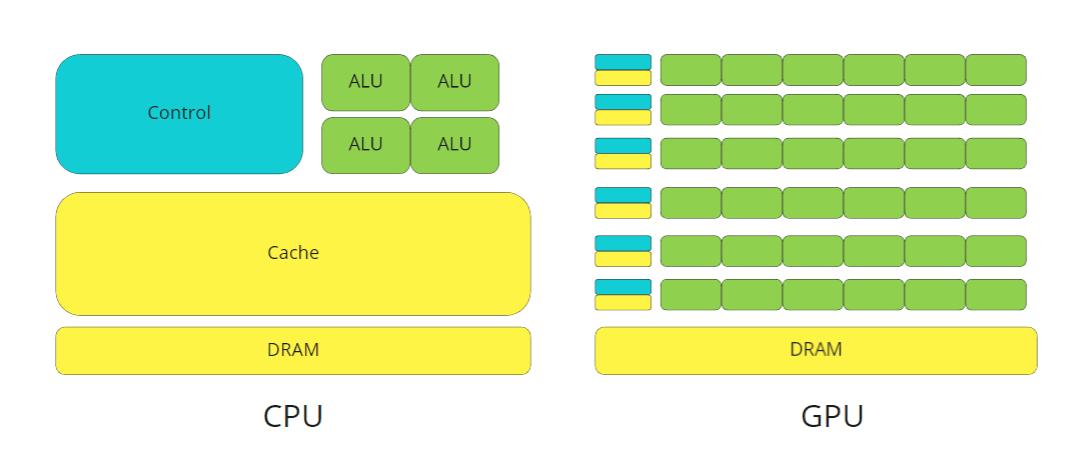
GPU (Graphics Processing Unit) — это графический процессор, который предназначен для обработки 2D и 3D-графики. Логика его работы похожа на CPU: разница в том, что GPU работает только с графическими данными.
Этот процессор размещается на видеокарте: благодаря такому устройству снижается нагрузка на основной процессор. GPU делится на несколько тысяч ядер и равномерно распределяет нагрузку между ними. По этому подходу GPU потребляет меньше энергии в сравнении с CPU.
На основе CPU и GPU были разработаны технологии, которые предназначены для разных задач. Одна из таких технологий — GPGPU.
Суть технологии GPGPU (General-Purpose Graphics Processing Units) — это возможность использовать графический процессор для задач, которые обычно выполняет центральный. GPGPU не берет на себя всю работу: он используется только как вычислительный блок.
Что такое CUDA
CUDA (Compute Unified Device Architecture или вычислительная унифицированная архитектура устройств) — это технология, которая является улучшением GPGPU. Благодаря ей разработчики могут пользоваться алгоритмами CPU, которые изначально не предназначены для графических процессоров.
Установка или настройка видеокарты
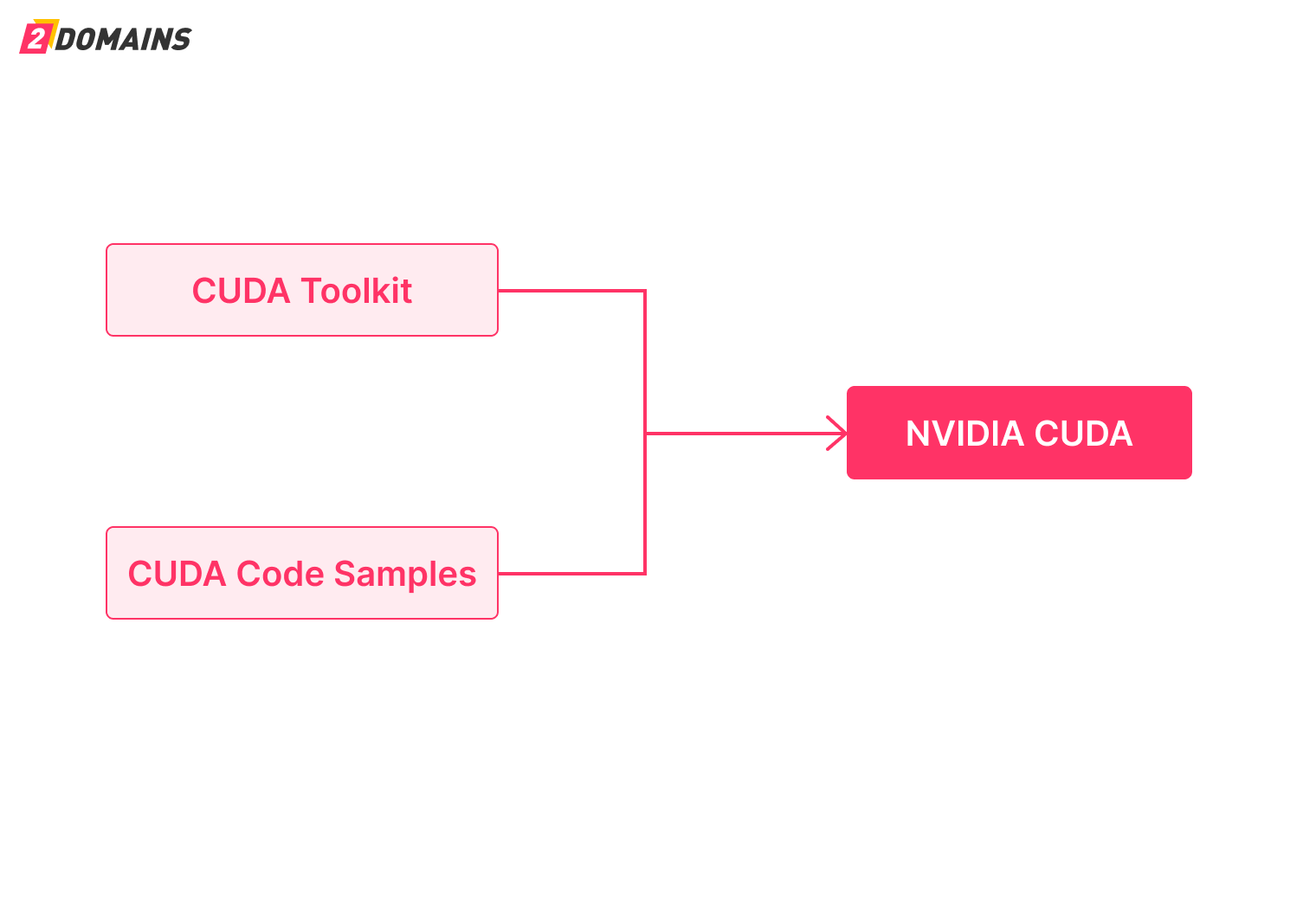
В состав CUDA входят следующие компоненты от NVIDIA:
- CUDA Toolkit — среда разработки на языке C,
- CUDA Code Samples — документ, который содержит примеры кода.
Алгоритм CUDA активно используется в разных сферах. Среди них можно выделить:
- биоинформатику,
- молекулярную биологию,
- физику,
- вычислительную математику,
- финансовую аналитику,
- искусственный интеллект и др.
Как устроена архитектура CUDA
CUDA построена на взаимодействии центрального и графического процессора. Такой принцип работы возможен благодаря шейдеру — программе, которая позволяет процессорам исполнять видеокарту.
Также для взаимодействия процессоров нужен API. Как правило, для его работы используются две популярных библиотеки NVIDIA:
- Libraries CUBLAS — для алгебраических расчетов,
- FFT — для расчетов по алгоритму Фурье: в его основе лежат ускоренные вычисления.
Корректная работа CUDA реализуется при помощи API разных уровней:
- первый уровень — Runtime. На этом этапе задача первично делится на потоки;
- второй уровень — Driver. На этом этапе данные обрабатываются из декомпозированных потоков.
Краткий алгоритм того, как работает CUDA:
- Центральный процессор выделяет часть оперативной памяти для задачи. Затем он копирует данные из своей памяти в память видеокарты.
- CPU запускает задание, а видеоадаптер его обрабатывает.
- Результат копируется из видеопамяти в память центрального процессора.
Особенности CUDA
CUDA более эффективна при вычислениях в сравнении с CPU и GPGPU. Ядра CUDA имеют более высокую производительность, чем CPU, на 1 ватт потребляемой мощности. Кроме этого существуют дополнительные преимущества:
- поддержка целочисленных и битовых операции на аппаратном уровне;
- интерфейс программирования основан на языке C с расширениями. Это помогает лучше изучить и внедрить CUDA;
- не связана с графическими API;
- адресация памяти gather и scatter работает в линейном порядке;
- 16 килобайт памяти на один мультипроцессор. Этот объем можно разделить на потоки и настроить кэш с широкой пропускной полосой;
- эффективное взаимодействие между системной памятью и видеопамятью.
Однако эта технология подходит не для всех задач, так как имеет ряд ограничений:
- минимальная ширина блока — 32 потока;
- в CUDA отсутствует поддержка рекурсии для выполняемых функций;
- закрытый исходный код программного обеспечения. Этот код принадлежит компании NVIDIA;
- CUDA можно использовать только на видеочипах от NVIDIA версии GeForce 8 и выше.
Несмотря на ограничения, которые касаются расширения функционала, CUDA помогает сэкономить время при обработке данных.
Популярные статьи
- Как указать (изменить) DNS-серверы для домена
- Я зарегистрировал домен, что дальше
- Как добавить запись типа A, AAAA, CNAME, MX, TXT, SRV для своего домена
- Что такое редирект: виды и возможности настройки
- Как создать почту со своим доменом
CUDA

CUDA представляет из себя модификацию языка C, поэтому для исходных файлов принято использовать специальное расширение — ‘cu‘ вместо ‘c’.
host — компьютер ‘в обычном понимании’, управляемый CPU.
device (устройство) — карта с GPU.
kernel (ядро) — функция, которая будет запущена в нескольких экземплярах, каждый из которых будет работать на своём ядре устройства. Для указания, что функция будет ядром, при её описании используется спецификатор
___global___
Выполнение ядра с распараллеливанием на N потоков описывается следующим образом:
MyKernel>>(параметры);
Используемое ПО
CUDA Toolkit
CUDA Toolkit предоставляет полную среду разработки на C и C++ с использованием вычислений на GPU NVIDIA. Включает компилятор для GPU, инструменты для отладки и оптимизации, математические библиотеки и документацию.
Разные версии CUDA Toolkit установлены в поддиректории внутри директории ‘/opt/shared/nvidia’. Например, версия 8.0 установлена в ‘/opt/shared/nvidia/cuda-8.0’. При этом символьная ссылка ‘/opt/shared/nvidia/cuda‘ указывает на директорию с последней установленной версией.
Для использования необходимо настроить переменные окружения следующим образом:
export PATH=$PATH:/opt/shared/nvidia/cuda/bin export LD_LIBRARY_PATH=/opt/shared/nvidia/cuda/lib64:$LD_LIBRARY_PATH
Тоже самое можно сделать с помощью утилиты module:
module load nvidia/cuda-toolkit
Если необходимо использовать какую-то другую установленную версию, пути (или параметр для ‘module’) необходимо поменять соответствующим образом.
Если необходимо использовать версию, не установленную у нас, вы можете самостоятельно установить её в свою домашнюю директорию. Это не требует повышенных прав.
CUDA Code Samples
CUDA Code Samples (предыдущее название — GPU Computing SDK) содержит примеры кода и официальные документы, призванные помочь создавать ПО, использующее NVIDIA GPU, с помощью CUDA C/C++, OpenCL или DirectCompute.
Установлено в директории вида /opt/shared/nvidia/NVIDIA_CUDA-6.0_Samples (в зависимости от версии).
Пример
Ниже приведён пример запуска программы, складывающей средствами CUDA два вектора ‘A’ и ‘B’ (т.е. два массива поэлементно) и сохраняющей сумму в вектор ‘С’.
Поскольку GPU обрабатывает данные, находящиеся в своей собственной памяти, а не в ОЗУ компьютера, требуются дополнительные действия — выделение памяти на устройстве, копирование туда исходных данных, копирование полученного результата обратно на компьютер.
Номер устройства, которое будет использоваться, программа будет получать при запуске в качестве первого параметра.
Создать файл ‘addvectors.cu‘ следующего содержания:
#include #include "cuda.h" #define N 128 int assigned_device; int used_device; // Data on the host system int HostA[N]; int HostB[N]; int HostC[N]; // Pointers to data on the device int *DeviceA; int *DeviceB; int *DeviceC; //---------------------------------------------------------- __global__ void AddVectors(int* a, int* b, int* c) < int i = threadIdx.x; c[i] = a[i] + b[i]; >//---------------------------------------------------------- int main(int argc, char** argv) < // Define the device to use: if (argc < 2) < printf ("Error: device number is absent\n"); return 100; >assigned_device=atoi(argv[1]); if ( strlen(argv[1]) > 1 or ( assigned_device == 0 and strcmp(argv[1],"0") != 0 ) ) < printf ("Error: device number is incorrect\n"); return 110; >// Select the used device: if ( cudaSetDevice(assigned_device) != cudaSuccess or cudaGetDevice( &used_device ) != cudaSuccess or used_device != assigned_device ) < printf ("Error: unable to set device %d\n", assigned_device); return 120; >printf ("Used device: %d\n", used_device); // Initialize summands: for (int i=0; i // Allocate memory on the device: cudaMalloc((void**)&DeviceA, N*sizeof(int)); cudaMalloc((void**)&DeviceB, N*sizeof(int)); cudaMalloc((void**)&DeviceC, N*sizeof(int)); // Copy summands from host to device: cudaMemcpy(DeviceA, HostA, N*sizeof(int), cudaMemcpyHostToDevice); cudaMemcpy(DeviceB, HostB, N*sizeof(int), cudaMemcpyHostToDevice); // Execute kernel: AddVectors>>(DeviceA, DeviceB, DeviceC); // Copy result from device to host: cudaMemcpy(HostC, DeviceC, N*sizeof(int), cudaMemcpyDeviceToHost); // Show result: for (int i=0; i cudaFree(DeviceA); cudaFree(DeviceB); cudaFree(DeviceC); >
Для установки переменных окружения выполнить:
module load nvidia/cuda-toolkit
Для компилирования используется утилита nvcc. Необходимо выполнить:
nvcc -arch=compute_20 addvectors.cu -o addvectors
Либо можно использовать ‘makefile’ следующего содержания
addvectors : addvectors.cu nvcc -arch=compute_20 addvectors.cu -o $@
В результате должен быть создан исполняемый файл ‘addvectors’
Для взаимодействия с планировщиком PBS создать файл ‘submit.sh‘ следующего содержания:
#!/bin/sh #PBS -q teslaq #PBS -l walltime=0:01:00 #PBS -l select=1:ngpus=1:ncpus=4:mem=32gb cd $PBS_O_WORKDIR vnodes=$(qstat -f $PBS_JOBID|grep exec_vnode|sed -e 's/ *//') if [ $( echo $vnodes|grep -c '+') != 0 ] ; then echo "Error: several vnodes are provided." exit 100 fi gpu_nbr=$(echo $vnodes|sed 's/.*\[//'|sed 's/\].*//') echo "GPU number from vnodes = $gpu_nbr" echo export PATH=$PATH:/opt/shared/nvidia/cuda/bin export LD_LIBRARY_PATH=/opt/shared/nvidia/cuda/lib64:$LD_LIBRARY_PATH ./addvectors $gpu_nbr
Поставить задачу в очередь:
qsub submit.sh
После завершения в файле стандартного вывода будет получено примерно следующее:
GPU number from vnodes = 0 Used device: 0 0 + 0 = 0 2 + 3 = 5 4 + 6 = 10 6 + 9 = 15 8 + 12 = 20 . 246 + 369 = 615 248 + 372 = 620 250 + 375 = 625 252 + 378 = 630 254 + 381 = 635
MPI + CUDA
Для использования CUDA совместно с MPI необходимо использовать два компилятора — nvcc для кода CUDA и mpicc (mpiCC/mpicxx/…) для остального. Поэтому исходный текст должен быть разбит на несколько файлов таким образом, чтобы разделить CUDA и MPI код. Каждый файл компилируется соответствующим компилятором, но не до исполняемого файла, а до объектного. Затем все полученные объектные файлы объединяются в один исполняемый.
Кроме того, каждый процесс MPI должен знать, с каким именно GPU, присутствующем на сервере, он должен работать. Данная информация не предоставляется явно средствами PBS, MPI или CUDA и программа должна выяснять её самостоятельно.
Команда mpirun должна получить корректное значение переменной окружения LD_LIBRARY_PATH. Это необходимо, чтобы обеспечить установку этой переменной на всех используемых узлах. Без этого программа не найдёт библиотеки CUDA и завершится аварийно. При использовании OpenMPI это делается при помощи параметра ‘-x‘, для Intel MPI — параметром ‘-genvlist‘.
Ниже приведён рабочий пример, в котором каждый MPI-процесс работает со своим GPU.
Выбрать необходимую реализацию MPI:
mpi-selector --set openmpi_gcc-1.4.4
Переподключить SSH-соединение.
Установить переменные окружения для работы компилятора nvcc:
module load nvidia/cuda-toolkit
Создать файл ‘cuda_part.cu‘ следующего содержания:
#include #include "cuda.h" #define N 4 int used_device; // Data on the host system int HostA[N]; int HostB[N]; int HostC[N]; // Pointers to data on the device int *DeviceA; int *DeviceB; int *DeviceC; //---------------------------------------------------------- __global__ void AddVectors(int* a, int* b, int* c) < int i = threadIdx.x; c[i] = a[i] + b[i]; >//---------------------------------------------------------- extern "C" void exec_cuda(int mpi_rank, int assigned_device) < // Select the used device: if ( cudaSetDevice(assigned_device) != cudaSuccess or cudaGetDevice( &used_device ) != cudaSuccess or used_device != assigned_device ) < printf ("Error: unable to set device %d\n", assigned_device); return; >// Initialize summands: for (int i=0; i // Allocate memory on the device: cudaMalloc((void**)&DeviceA, N*sizeof(int)); cudaMalloc((void**)&DeviceB, N*sizeof(int)); cudaMalloc((void**)&DeviceC, N*sizeof(int)); // Copy summands from host to device: cudaMemcpy(DeviceA, HostA, N*sizeof(int), cudaMemcpyHostToDevice); cudaMemcpy(DeviceB, HostB, N*sizeof(int), cudaMemcpyHostToDevice); // Execute kernel: AddVectors>>(DeviceA, DeviceB, DeviceC); // Copy result from device to host: cudaMemcpy(HostC, DeviceC, N*sizeof(int), cudaMemcpyDeviceToHost); // Show result: for (int i=0; i cudaFree(DeviceA); cudaFree(DeviceB); cudaFree(DeviceC); >
Основное отличие от примера, приведённого выше для CUDA (без MPI) — вместо стандартной функции ‘main’ используется функция с другим именем и параметрами, описанная как ‘extern’.
Создать файл ‘mpi_part.c‘:
#include #include #include #include extern void exec_cuda(int, int); int *gpu_by_rank; int *vnode_is_used; //------------------------------------------------------------ int define_gpu (int rank, char *host, int argc, char** argv) < int i, gpu = -1; // 'argv' looks like the following: // ./mpi_cuda sl002 0 sl002 1 sl002 2 sl003 0 sl003 1 sl003 2 for (i=1; ireturn gpu; > //------------------------------------------------------------ int main(int argc, char** argv) < int size, rank, i, k, gpu; char host[32]; MPI_Status status; MPI_Init(&argc,&argv); MPI_Comm_size(MPI_COMM_WORLD,&size); MPI_Comm_rank(MPI_COMM_WORLD,&rank); // Validate arguments: if ( size != (argc-1)/2 ) < MPI_Finalize(); printf ("Error: amount of GPUs do not match the MPI size!\n"); return 100; >// Define correspondence between ranks and vnodes gpu: if ( rank == 0 ) < gpu_by_rank = (int *)malloc(size*sizeof(int)); vnode_is_used = (int *)malloc(size*sizeof(int)); for ( i=0; ifor ( i=1; i gethostname(host,32); gpu=define_gpu(0,host, argc, argv); free(gpu_by_rank); free(vnode_is_used); > else < gethostname(host,32); MPI_Send(host,32,MPI_CHAR,0,0,MPI_COMM_WORLD); MPI_Recv(&gpu,1,MPI_INT,0,0,MPI_COMM_WORLD, &status); >printf("I'm number %d from %d and I run on host %s, gpu %d.\n",rank,size,host,gpu); exec_cuda(rank,gpu); MPI_Finalize(); return 0; >
Скомпилировать до объектных файлов (*.o):
nvcc -arch=compute_20 -c cuda_part.cu mpicc -c mpi_part.c
и затем собрать в исполняемый ‘mpi_cuda‘:
mpicc mpi_part.o cuda_part.o -lm -lcudart -L/opt/shared/nvidia/cuda/lib64 -I/opt/shared/nvidia/cuda/include -o mpi_cuda
Либо можно использовать ‘makefile‘ следующего содержания:
mpi_cuda : mpi_part.o cuda_part.o mpicc mpi_part.o cuda_part.o -lm -lcudart -L/opt/shared/nvidia/cuda/lib64 -I/opt/shared/nvidia/cuda/include -o mpi_cuda cuda_part.o : cuda_part.cu nvcc -arch=compute_20 -c cuda_part.cu mpi_part.o : mpi_part.c mpicc -c mpi_part.c
Создать файл ‘submit.sh‘:
#!/bin/sh #PBS -q teslaq #PBS -l walltime=0:01:00 #PBS -l select=2:ngpus=3:ncpus=3:mpiprocs=3:mem=32gb,place=scatter cd $PBS_O_WORKDIR MPI_NP=$(wc -l $PBS_NODEFILE | awk '< print $1 >') vnodes=$(qstat -f $PBS_JOBID|tr -d '\n'' ''\t'|sed 's/Hold_Types.*//'|sed 's/.*exec_vnode=//'|tr -d \(\)|tr + '\n'|sed 's/:.*//'|sort) echo "My vnodes:" for vnode in $vnodes ; do node=$(echo $vnode|sed 's/\[.*//') gpu=$(echo $vnode|sed 's/.*\[//'|sed 's/\]//') echo " $vnode = Node $node, GPU $gpu" done echo ## Replace all '[' and ']' by spaces before passing to program: vnodes=$(echo $vnodes|sed 's/\[/ /g'|sed 's/\]/ /g') export LD_LIBRARY_PATH=/opt/shared/nvidia/cuda/lib64:$LD_LIBRARY_PATH mpirun -x LD_LIBRARY_PATH -hostfile $PBS_NODEFILE -np $MPI_NP ./mpi_cuda $vnodes
Передать планировщику:
qsub submit.sh
После завершения файл стандартного вывода будет содержать примерно следующее:
My vnodes: sl002[0] = Node sl002, GPU 0 sl002[1] = Node sl002, GPU 1 sl002[2] = Node sl002, GPU 2 sl003[0] = Node sl003, GPU 0 sl003[1] = Node sl003, GPU 1 sl003[2] = Node sl003, GPU 2 I'm number 1 from 6 and I run on host sl002, gpu 0. I'm number 2 from 6 and I run on host sl002, gpu 1. I'm number 3 from 6 and I run on host sl003, gpu 0. I'm number 0 from 6 and I run on host sl002, gpu 2. I'm number 4 from 6 and I run on host sl003, gpu 1. I'm number 5 from 6 and I run on host sl003, gpu 2. 0 + 0 = 0 2 + 3 = 5 4 + 6 = 10 6 + 9 = 15 400 + 600 = 1000 402 + 603 = 1005 404 + 606 = 1010 406 + 609 = 1015 600 + 900 = 1500 602 + 903 = 1505 604 + 906 = 1510 606 + 909 = 1515 200 + 300 = 500 202 + 303 = 505 204 + 306 = 510 206 + 309 = 515 800 + 1200 = 2000 802 + 1203 = 2005 804 + 1206 = 2010 806 + 1209 = 2015 1000 + 1500 = 2500 1002 + 1503 = 2505 1004 + 1506 = 2510 1006 + 1509 = 2515
Что такое CUDA
В статье мы подробно рассмотрим CUDA — что это за технология, как работает и в каких областях её можно использовать.
Что такое CUDA
CUDA (англ. Compute Unified Device Architecture) — это технология на базе программно-аппаратной архитектуры, которая позволяет повысить производительность параллельных вычислений. Параллельные вычисления — это вычисления, при которых процесс разработки программного обеспечения делится на потоки. Потоки обрабатываются параллельно и взаимодействуют между собой в процессе обработки. Это возможно благодаря процессорам компании NVIDIA, на которых построена работа CUDA. В их основе лежит технология GPGPU.
Прежде чем разобраться, в чём особенность этой технологии, посмотрим, какие бывают типы процессоров и как они работают.
Основные типы процессоров
CPU (англ. Central Processing Unit) — это центральный процессор, который ориентирован на обработку данных в максимально короткие сроки. Работает по следующему принципу: разбивает одну задачу на несколько потоков, каждый из которых обрабатывается отдельно. Затем эти потоки вновь объединяются и выстраиваются в нужном порядке. Такой подход позволяет увеличить скорость последовательной обработки задач. Подробнее читайте в статье Что такое процессор CPU.
GPU (англ. Graphics Processing Unit) — это специальный графический процессор, который заточен на обработку 2D или 3D-графики. Он размещается на видеокарте, что позволяет автоматически освободить основной процессор от лишней нагрузки при обработке данных. GPU состоит из нескольких тысяч ядер, которые в совокупности потребляют небольшое количество энергии. CUDA ядра «выигрывают» у CPU по производительности на 1 ватт потребляемой мощности.
На базе этих основных процессоров были разработаны различные специализированные инструменты. Например, технология GPGPU.
GPGPU (англ. General-purpose computing on graphics processing units) — это технология, которая позволяет использовать графический процессор GPU в операциях, которые обычно выполняет центральный процессор CPU. Например, в математических вычислениях. С помощью GPGPU можно использовать видеокарту для выполнения неграфических вычислений. При этом графический процессор будет работать не вместо центрального, а в качестве вычислительного блока.
CUDA является улучшенной вариацией GPGPU. Она позволяет работать на специальном диалекте — это значит, что программисты могут использовать алгоритмы, предназначенные для графических процессоров при обработке неспецифических задач. С помощью CUDA можно значимо ускорить процессы обработки. Например, можно сократить время ожидания конвертации видео до 20 раз, не задействуя основной процессор.
В каких областях можно использовать CUDA:
- вычислительная математика,
- физика,
- молекулярная биология,
- биоинформатика,
- финансовая аналитика,
- анализ баз данных,
- искусственный интеллект и другие.
В последнее время технология высокоскоростной обработки становится ближе к рядовому пользователю. Например, уже существуют плагины для Photoshop, которые используют мощности GPU. С другими программами и проектами можно познакомиться на официальном сайте.
История возникновения
Первые попытки использовать графические ускорители для нецелевых вычислений предпринимались еще с конца 90-х годов. Однако масштабная работа в этом направлении началась немного позже. В начале 2000-х годов два основных лидера в мире процессоров — компании AMD и Intel – решили побороться за производство самого мощного «мозга» компьютера. В период жесткой конкуренции производителям удалось значимо поднять планку обработки процессорами тактовых частот (например, в промежуток между 2001-м и 2003-м годом частоты подросли с 1,5 до 3 ГГц).
Вместе с этим разработчики из Стенфордского университета поставили перед собой конкретную цель — создать графический адаптер, который позволит проводить неграфические вычисления. Так появился Brook — специализированный язык программирования и реализации. Затем были запущены аналогичные проекты: библиотека Accelerator, Brahma, GPU++ и другие.
Немногим позже к исследовательской работе присоединился лидер индустрии NVIDIA. Компания решила разработать собственные программные платформы и видеокарты для неграфических вычислений. Так появилась CUDA.

NVIDIA СUDA toolkit
Архитектура
Архитектура CUDA базируется на взаимодействии между CPU и GPU процессорами. Это возможно благодаря работе шейдера — программы для исполнения видеокарты процессорами.
Взаимодействие происходит с помощью разноуровневых API. API на первом уровне — Runtime. Он позволяет сделать первичную разбивку задачи на потоки. Затем эти декомпозированные потоки переходят на второй уровень API — Driver. При этом работу API поддерживают библиотеки NVIDIA — Libraries CUBLAS (для алгебраических расчётов) и FFT (расчёт по алгоритму ускоренного вычисления Фурье).
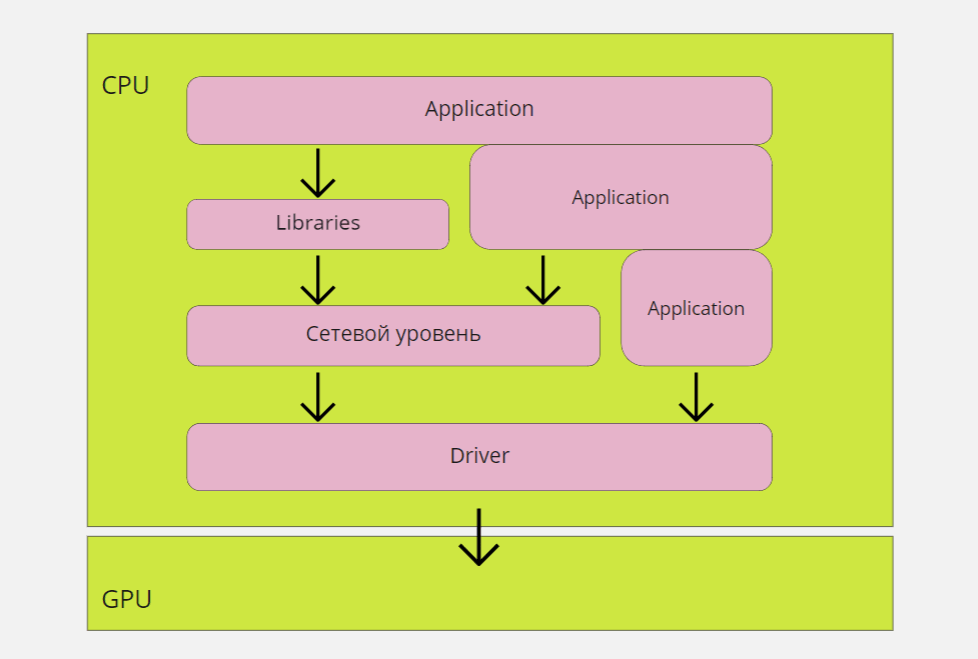
Если говорить максимально упрощенно, то работа алгоритма CUDA выглядит следующим образом:
- Центральный процессор выделяет нужное количество памяти и отправляет её графическому процессору.
- Центральный процессор запускает ядро и также «делится» им с графическим.
- Графический процессор выполняет операции используя память и мощности ядра.
- После обработки данных центральный процессор принимает результаты.
Взаимодействие CPU и GPU
Характеристики и среда разработки CUDA:
- компилятор nvcc,
- отладчик gdb для GPU,
- профилировщик,
- библиотеки численного анализа FFT и BLAS,
- поддержка 32- и 64-битных операционных систем: Linux, macOS, Windows XP, Vista и других,
- поддержка языков программирования: Java, Python, C++, Си, Фортран и других.
Недостатки и преимущества CUDA
CUDA имеет преимущества не только перед вычислениями на CPU, но и перед более ранними технологиями вычисления с помощью GPGPU. Рассмотрим, в чём они заключаются.
Преимущества
- Простой в применении интерфейс программирования на С,
- поддержка CUDA: битовые и целочисленные операции проводятся на аппаратном уровне, не требуя переноса алгоритмов в удобный для концепции графического конвейера вид,
- не ограничена графическими API,
- адресация памяти gather и scatter в линейном порядке,
- эффективный взаимообмен между видеопамятью и системной памятью,
- память размером 16 Кб на мультипроцессор: её можно разделить на потоки и настроить кеш с широкой полосой пропускания.
Как любая технология, CUDA имеет нюансы применения и ограничения.
Ограничения
- CUDA имеет архитектуру с закрытым исходным кодом, которым владеет NVIDIA,
- архитектура работает только на видеочипах компании NVIDIA, начиная с версии GeForce 8,
- для выполняемых функций нет поддержки рекурсии,
- 32 потока — минимально возможная ширина блока.
Несмотря на все достоинства этой технологии, нельзя сказать, что параллельные вычисления полностью заменят классические. Современный центральный процессор заточен под обработку целочисленных данных и данных с плавающей запятой в максимально короткие сроки. В то же время архитектура видеокарты позволяет быстро и без проблем «распараллелить» обработку данных. Поэтому CUDA — это скорее эффективный и необходимый инструментарий для конкретных областей применения.
Теперь вы знаете, что такое и для чего нужна CUDA, а также как устроена архитектура этой технологии.
Помогла ли вам статья?
Спасибо за оценку. Рады помочь ��
NVIDIA cuda toolkit — что это и для чего эта программа .
я скачал программу: CUDA 5.0. но не пойму для чего она, повышает ли она производительность в играх.
Лучший ответ
CUDA™ Toolkit – это среда разработки для GPU с поддержкой CUDA, основанная на языке C.
Драйвер CUDA взаимодействует с графическими драйверами OpenGL и DirectX.
Технология NVIDIA CUDA поддерживается графическими процессорами ускорителей GeForce (начиная с восьмого поколения – GeForce 8 Series, GeForce 9 Series, GeForce 200 Series), Nvidia Quadro и Tesla.
Источник: NVIDIA CUDA Toolkit — набор инструментов для разработчиков, позволяющих возложить некоторые вычислительные задачи на GPU.
Остальные ответы
Похожие вопросы