Сводные таблицы в Python

Сводные таблицы (pivot table) – невероятно удобный инструмент для анализа табличных данных. Эта статья рассказывает о том, как использовать элегантную функциональность сводных таблиц, реализованную в библиотеке Pandas, для исследования и анализа данных.
Возможность создавать сводные таблицы присутствует в электронных таблицах и других программах, оперирующих табличными данными. Сводная таблица принимает на входе данные из отдельных столбцов и группирует их, формируя двумерную таблицу, реализующую многомерное обобщение данных. Чтобы ощутить разницу между сводной таблицей и операцией GroupBy, можно представить себе сводную таблицу, как многомерный вариант агрегации посредством GroupBy. То есть данные разделяются, преобразуются и объединяются, но при этом разделение и объединение осуществляются не по одномерному индексу, а по двумерной сетке.
Преимущества сводных таблиц
Для примеров в этом разделе, мы будем использовать набор данных о пассажирах «Титаника», доступный посредством библиотеки seaborn.
import numpy as np import pandas as pd import seaborn as sns titanic = sns.load_dataset('titanic')
titanic.head()
| survived | pclass | sex | age | sibsp | parch | fare | embarked | class | who | adult_male | deck | embark_town | alive | alone | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 0 | 3 | male | 22 | 1 | 0 | 7.2500 | S | Third | man | True | NaN | Southampton | no | False |
| 1 | 1 | 1 | female | 38 | 1 | 0 | 71.2833 | C | First | woman | False | C | Cherbourg | yes | False |
| 2 | 1 | 3 | female | 26 | 0 | 0 | 7.9250 | S | Third | woman | False | NaN | Southampton | yes | True |
| 3 | 1 | 1 | female | 35 | 1 | 0 | 53.1000 | S | First | woman | False | C | Southampton | yes | False |
| 4 | 0 | 3 | male | 35 | 0 | 0 | 8.0500 | S | Third | man | True | NaN | Southampton | no | True |
Этот набор данных содержит обширную информацию о каждом пассажире того злополучного рейса, в том числе пол, возраст, класс, стоимость билета и многое другое.
Реализация сводной таблицы вручную
Чтобы изучить эти данные, возможно, потребуется сгруппировать пассажиров по таким параметрам, как пол, выжил или нет, или на основании какой-либо комбинации параметров. Если вы прочитали предыдущий раздел, у вас может появиться искушение применить к этим данным операцию GroupBy. Например, давайте вычислим процент выживших для каждого пола:
titanic.groupby('sex')[['survived']].mean()
| survived | |
|---|---|
| sex | |
| female | 0.742038 |
| male | 0.188908 |
Сразу же можно сделать вывод о том, что из каждых четырех женщин, находившихся на борту, выжили три, в то время как из каждых пяти мужчин выжил только один!
Это интересная информация, но мы можем пойти дальше и выяснить взаимосвязь между показателем выживаемости и двумя другими параметрами, такими как пол и, например, класс. Используя терминологию GroupBy, мы могли бы сформулировать последовательность наших действий следующим образом: группируем по (group by) классу и полу, отбираем (select) выживших, применяем (apply) агрегацию по среднему, объединяем (combine) результирующие группы и преобразуем (unstack) иерархический индекс, чтобы раскрыть скрытую многомерность. Выразим это в коде:
titanic.groupby(['sex', 'class'])['survived'].aggregate('mean').unstack()
| class | First | Second | Third |
|---|---|---|---|
| sex | |||
| female | 0.968085 | 0.921053 | 0.500000 |
| male | 0.368852 | 0.157407 | 0.135447 |
Теперь мы имеем четкое представление о том, как пол и класс повлияли на выживаемость, но код становится немного громоздким. Хотя каждый шаг этой последовательности вполне понятен в свете рассмотренных выше инструментов, тем не менее длинную строку кода достаточно трудно читать и использовать. Подобные операции широко распространены, в связи с чем библиотека Pandas имеет в своем составе специальный метод pivot_table, лаконично реализующий данный тип многомерной агрегации.
Синтаксис сводных таблиц
Ниже представлен эквивалент рассмотренной выше операции, реализованный с помощью метода pivot_table объекта DataFrame:
titanic.pivot_table('survived', index='sex', columns='class')
Это выражение намного легче читается, по сравнению с эквивалентным выражением для GroupBy, и дает тот же результат. Как можно было ожидать, в случае трансатлантического рейса начала 20-го века, больше шансов выжить было у женщин и пассажиров более высоких классов. Женщины из первого класса спаслись почти все (привет, Кейт!), в то время как из каждых десяти мужчин с билетами третьего класса выжил только один (прости, Лео!).
Многоуровневые сводные таблицы
Точно так же, как при использовании GroupBy, группирование в сводной таблице может иметь несколько уровней и задаваться посредством различных параметров. Например, в качестве третьего измерения нас может заинтересовать возраст. Мы разделим возраст на интервалы, с помощью функции pd.cut:
age = pd.cut(titanic['age'], [0, 18, 80]) titanic.pivot_table('survived', ['sex', age], 'class')
| class | First | Second | Third | |
|---|---|---|---|---|
| sex | age | |||
| female | (0, 18] | 0.909091 | 1.000000 | 0.511628 |
| (18, 80] | 0.972973 | 0.900000 | 0.423729 | |
| male | (0, 18] | 0.800000 | 0.600000 | 0.215686 |
| (18, 80] | 0.375000 | 0.071429 | 0.133663 |
Мы можем сделать то же самое со столбцами. Давайте добавим информацию о стоимости билета, используя функцию pd.qcut, чтобы автоматически рассчитать квантили:
fare = pd.qcut(titanic['fare'], 2) titanic.pivot_table('survived', ['sex', age], [fare, 'class'])
| fare | (14.454, 512.329] | [0, 14.454] | |||||
|---|---|---|---|---|---|---|---|
| class | First | Second | Third | First | Second | Third | |
| sex | age | ||||||
| female | (0, 18] | 0.909091 | 1.000000 | 0.318182 | NaN | 1.000000 | 0.714286 |
| (18, 80] | 0.972973 | 0.914286 | 0.391304 | NaN | 0.880000 | 0.444444 | |
| male | (0, 18] | 0.800000 | 0.818182 | 0.178571 | NaN | 0.000000 | 0.260870 |
| (18, 80] | 0.391304 | 0.030303 | 0.192308 | 0 | 0.098039 | 0.125000 | |
В результате получим четырехмерную агрегацию, демонстрирующую взаимосвязь между соответствующими величинами.
Дополнительные параметры сводной таблицы
Полная сигнатура вызова метода pivot_table объекта DataFrame является следующей:
DataFrame.pivot_table(values=None, index=None, columns=None, aggfunc='mean', fill_value=None, margins=False, dropna=True)
Выше мы рассмотрели три первых параметра. Теперь давайте обсудим остальные. Параметры fill_value и dropna задают способ обработки отсутствующих данных. Их использование не вызывает затруднений, поэтому мы не будем приводить примеры.
Параметр aggfunc задает тип агрегации. По умолчанию его значение равно ‘mean‘. Как и в случае GroupBy, тип агрегации можно задать либо с помощью предопределенной строки (например, ‘sum’, ‘mean’, ‘count’, ‘min’, ‘max’ и др.), либо посредством функции, реализующей агрегацию (например, np.sum(), min(), sum() и др.). Кроме того, этот параметр может быть задан в виде словаря, отображающего столбцы на любые из желаемых значений, перечисленных выше:
titanic.pivot_table(index='sex', columns='class', aggfunc=)
| fare | survived | |||||
|---|---|---|---|---|---|---|
| class | First | Second | Third | First | Second | Third |
| sex | ||||||
| female | 106.125798 | 21.970121 | 16.118810 | 91 | 70 | 72 |
| male | 67.226127 | 19.741782 | 12.661633 | 45 | 17 | 47 |
Обратите внимание, в данном случае мы не задали параметр values, потому что он задается автоматически, когда параметр aggfunc представлен в виде отображения.
Иногда требуется вычислить обобщенные значения по каждой группе. Это можно сделать с помощью параметра margins:
titanic.pivot_table('survived', index='sex', columns='class', margins=True)
| class | First | Second | Third | All |
|---|---|---|---|---|
| sex | ||||
| female | 0.968085 | 0.921053 | 0.500000 | 0.742038 |
| male | 0.368852 | 0.157407 | 0.135447 | 0.188908 |
| All | 0.629630 | 0.472826 | 0.242363 | 0.383838 |
Представленный выше код автоматически дает нам процент выживших в зависимости от пола без учета класса, в зависимости от класса без учета пола, а также общий процент выживших, составляющий 38%.
Пример. Данные о рождаемости
В качестве более интересного примера давайте рассмотрим свободно доступные данные о рождаемости в США, предоставленные Центрами по контролю и профилактике заболеваний (Centers for Disease Control and Prevention, CDC). Данные можно загрузить по ссылке: https://raw.githubusercontent.com/jakevdp/data-CDCbirths/master/births.csv.
Этот набор данных был детально проанализирован группой Эндрю Джелмана (Andrew Gelman). Подробности можно найти в этой статье.
# shell command to download the data: !curl -O https://raw.githubusercontent.com/jakevdp/data-CDCbirths/master/births.csv births = pd.read_csv('births.csv')
% Total % Received % Xferd Average Speed Time Time Time Current Dload Upload Total Spent Left Speed 100 258k 100 258k 0 0 1935k 0 --:--:-- --:--:-- --:--:-- 1943k
--------------------------------------------------------------------------- NameError Traceback (most recent call last) in () 2 get_ipython().system(u'curl -O https://raw.githubusercontent.com/jakevdp/data-CDCbirths/master/births.csv'>) 3 ----> 4 births = pd.read_csv('births.csv') NameError: name 'pd' is not defined
Набор данных имеет достаточно простую структуру: количество новорожденных сгруппировано по дате и полу.
births.head()
| year | month | day | gender | births | |
|---|---|---|---|---|---|
| 0 | 1969 | 1 | 1 | F | 4046 |
| 1 | 1969 | 1 | 1 | M | 4440 |
| 2 | 1969 | 1 | 2 | F | 4454 |
| 3 | 1969 | 1 | 2 | M | 4548 |
| 4 | 1969 | 1 | 3 | F | 4548 |
Детально разобраться в этих данных нам поможет сводная таблица. Давайте добавим столбец «decade» (десятилетие) и посмотрим, как изменялось количество новорожденных каждого пола в зависимости от десятилетия:
births['decade'] = 10 * (births['year'] // 10) births.pivot_table('births', index='decade', columns='gender', aggfunc='sum')
| gender | F | M |
|---|---|---|
| decade | ||
| 1960 | 1753634 | 1846572 |
| 1970 | 16263075 | 17121550 |
| 1980 | 18310351 | 19243452 |
| 1990 | 19479454 | 20420553 |
| 2000 | 18229309 | 19106428 |
Сразу же видно, что в каждом десятилетии количество новорожденных мальчиков превышает количество новорожденных девочек. Чтобы подробнее изучить эту тенденцию, давайте визуализируем общее количество новорожденных по годам с помощью встроенных в библиотеку Pandas инструментов визуализации:
%matplotlib inline import matplotlib.pyplot as plt sns.set() # use seaborn styles births.pivot_table('births', index='year', columns='gender', aggfunc='sum').plot() plt.ylabel('total births per year');
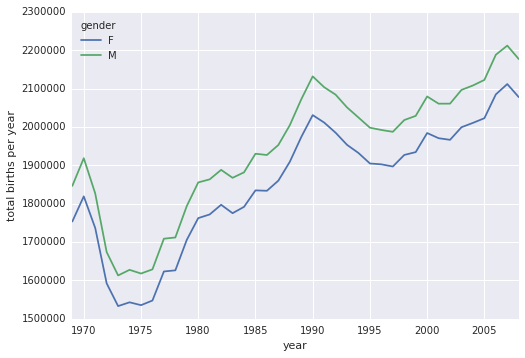
С помощью простой сводной таблицы и метода plot(), мы быстро получаем наглядное представление о динамике рождаемости мальчиков и девочек в зависимости от года. При оценке на глаз видно, что в течение последних 50-ти лет количество новорожденных мальчиков примерно на 5% превышало количество новорожденных девочек.
Продолжаем исследование данных
Хотя это необязательно относится к сводным таблицам, тем не менее существует дополнительная интересная информация, которую мы можем извлечь из этого набора данных с помощью рассмотренных инструментов библиотеки Pandas. Необходимо начать с очистки данных, чтобы избавиться от аномальных значений, связанных с несуществующими датами, такими как 31-е июня или 99-е июня. Мы удалим все аномальные значения с помощью операции робастного ограничения среднеквадратичного отклонения (robust sigma-clipping):
# Some data is mis-reported; e.g. June 31st, etc. # remove these outliers via robust sigma-clipping quartiles = np.percentile(births['births'], [25, 50, 75]) mu = quartiles[1] sig = 0.7413 * (quartiles[2] - quartiles[0]) births = births.query('(births > @mu - 5 * @sig) & (births < @mu + 5 * @sig)')
Затем преобразуем значения в столбце «day» к целочисленному типу. Исходно эти значения являются строками, потому что некоторые из них представляют собой строку «null»:
# set 'day' column to integer; it originally was a string due to nulls births['day'] = births['day'].astype(int)
Наконец, мы можем объединить день, месяц и год, чтобы создать индекс «date» (дата). Это позволит нам легко вычислить день недели, соответствующий каждой строке:
# create a datetime index from the year, month, day births.index = pd.to_datetime(10000 * births.year + 100 * births.month + births.day, format='%Y%m%d') births['dayofweek'] = births.index.dayofweek
Теперь можно визуализировать динамику рождаемости по дням недели для разных десятилетий:
import matplotlib.pyplot as plt import matplotlib as mpl births.pivot_table('births', index='dayofweek', columns='decade', aggfunc='mean').plot() plt.gca().set_xticklabels(['Mon', 'Tues', 'Wed', 'Thurs', 'Fri', 'Sat', 'Sun']) plt.ylabel('mean births by day');
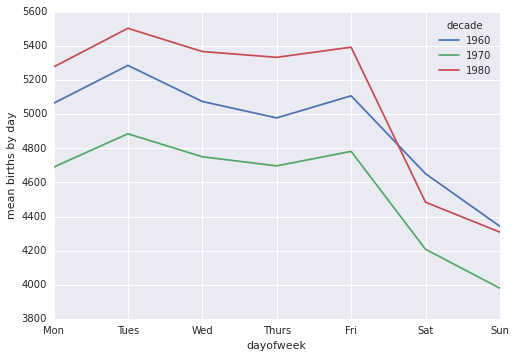
Очевидно, что в будние дни на свет появилось немного больше новорожденных, чем в выходные! Обратите внимание, 1990-е и 2000-е годы отсутствуют, потому что, начиная с 1989 года, в отчетах CDC присутствует только количество новорожденных по месяцам, а не по дням.
Давайте визуализируем еще один интересный показатель – среднее количество новорожденных, приходящееся на каждый день года. Мы можем реализовать это, создав массив дат для определенного года, выбрав при этом високосный год, чтобы учесть 29-е февраля.
# Choose a leap year to display births by date dates = [pd.datetime(2012, month, day) for (month, day) in zip(births['month'], births['day'])]
Теперь сгруппируем данные по дню года и визуализируем результат. Дополнительно выведем на график подписи для тех дней, на которые приходятся некоторые праздники, отмечаемые в США:
# Plot the results fig, ax = plt.subplots(figsize=(8, 6)) births.pivot_table('births', dates).plot(ax=ax) # Label the plot ax.text('2012-1-1', 3950, "New Year's Day") ax.text('2012-7-4', 4250, "Independence Day", ha='center') ax.text('2012-9-4', 4850, "Labor Day", ha='center') ax.text('2012-10-31', 4600, "Halloween", ha='right') ax.text('2012-11-25', 4450, "Thanksgiving", ha='center') ax.text('2012-12-25', 3800, "Christmas", ha='right') ax.set(title='USA births by day of year (1969-1988)', ylabel='average daily births', xlim=('2011-12-20','2013-1-10'), ylim=(3700, 5400)); # Format the x axis with centered month labels ax.xaxis.set_major_locator(mpl.dates.MonthLocator()) ax.xaxis.set_minor_locator(mpl.dates.MonthLocator(bymonthday=15)) ax.xaxis.set_major_formatter(plt.NullFormatter()) ax.xaxis.set_minor_formatter(mpl.dates.DateFormatter('%h'));
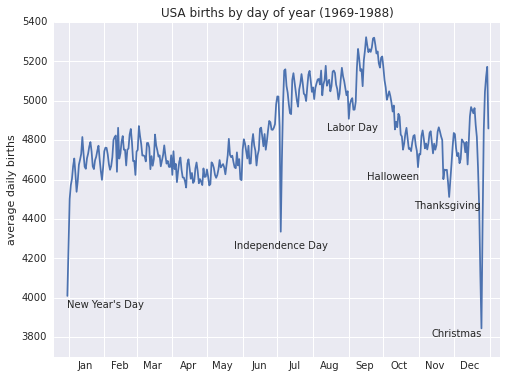
Низкая рождаемость в праздничные дни впечатляет, но это скорее результат выбора даты для плановых или вынужденных родов, чем следствие каких-либо глубоких психосоматических причин.
Эта небольшая статья должна дать вам хорошее представление о том, как разнообразные инструменты из библиотеки Pandas могут быть объединены вместе и использованы для извлечения информации из различных наборов данных. В следующих статьях мы рассмотрим более сложные подходы к анализу этих и других данных!
Сводные таблицы — Python: Pandas
Во многих случаях аналитики должны предоставить агрегированные или сгруппированные данные. Эта информация помогает понять общие характеристики в определенных разрезах данных. Часто этого достаточно, чтобы достичь бизнес-цели или принимать решения.
В этом уроке мы продемонстрируем методы работы с инструментами библиотеки Pandas, чтобы делать такие операции.
Агрегация данных с использованием метода agg()
Функции агрегирования вычисляют интегральные параметры наборов данных. Обычно возвращаемые значения — это несколько чисел. Чаще всего это одно значение для одного столбца данных.
import pandas as pd df_clicks = pd.read_csv('./data/Cite_clicks_info.csv', index_col=0) print(df_clicks.head()) # => SHOP1 SHOP2 SHOP3 SHOP4 Advertising Size # day # 1 319.0 -265.0 319.0 328.0 small big # 2 292.0 274.0 292.0 301.0 medium small # 3 283.0 301.0 274.0 283.0 medium small # 4 328.0 364.0 328.0 NaN small small # 5 391.0 355.0 373.0 337.0 small small В датасете столбец Advertising со значениями 'small', 'medium', 'large'. Они указывают на объем рекламы в этот день по магазинам, например, 'small' — были низкие объемы рекламы. А также столбец Size со значениями 'small' и 'big', которые указывают на величину магазина.
Примеры агрегаций
С помощью метода agg() и встроенных функций можно вычислять агрегированные значения. Например, вычислим среднее число кликов каждого магазина:
print(df_clicks.drop(['Advertising', 'Size'], axis=1).agg('mean')) # => SHOP1 343.807692 # SHOP2 334.481481 # SHOP3 315.785714 # SHOP4 304.230769 # dtype: float64 Мы исключили столбцы 'Advertising', 'Size' в примере выше. Это категории, а не численные показатели. Вычисление функции mean() вызвало бы ошибку на категориальных столбцах.
Посчитаем несколько агрегаций одновременно для одного столбца. Для этого в аргументы метода agg() подадим список с перечислением функций:
print(df_clicks.drop(['Advertising', 'Size'], axis=1).agg(['max', 'mean'])) # => SHOP1 SHOP2 SHOP3 SHOP4 # max 581.000000 490.000000 581.000000 529.000000 # mean 343.807692 334.481481 315.785714 304.230769 Продвинутые примеры агрегаций
С помощью метода agg() можно строить и более сложные примеры. Применим к столбцами различные агрегирующие функции:
dict_func = 'SHOP1': ['mean', 'max'], 'SHOP2': ['mean', 'max'], 'SHOP3': ['mean', 'max'], 'SHOP4': ['mean', 'max'], 'Advertising' : ['count']> print(df_clicks.agg(dict_func)) # => SHOP1 SHOP2 SHOP3 SHOP4 Advertising # sum 8939.0 9031.0 8842.0 7910.0 NaN # max 581.0 490.0 581.0 529.0 NaN # count NaN NaN NaN NaN 28.0 Соответствующие функции применились к указанным столбцам. Для этого использовали словари для определения множества функций, при этом допустимо использование кортежей:
print(df_clicks.agg(shop1_mean=('SHOP1', 'mean'), shop2_mean=('SHOP2', 'mean'), advertising_count=('Advertising', 'count'))) # => SHOP1 SHOP2 Advertising # shop1_mean 343.807692 NaN NaN # shop2_mean NaN 334.481481 NaN # advertising_count NaN NaN 28.0 Подход со словарями более популярен, так как в подходе с кортежами есть ограничения по применению только одного агрегирования за раз к определенному столбцу.
Агрегация данных с использованием метода groupby()
Рассмотрим агрегацию данных через следующие функции:
- Числовые агрегирующие функции
- Функции подсчета
- Функции порядка
Числовые агрегирующие функции
С помощью метода groupby() можно находить значения агрегированных данных по определенным категориям. Вычислим агрегированные значения для дней, когда значение столбца Advertising было 'small', 'medium' и 'large':
print(df_clicks.groupby(['Advertising']).agg(['mean', 'median'])) # => SHOP1 SHOP2 SHOP3 SHOP4 # mean median mean median mean median mean median # Advertising # large 350.00 319.5 294.41 327.5 309.61 320.0 219.61 312.0 # medium 270.28 312.0 346.37 338.0 260.00 322.5 380.85 344.0 # small 406.71 421.0 389.57 384.0 391.00 399.0 398.16 373.5 Значение агрегирующих функций вычислились для каждого столбца, причем для всех категорий из столбца 'Advertising'.
Можно для каждого столбца находить свои агрегации:
agg_func = 'SHOP1': ['mean','max'], 'SHOP2': ['min', 'median'], 'SHOP3':['std', 'var'], 'SHOP4': ['min', 'max']> print(df_clicks.groupby(['Advertising']).agg(agg_func).round(2)) # => SHOP1 SHOP2 SHOP3 SHOP4 # mean max min median std var min max # Advertising # large 350.00 581.0 -265.0 327.5 197.99 39200.26 -477.0 409.0 # medium 270.29 531.0 264.0 338.0 294.71 86851.43 311.0 487.0 # small 406.71 529.0 282.0 384.0 63.02 3971.33 321.0 529.0 Метод round() округляет дробную часть до двух знаков после запятой. Форматирование упрощает чтение данных.
Функции подсчета
В предыдущем разделе приведены примеры агрегаций для числовых столбцов. В этом разделе покажем примеры агрегаций на категориальных столбцах:
agg_func = 'Advertising':['count', 'nunique']> print(df_clicks.groupby(['Size']).agg(agg_func)) # => Advertising # count nunique # Size # big 9 3 # small 19 3 Функция count подсчитывает количество значений соответствующей категории, функция nunique находит количество уникальных значений в категории. Функция nunique не учитывает пропуски при подсчете.
Функции порядка
В этом разделе покажем, как получать максимальное и минимальное количество кликов магазина по категориям рекламы. Будем использовать функции first() и last() :
agg_func = 'SHOP1': ['first', 'last']> print(df_clicks.sort_values(by='SHOP1').groupby('Advertising').agg(agg_func)) # => SHOP1 # first last # Advertising # large -424.0 581.0 # medium 283.0 487.0 # small 319.0 531.0 Чтобы использовать функции порядка датасет, их нужно предварительно упорядочить. Для этого можно использовать метод sort_values() .
Открыть доступ
Курсы программирования для новичков и опытных разработчиков. Начните обучение бесплатно
- 130 курсов, 2000+ часов теории
- 1000 практических заданий в браузере
- 360 000 студентов
Наши выпускники работают в компаниях:
Pandas: как создать сводную таблицу с суммой значений
Вы можете использовать следующий базовый синтаксис для создания сводной таблицы в pandas, которая отображает сумму значений в определенных столбцах:
pd.pivot_table(df, values='col1', index='col2', columns='col3', aggfunc='sum') В следующем примере показано, как использовать этот синтаксис на практике.
Пример: создание сводной таблицы Pandas с суммой значений
Предположим, у нас есть следующий кадр данных pandas, который содержит информацию о различных баскетболистах:
import pandas as pd #create DataFrame df = pd.DataFrame() #view DataFrame print(df) team position points 0 A G 4 1 A G 4 2 A F 6 3 A F 8 4 B G 9 5 B F 5 6 B F 5 7 B F 12 В следующем коде показано, как создать сводную таблицу в pandas, которая показывает сумму значений «баллов» для каждой «команды» и «позиции» в DataFrame:
#create pivot table df_pivot = pd.pivot_table(df, values='points', index='team', columns='position', aggfunc='sum') #view pivot table print(df_pivot) position F G team A 14 8 B 22 9 Из вывода мы видим:
- Игроки команды A на позиции F набрали в общей сложности 14 очков.
- Игроки команды А на позиции G набрали в сумме 8 очков.
- Игроки команды B на позиции F набрали в общей сложности 22 очка.
- Игроки команды B на позиции G набрали в сумме 9 очков.
Обратите внимание, что мы также можем использовать аргумент margin для отображения сумм маржи в сводной таблице:
#create pivot table with margins df_pivot = pd.pivot_table(df, values='points', index='team', columns='position', aggfunc='sum', margins= True , margins_name='Sum') #view pivot table print(df_pivot) position F G Sum team A 14 8 22 B 22 9 31 Sum 36 17 53 В сводной таблице теперь отображаются суммы строк и суммы столбцов.
Примечание.Полную документацию по функции pandas pivot_table() можно найти здесь .
Дополнительные ресурсы
В следующих руководствах объясняется, как выполнять другие распространенные операции в pandas:
Python, pandas и решение трёх задач из мира Excel
Excel — это чрезвычайно распространённый инструмент для анализа данных. С ним легко научиться работать, есть он практически на каждом компьютере, а тот, кто его освоил, может с его помощью решать довольно сложные задачи. Python часто считают инструментом, возможности которого практически безграничны, но который освоить сложнее, чем Excel. Автор материала, перевод которого мы сегодня публикуем, хочет рассказать о решении с помощью Python трёх задач, которые обычно решают в Excel. Эта статья представляет собой нечто вроде введения в Python для тех, кто хорошо знает Excel.

Загрузка данных
Начнём с импорта Python-библиотеки pandas и с загрузки в датафреймы данных, которые хранятся на листах sales и states книги Excel. Такие же имена мы дадим и соответствующим датафреймам.
import pandas as pd sales = pd.read_excel('https://github.com/datagy/mediumdata/raw/master/pythonexcel.xlsx', sheet_name = 'sales') states = pd.read_excel('https://github.com/datagy/mediumdata/raw/master/pythonexcel.xlsx', sheet_name = 'states') Теперь воспользуемся методом .head() датафрейма sales для того чтобы вывести элементы, находящиеся в начале датафрейма:
print(sales.head()) Сравним то, что будет выведено, с тем, что можно видеть в Excel.

Сравнение внешнего вида данных, выводимых в Excel, с внешним видом данных, выводимых из датафрейма pandas
Тут можно видеть, что результаты визуализации данных из датафрейма очень похожи на то, что можно видеть в Excel. Но тут имеются и некоторые очень важные различия:
- Нумерация строк в Excel начинается с 1, а в pandas номер (индекс) первой строки равняется 0.
- В Excel столбцы имеют буквенные обозначения, начинающиеся с буквы A , а в pandas названия столбцов соответствуют именам соответствующих переменных.
Реализация возможностей Excel-функции IF в Python
В Excel существует очень удобная функция IF , которая позволяет, например, записать что-либо в ячейку, основываясь на проверке того, что находится в другой ячейке. Предположим, нужно создать в Excel новый столбец, ячейки которого будут сообщать нам о том, превышают ли 500 значения, записанные в соответствующие ячейки столбца B . В Excel такому столбцу (в нашем случае это столбец E ) можно назначить заголовок MoreThan500 , записав соответствующий текст в ячейку E1 . После этого, в ячейке E2 , можно ввести следующее:
=IF([@Sales]>500, "Yes", "No") Использование функции IF в Excel
Для того чтобы сделать то же самое с использованием pandas, можно воспользоваться списковым включением (list comprehension):
sales['MoreThan500'] = ['Yes' if x > 500 else 'No' for x in sales['Sales']] 
Списковые включения в Python: если текущее значение больше 500 — в список попадает Yes, в противном случае — No
Списковые включения — это отличное средство для решения подобных задач, позволяющее упростить код за счёт уменьшения потребности в сложных конструкциях вида if/else. Ту же задачу можно решить и с помощью if/else, но предложенный подход экономит время и делает код немного чище. Подробности о списковых включениях можно найти здесь.
Реализация возможностей Excel-функции VLOOKUP в Python
В нашем наборе данных, на одном из листов Excel, есть названия городов, а на другом — названия штатов и провинций. Как узнать о том, где именно находится каждый город? Для этого подходит Excel-функция VLOOKUP , с помощью которой можно связать данные двух таблиц. Эта функция работает по принципу левого соединения, когда сохраняется каждая запись из набора данных, находящегося в левой части выражения. Применяя функцию VLOOKUP , мы предлагаем системе выполнить поиск определённого значения в заданном столбце указанного листа, а затем — вернуть значение, которое находится на заданное число столбцов правее найденного значения. Вот как это выглядит:
=VLOOKUP([@City],states,2,false) Зададим на листе sales заголовок столбца F как State и воспользуемся функцией VLOOKUP для того чтобы заполнить ячейки этого столбца названиями штатов и провинций, в которых расположены города.
Использование функции VLOOKUP в Excel
В Python сделать то же самое можно, воспользовавшись методом merge из pandas. Он принимает два датафрейма и объединяет их. Для решения этой задачи нам понадобится следующий код:
sales = pd.merge(sales, states, how='left', on='City') - Первый аргумент метода merge — это исходный датафрейм.
- Второй аргумент — это датафрейм, в котором мы ищем значения.
- Аргумент how указывает на то, как именно мы хотим соединить данные.
- Аргумент on указывает на переменную, по которой нужно выполнить соединение (тут ещё можно использовать аргументы left_on и right_on , нужные в том случае, если интересующие нас данные в разных датафреймах названы по-разному).
Сводные таблицы
Сводные таблицы (Pivot Tables) — это одна из самых мощных возможностей Excel. Такие таблицы позволяют очень быстро извлекать ценные сведения из больших наборов данных. Создадим в Excel сводную таблицу, выводящую сведения о суммарных продажах по каждому городу.
Создание сводной таблицы в Excel
Как видите, для создания подобной таблицы достаточно перетащить поле City в раздел Rows , а поле Sales — в раздел Values . После этого Excel автоматически выведет суммарные продажи для каждого города.
Для того чтобы создать такую же сводную таблицу в pandas, нужно будет написать следующий код:
sales.pivot_table(index = 'City', values = 'Sales', aggfunc = 'sum') - Здесь мы используем метод sales.pivot_table , сообщая pandas о том, что мы хотим создать сводную таблицу, основанную на датафрейме sales .
- Аргумент index указывает на столбец, по которому мы хотим агрегировать данные.
- Аргумент values указывает на то, какие значения мы собираемся агрегировать.
- Аргумент aggfunc задаёт функцию, которую мы хотим использовать при обработке значений (тут ещё можно воспользоваться функциями mean , max , min и так далее).
Итоги
Из этого материала вы узнали о том, как импортировать Excel-данные в pandas, о том, как реализовать средствами Python и pandas возможности Excel-функций IF и VLOOKUP , а также о том, как воспроизвести средствами pandas функционал сводных таблиц Excel. Возможно, сейчас вы задаётесь вопросом о том, зачем вам пользоваться pandas, если то же самое можно сделать и в Excel. На этот вопрос нет однозначного ответа. Python позволяет создавать код, который поддаётся тонкой настройке и глубокому исследованию. Такой код можно использовать многократно. Средствами Python можно описывать очень сложные схемы анализа данных. А возможностей Excel, вероятно, достаточно лишь для менее масштабных исследований данных. Если вы до этого момента пользовались только Excel — рекомендую испытать Python и pandas, и узнать о том, что у вас из этого получится.
А какие инструменты вы используете для анализа данных?
Напоминаем, что у нас продолжается конкурс прогнозов, в котором можно выиграть новенький iPhone. Еще есть время ворваться в него, и сделать максимально точный прогноз по злободневным величинам.