Что такое интеграция данных?

Интеграция данных – это процесс обеспечения согласованного доступа и доставки для данных любого типа на предприятии. Все отделы в организации собирают большие объемы данных, имеющие различные структуры, форматы и функции. Интеграция данных включает в себя архитектурные методы, инструменты и практики, которые позволяют объединить разрозненные данные для выполнения анализа. В результате организации получают комплексное представление своих данных для извлечения ценной бизнес-аналитики.
Почему интеграция данных настолько важна?
Обычно в современных организациях есть множество инструментов, технологий и сервисов, которые собирают и хранят данные. Фрагментация данных становится причиной разрозненности и проблем с доступом.
Например, приложению для бизнес-аналитики требуются маркетинговые и финансовые данные для улучшения рекламных стратегий. Однако эти наборы данных хранятся в разных форматах. Поэтому нужна внешняя система, которая очистит, отфильтрует наборы данных и переведет их в нужный формат перед проведением анализа. Кроме того, инженеры по обработке данных могут выполнять определенные задачи обработки вручную, что приводит к дальнейшим задержкам. Несмотря на эти усилия, приложение может пропустить критически важный набор данных, потому что аналитическое подразделение не знало о его существовании.
Интеграция данных призвана решить эти проблемы с использованием различных методов обеспечения стабильности доступа. Например, все аналитики данных и приложения для бизнес-аналитики используют единую, унифицированную платформу для доступа к разрозненным данным из различных бизнес-процессов. Ниже перечислены некоторые преимущества интеграции данных.
- Повышение эффективности управления данными и увеличение коэффициента использования
- Повышение качества и целостности данных
- Ускорение получения ценной аналитической информации, основанной на точных и релевантных данных.
Каковы варианты использования интеграции данных?
Компании применяют решения по интеграции данных для нескольких примеров использования. Ниже мы рассмотрим этот вопрос подробнее.
Машинное обучение
Машинное обучение – это обучение программного обеспечения для искусственного интеллекта (ИИ) на основе большого объема точных данных. Данные в процессе интеграции извлекаются в централизованное местоположение и преобразуются в форматы, поддерживающие машинное обучение. Например, Mortar Data предоставляет компаниям современные технологии обработки данных для обучения моделей машинного обучения с использованием консолидации данных в Amazon RedShift.
Прогнозная аналитика
Прогнозная аналитика – это подход, заключающийся в прогнозировании отдельной тенденции с использованием новейших исторических данных. Например, компании используют прогнозную аналитику для составления расписаний обслуживания оборудования до того, как случится сбой. Они анализируют исторические эксплуатационные данные для выявления аномальных тенденций и принятия мер по их устранению.
Миграция в облако
Компании используют технологии интеграции данных для беспрепятственного перехода к использованию облачных технологий. Перенос всех устаревших баз данных в облако – это сложный процесс, который может стать причиной прерывания экономической деятельности. Вместо этого компании используют стратегии интеграции данных, такие как интеграция промежуточного программного обеспечения, чтобы обеспечить постепенный перенос данных в облачное хранилище и гарантировать непрерывность деятельности.
Каков принцип работы интеграции данных?
Интеграция данных – это сложная отрасль, в которой используются различные инструменты и решения, применяющие различные подходы к решению проблемы. В прошлом решения были сконцентрированы на физическом хранилище данных. Данные физически преобразовывались и перемещались в центральный репозиторий в унифицированном формате. Со временем были разработаны виртуальные решения. Центральная система предоставляла унифицированное представление всех данных, не изменяя базовые физические данные. В недавнее время внимание переместилось на федеративные решения, такие как сетки данных. Каждое бизнес-подразделение управляет своими данными независимо от других, но предоставляет их в формате, утвержденном на центральном уровне.
В решениях по интеграции данных на рынке также применяются различные подходы. Вы найдете некоторые инструменты, в которых используются новые подходы для повышения эффективности традиционных технологий. К сожалению, сложившаяся фрагментация решений на рынке привела к фрагментации подходов на крупных предприятиях. В различных подразделениях для выполнения специфических требований используются различные инструменты. Обычно крупные организации содержат как устаревшие, так и современные системы интеграции данных, что приводит к наложению и избыточности данных.
Какие подходы используются для интеграции данных?
Архитекторы данных используют для интеграции данных следующие подходы.
Консолидация данных
В процессе консолидации данных используются инструменты для извлечения, очищения и хранения физических данных в конечном хранилище. Этот процесс устраняет разрозненность данных и сокращает затраты на инфраструктуру. Существует два основных типа инструментов для консолидации данных.
ETL
Аббревиатура ETL расшифровывается как «extract, transform and load» и означает извлечение, преобразование и загрузку данных. Сначала в процессе ETL выполняется извлечение данных из различных источников. Затем производится преобразование данных в соответствии с бизнес-правилами, форматами и соглашениями. Например, инструмент для ETL может перевести все значения по транзакциям в доллары США, даже если продажи осуществлялись в другой валюте. В итоге преобразованные данные загружаются в целевую систему, например хранилище данных.
ELT
Аббревиатура ELT расшифровывается как «extract, load and transform» и означает извлечение, загрузку и преобразование данных. Этот процесс подобен ETL, но в ELT два последних шага обработки данных меняются местами. Все данные загружаются в неструктурированную систему данных, например озеро баз данных, и преобразуются только по требованию. ELT пользуется преимуществами эффективности облачных вычислений и масштабируемости облака, чтобы обеспечить интеграцию в режиме реального времени.
Репликация данных
В процессе репликации данных (также называемого распространением данных) вместо физического перемещения данных из одной системы в другую производится их дублирование. Эта технология эффективна для малых и средних предприятий, у которых не особо много источников данных. Например, предприятие, занимающееся розничной продажей оборудования могло бы использовать репликацию корпоративных данных для копирования определенных таблиц из базы данных склада в базу данных продаж.
Виртуализация данных
При виртуализации данных они не перемещаются из одной системы в другую. Вместо этого создается единое виртуальное представление, в котором интегрированы все источники данных. При виртуализации данных не производится их передача между базами данных в системах хранения. Вместо этого после получения запроса панель управления заполняется данными из нескольких источников.
Федерация данных
Федерация данных подразумевает создание виртуальной базы данных на основе нескольких источников данных. Она работает подобно виртуализации данных, но при федерации не производится интегрирование источников данных. Вместо этого после получения запроса система извлекает данные из соответствующих источников и упорядочивает их согласно стандартной модели данных в режиме реального времени.
В чем разница между интеграцией данных и интеграцией приложений?
Интеграция приложений – это процесс, который позволяет двум или более программным приложениям взаимодействовать друг с другом. Это предполагает создание общей коммуникационной структуры или API, которая позволяет одному приложению получать доступ к функциям другого приложения. API – это программа-посредник, которая позволяет программам общаться друг с другом.
Интеграция приложений расширяет возможности существующей программы путем ее интеграции с другой программой. Например, вы можете интегрировать автоответчик электронной почты с приложением для управления взаимоотношениями с клиентами (CRM). Между тем интеграция данных извлекает, объединяет и загружает все данные о клиентах из многочисленных систем-источников в облачное хранилище данных.
Как AWS помогает в интеграции данных?
Аналитика в AWS предоставляет всю инфраструктуру, необходимую для сложных решений по интеграции данных. Мы предоставляем самый широкий выбор аналитических сервисов для создания специализированных приложений интеграции данных с наилучшей производительностью, масштабируемостью и минимальными затратами.
Если говорить о готовом решении, то AWS Glue – это инструмент интеграции данных, который позволяет компаниям извлекать, очищать и консолидировать данные в масштабе. Он позволяет архитекторам данных интегрировать данные с помощью различных методов, таких как извлечение, преобразование и загрузка (ETL); извлечение, загрузка и преобразование (ELT); пакетная обработка и потоковая передача.
- Каталог данных AWS Glue позволяет специалистам по исследованию данных эффективно запрашивать данные и наблюдать за тем, как они изменяются со временем
- AWS Glue DataBrew предлагает визуальный интерфейс, позволяющий аналитикам данных преобразовывать данные без написания кода
- Функция обнаружения конфиденциальных данных AWS Glue автоматически идентифицирует, обрабатывает и маскирует конфиденциальные данные
- AWS Glue DevOps позволяет разработчикам более последовательно отслеживать, тестировать и развертывать задания по интеграции данных
Начните работу с интеграцией данных на AWS, зарегистрировав аккаунт AWS уже сегодня.
Почему интеграционная БД это отстой
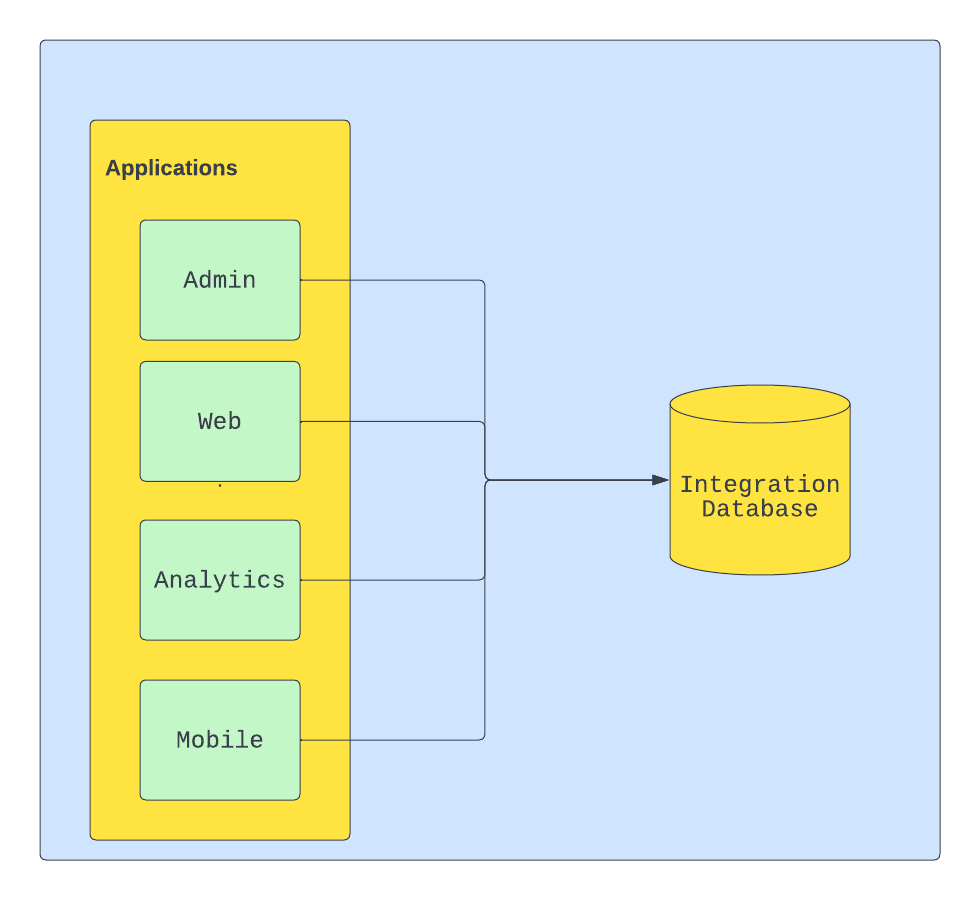
Интеграционная или shared база данных это архитектурный подход с которым мне часто приходилось сталкиваться, и практически никогда эта встреча не сулила ничего хорошего. Как правило, команда выбирает данный подход по нескольким причинам:
- Не надо писать никакие контракты и схемы для интеграций сервисов между собой через API, а каждый может читать/писать из одной БД.
- Не надо думать о синхронизации данных, если данные в БД записались значит консистентность достигнута.
- Не надо снимать бэкапы с нескольких хранилищ, если можно снимать с одной единственной БД.
Есть еще одна причина, это когда горели сроки и надо было срочно добавить новый сервис, а потом переделывать всем было лень. И вжух, у нас через год пяток сервисов, которые работают с одной БД и с одними и теми же таблицами, но это скорей организационная проблема, чем осознанный выбор.
Но по мере развития проекта и увеличения команды все эти плюсы улетучиваются или даже превращаются в минусы. Об этом и поговорим ниже.
Страшно менять
По мере развития проекта рано или поздно вам придется менять схему БД. И тут вылезет самая очевидная проблема, менять схему вам будет страшно и больно.
Для начала разберем случай с переименованием колонок.
id
name
chat_id
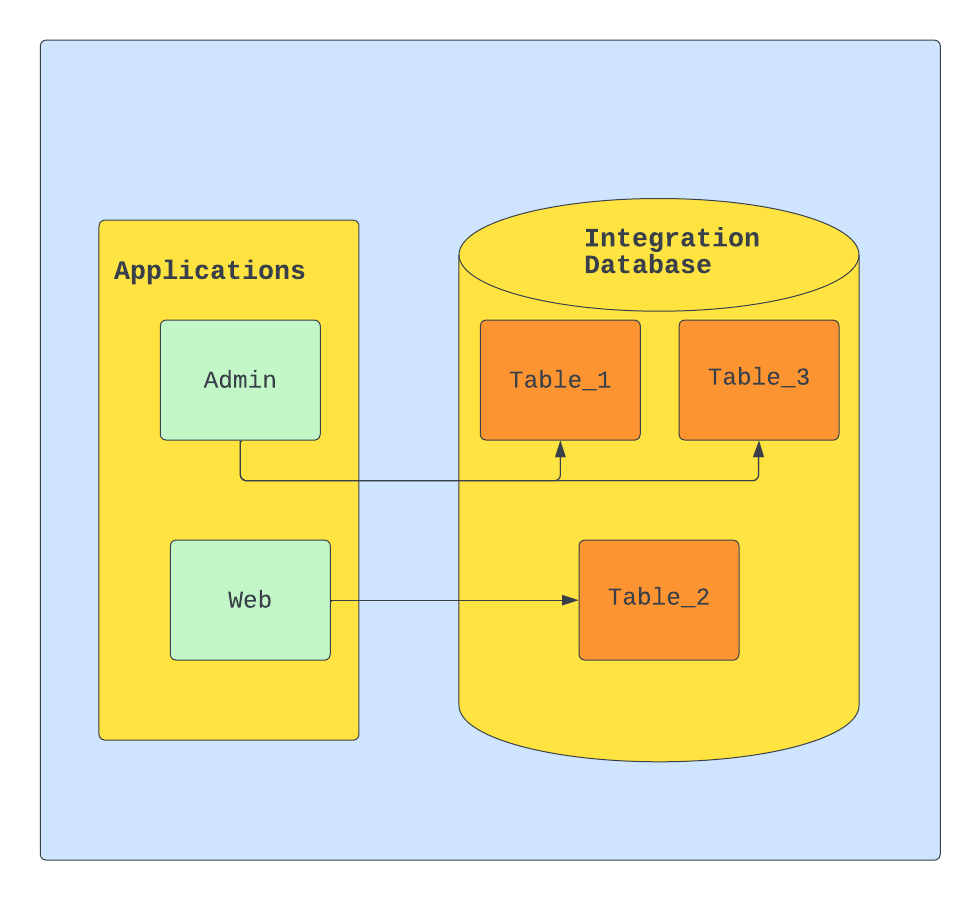
Например, у нас есть таблица пользователей ( users ) с id , name , chat_id , где сhat_id — это id пользователя в telegram, но логика поменялась, и теперь надо еще хранить id пользователей из whatsapp. Если бы вы разрабатывали обычный монолит или сервис со своим хранилищем, то вы просто переименовали бы колонку в telegram_id , а также поправили код, который с ней взаимодействует. Если у вас интеграционная БД, то велик шанс, что вы сломаете код другого сервиса. Например, сервис нотификаций использует chat_id для рассылки сообщений пользователям.
С удалением все аналогично, любой сервис, который использует удаляемую колонку для чтения/обновления/удаления будет моментально сломан.
Но вот с добавлением новых колонок не должно быть проблем, а вот и нет. Например, один сервис занимается регистрацией пользователей через web, а другой регистрирует через реферальную программу, если один из них добавит новую колонку в таблицу users с NOT NULL другой будет моментально сломан. Ведь другой сервис ничего не знает об этой колонке и не сможет осуществлять записи в эту таблицу.
Как итог вам придется бегать по всем сервисам и проверять не используют ли они колонку, которую вы собираетесь изменять в своих целях. И если вам не повезло, то вам придется общаться с командами этих сервисов, чтобы они внесли эти изменения к себе в код, а затем проводить увлекательную синхронизацию релиза нескольких сервисов в продакшен. Из за такой «удобной» процедуры разработчики не будут удалять колонки, а новые колонки будут создавать с DEFAULT NULL или другим дефолтным значением, что не очень хорошо по многим причинам. А переименовывать колонки будут только в самом крайнем случае. Думаю, не надо объяснять, что таблицы в БД при таком подходе будут быстро превращаться в хламовник со старой мебелью.
Никто не владеет схемой
С shared БД, по факту, за миграцию схемы будет отвечать один человек/команда, который будет владеть репозиторием, куда все остальные разработчики должны пушить новые миграции. А владелец должен ревьюить все эти изменения на то, что они не сломают код в остальных сервисах. По факту этот человек/команда становится бутылочным горлышком всей разработки, так как они могут не успевать это делать: у них могут быть другие задачи или они просто захлебываются под merge request на изменение схемы. И роли владельца схемы тут сложно позавидовать, ибо бегать по пачке репозиториев в поисках потенциально сломанного кода, дело утомительное, особенно если сервисы написаны на разных языках. Также встает вопрос, а кто должен согласовывать изменения в схеме БД с другими командами, владелец схемы или тот, кто сделал merge request? А когда мы даже все согласовали, встает довольно непростая задача, как все это зарелизить синхронно? Плюс откатываться назад мы по сути не можем, ведь надо откатывать назад не один сервис с БД, а сразу целую пачку плюс сервис, который накатывает миграции.
Другой вариант, что миграции пишутся в каждом отдельном сервисе и накатываются им же при деплое. Но тут вообще остается надеяться только на устные договоренности и на то, что никто из разработчиков не совершит ошибку. По факту, схемой БД начинает владеть «коллективное бессознательное». Вводить в курс дела нового человека становится очень сложно, и требуется по 50 раз перечитывать миграции и код, работающий с БД.
Курица не птица, а БД не API
Один из плюсов интеграционной БД, указанных выше: «Не надо писать никакие контракты и схемы для интеграций сервисов между собой через API». Это же и минус. В начале все удобно и прикольно, но затем все становится очень больно.
Во-первых, API снижает когнитивную нагрузку на потребителя. Оно предоставляет схему данных и ресурсы, над которыми можно совершать какие-то действия. Когда же вы смотрите на структуры таблиц вам требуется гораздо больше мозговых усилий на то, чтобы выделить ресурсы и отбросить все лишние колонки, которые вам не требуются в данный момент для решения задачи. Кроме того, сущность может быть разбита на несколько таблиц (например, фильм и его расписание это скорее всего разные таблицы), а в API она скорее всего представлена одной сущностью с вложенными атрибутами. Ко всему прочему таблица может содержать кучу технических колонок или колонок для других сервисов, и разработчику придется прорубаться сквозь этот лес. Я уже не говорю о том, что проблема «страх изменения схемы» описанная ранее, ведет к тому, что таблицы будут гораздо быстрее замусориваться, чем в раздельных БД. Грубо говоря, БД это как большая и толстая книга, а API как краткое содержание этой книги.
Во-вторых, вам придется выкинуть на помойку все плюшки кодогенерации из схемы вашего API, а также будут большие проблемы с валидацией. Например, есть таблица files с колонкой link , которая содержала ссылку на файл и это был полный путь вместе с доменом, а затем у нас стало множество файловых хранилищ и ссылка теперь должна записываться без домена. Как защититься от того, чтобы не произошло записи link в старом формате? И где писать валидацию? Ведь писать можно из разных сервисов, и защититься от этого становится сложно. Да, можно писать триггеры и хранимые процедуры, но тогда этот код становится прибит к БД, и будет находиться вне git, к тому же SQL не лучший язык для написания сложной логики и последующей ее поддержке. Ко всему прочему при большой нагрузке, БД не скажет вам спасибо за ваши навороченные констрайнты и триггеры.
В-третьих, аудит данных, rate limit и логирование практически нереально реализовать, ведь добраться до данных может любой сервис и что-то с ними сделать. Да, можно завести отдельных пользователей с правами, но тогда все плюсы от интеграционной БД уйдут, ведь придется писать API для других сервисов. Опять же остаются хранимые процедуры и триггеры, но тогда разработка становится БД ориентированной.
Данные целостны, почти.
Это правда, c интеграционной БД вы получаете консистентные данные из коробки. Это по сути единственный плюс такого подхода. В случае, если данные записались в таблицу БД не требуются разные очереди сообщений, поддержка retry, webhooks и прочие вещи для достижения консистентности данных при наличии множества хранилищ. Но тут есть две оговорки, во-первых, вы будете иметь очень хорошо синхронизированную помойку, которую страшно трогать, а во-вторых, проблемы синхронизации полностью все равно не уйдут. Ведь ваш сервис исполняет код вне БД, и остается возможность работы с устаревшими данными. Например, один сервис прочитал всю таблицу users в память и начинает рассылать email, используя фио пользователя, в это время пользователь через другой сервис изменил свое фио, в результате пользователь получит email со старыми данными.
Одним выстрелом двух зайцев
В плане администрирования кажется, что проще работать с одним хранилищем, чем с множеством (все данные в одном месте, снимать бэкапы и т.д), но тут много но.
Во-первых, одна БД – одна точка отказа для вашего проекта. Если она легла, то лежит все. Если у вас набор сервисов с независимыми хранилищами и они взаимодействуют друг с другом не в стиле «распределенного монолита», то отказ одной БД лишь ведет к отказу одного конкретного участка системы.
Во-вторых, если ваш проект доживет до большой нагрузки, то ваша интеграционная БД станет раскаленной сковородкой. В одну и ту же таблицу может писать множество сервисов, возможно блокируя друг друга или вызывая серьезные перестроения индексов, что плохо сказывается на быстродействии системы. Кто-то в силу глупости, неопытности или срочности может запустить «дико тяжелый» sql запрос от которого БД встанет на уши и все сервисы, которые с ней работают начнут тормозить. И какой бы крутой не была бы ваша БД, вы задумаетесь о ее масштабировании, а это будет сложно, ведь поддержку шардирования и репликации будет сложно внедрять, придется во всех сервисах переписывать код для чтения и записи. И скорее всего для простоты вы будете накидывать ресурсы виртуалке с БД и больше ничего не делать, пока не упретесь в потолок вертикального масштабирования. В случае аварии тяжелая и нагруженная БД может подниматься значительное время, а у вас тем временем недоступны вообще все сервисы. Снимать бэкапы с «горячей» и большой БД тоже отдельное приключение. Для цельного бэкапа надо поднимать реплику с такими же большими дисками, как на мастере, и при этом выделять много-много места под такие бэкапы где-то на других дисках. Все эти проблемы с бэкапом возможно подтолкнут к стратегии разной частотности бэкапов для разных данных, что не решит всех проблем, а даже создаст множество других. Как ранее мы выяснили, все описанные выше вещи будут осложняться тем, что БД будет замусориваться гораздо быстрее, чем с раздельными хранилищами под каждый сервис.
Имея раздельные БД для разных сервисов, нагрузка размажется или окажется в нескольких сервисах, которые можно кастомно масштабировать или докидывать ресурсов, а всем остальным хранилищам как раз можно будет их подурезать. Да, бэкапы придется снимать с множества инстансов, но размер и нагруженность баз будет меньше. И отказоустойчивость станет выше, см. пункт первый.
В-третьих, сменить тип хранилища становится невозможно или очень сложно. Например, одному из сервисов удобнее хранить данные в графовой БД, а другому в key-value. Если этими данными пользуются или их создают другие сервисы, команды этих сервисов должны будут переписать свой код для работы с новой БД, и они могут не хотеть этого делать по разным причинам. Если бы общение шло через то или иное API, то вопрос хранилища оставался вопросом команды этого сервиса.
Когда будет нормально
Есть частный случай, когда данный подход будет приемлем. Если каждый из ваших сервисов имеет свои таблицы, схемы (Postgres) или базы (MySQL) в физической БД и только он может писать и читать из них. Разделение прав на чтение и запись осуществляется через создание пользователей в БД под каждый сервис. А все взаимодействие между сервисами происходит через API или вызов модулей, если это части одной кодовой базы. Такой подход решает проблемы с управлениями данными и схемой, а также позволяет легко переехать сервисам на другой инстанс БД или вообще на другой вид БД, например, NoSQL.
Итог
Несмотря на то, что данный архитектурный паттерн присутствует в ряде книг по архитектуре и описывается не в столь мрачных тонах, мне кажется, что на данный момент это антипаттерн, от которого надо держаться подальше. Подобно тому как в коде проекта мы обычно стремимся к инкапсуляции, т.е. чтобы данные и методы для работы с ними находились бы в одном классе/модуле, аналогичный подход следует использовать для построения архитектуры всего проекта. Интеграционная БД это пример нарушения инкапсуляции только на уровне архитектуры всей системы, а не отдельного сервиса, когда данные оказываются оторваны от их владельцев (сервисов/модулей). За исключением случая, когда все модули/сервисы имеют изолированные таблицы/базы, которые доступны только им самим (см. предыдущий раздел).
- базы данных
- архитектура
- микросервисы
- программирование
- Программирование
- Анализ и проектирование систем
- Микросервисы
Интеграция данных

Интеграция данных (англ. — Data integration) — процесс объединения данных из различных источников для получения их согласованного представления, в широком смысле — процесс организации регулярного обмена данными между различными ИС предприятия.

Традиционная интеграция данных
Предпосылки возникновения проблемы
Проблема интеграции данных является неотъемлемым аспектом проблематики развития информационной инфраструктуры предприятия.
Исторические корни проблемы тесно переплетаются с эволюцией подходов к автоматизации бизнеса. Неавтоматизированное хранение данных не предполагало широкой постановки вопроса о их повторном использовании — для использования данных, созданных в процессе деятельности предприятия и зафиксированных в бумажной или ином неэлектронной носителе, повторно на другом участке деятельности требовалось их дублирование в нужной форме.

Первые проекты автоматизации бизнеса, технологически связанные с использованием мэйнфреймов, предполагали автоматизацию конкретных функциональных задач без задела под их расширение и интеграцию в рамках процессов предприятия. Кроме того, решения этого этапа полагались при необходимости на повторный ввод однотипных данных, как за счет доминирования унаследованного от неавтоматизированных процессов работы с данными подходов, так и за счет того, что трудозатраты на повторный ввод в денежном выражении долгое время были несравнимо ниже затрат на организацию хранения данных в машинной памяти. Не была на этом этапе широко осознана и ценность реальных данных о бизнесе, которая в настоящее время иногда оценивается как равная (или превосходящая) ценности алгоритмов их анализа. TAdviser Security 100: Крупнейшие ИБ-компании в России
По мере возникновения информационных систем, базирующихся аппаратно на миникомпьютерах и, впоследствии, ПК, расширился как круг предприятий, способных позволить себе внедрение таких систем, так и круг задач решаемых такими АИС. Однако, подавляющее превалирование логики разработчиков над логикой бизнеса и доминирующий подход по автоматизации функциональных задач, приводили к тому, что такие АИС становились участками так называемой «лоскутной» автоматизации, не предполагающей осознанного системного подхода к автоматизации бизнеса. При этом уже учитывается необходимость хранения данных конкретных АИС и их резервирования, часть систем реализуется с учетом многопользовательского доступа и на основе клиент-серверной архитектуры. Необходимость «обмена данными» между различными АИС предприятия, однако, практически не принимается в расчёт и по-прежнему в основном снимается за счет повторного ввода с редкими исключениями в виде отдельных специфичных решений.
С разрастанием участков автоматизации начинают в полной мере сказываться недостатки «лоскутной» автоматизации — отсутствие единого подхода к организации АИС, выбору платформы и инструментов, моделям организации данных приводят к нарастанию дублирования однотипных данных в различных АИС в рамках одного предприятия. Примером может служить ситуация, когда пользователь вынужден повторно вводить аналогичные или близкие данные в несколько смежных по функционалу систем. При этом организации взаимодействия систем на программном уровне часто мешает отсутствие Application Programming Interface (API). Помимо собственно роста трудозатрат на повторный ввод и нарастания рассогласованности данных в разных системах и числа ошибок, фрагментарность хранения данных приводит к отсутствию единой картины деятельности предприятия.
С появлением концепции BI и аналитических систем, в том числе, OLAP становится явной необходимость специальной подготовки данных для таких систем, обусловленная как фрагментарностью источников данных для анализа, так и особыми требованиями к организации данных для целей анализа, сформулированными Эдгаром Коддом (Edgar Codd) в рамках 12 правил OLAP, уточненными Найджелом Пендсом (Nigel Pendse) в рамках тестам FASMI и другими.
Подходы к интеграции данных
В настоящее время интеграцию данных принято делить по направлению распространения на три типа — консолидацию, федерализацию и обмен данными.
Консолидация
Консолидация — сбор данных из нескольких источников (обычно — учётных систем) в единое место хранения. Консолидированные данные чаще всего используются для целей анализа или подготовки отчётности, как, например, в случае с организацией хранилищ данных для BI. При этом специфика сбора разнородной информации из нескольких источников обсуловила ряд особенностей консолидации данных, в частности, задержку обновления данных в целевом месте хранения по сравнению с системами-источниками данных. Эта задержка вызвана как необходимостью согласования циклов обновлений в различных системах-источниках данных, так и необходимостью преобразования данных из различных форматов в формат целевого места хранения данных, которое во многих реальных приложениях является нетривиальной задачей. Для классических целей BI-приложений, небольшая задержка в обновлении данных в целевом месте хранения не являлась проблемной, так как аналитика и прогнозирование предполагали оперирование более широкими интервалами времени, нежели учетные системы. Однако, по мере появления требований к увязке бизнес-аналитики с операционным менеджментом, требования к скорости преобразования данных приобретают всё большую важность, предъявляя новые требования к технологиям, использующим консолидацию и заставляя искать альтернативные подходы.
Наиболее часто используемой технологией консолидации данных можно считать ETL (Extract Transform Load), предполагающей извлечение данных из внешних источников, их преобразование в соответствии с требованиями бизнес-модели, загрузку преобразованных данных в целевую систему. При этом современные ETL-системы под преобразованием (transformation) понимают не только техническое преобразование форматов, но и возможности унификации разнородных данных с точки зрения соответствующих регламентов, обеспечение единства применяемых систем кодирования информации, классификаторов и справочников.
Что такое интеграция баз данных? Обзор и преимущества

Каждому бизнесу необходим эффективный и надежный метод точной записи, обновления и отслеживания данных. Базы данных — одна из наиболее распространенных систем, используемых предприятиями для хранения данных о клиентах, запасах или информации о компании. Это делает интеграцию баз данных необходимой сейчас, поскольку аналитики могут интегрировать хранимые данные с другими системами, файлами или приложениями и использовать их для различных целей, таких как отчетность или анализ данных. Эффективное программное обеспечение для интеграции баз данных важно для плавной и простой интеграции и точной аналитики.
Что такое интеграция с базой данных?
Интеграция базы данных объединяет данные из разных источников для создания консолидированной версии. К этим источникам относятся базы данных, облако, хранилища данных, виртуальные базы данных, файлы и многое другое. Интеграция базы данных делает данные доступными для множества заинтересованных сторон и клиентских приложений без снижения качества данных.
Давайте разберем эту концепцию на примере. Например, компания хранит свои бухгалтерские данные в базе данных Oracle, а данные о клиентах — в базе данных Oracle. Salesforce. Используя процессы интеграции БД, сотрудники могут получить доступ к объединенным данным обеих систем в одном месте.
Ускорьте реализацию проектов по интеграции данных с помощью встроенной системы контроля версий.
Затем сотрудники смогут использовать эту информацию для получения действенной информации за меньшее время. Аналогичным образом, некоторые компании используют интеграцию веб-сайтов для управления и унификации данных с различных веб-страниц. Он воспринимает Интернет как множество разнородных баз данных.

Преимущества инструментов интеграции баз данных для бизнеса
Поскольку большие данные стимулируют бизнес-аналитику и аналитику, нельзя игнорировать важность интеграции БД для эффективного использования корпоративных данных. Таким образом, использование эффективного программного обеспечения жизненно важно для правильного управления процессами базы данных. Некоторые ключевые преимущества интеграции баз данных:
Получите больше контроля над информацией
Это позволяет вам централизованно управлять корпоративными данными или информацией. Это упрощает выявление узких мест, улучшает взаимодействие с пользователем и сокращает время доставки.
Обеспечить соблюдение правил
Соблюдение национальных и международных операционных стандартов, таких как PCI, HIPAA и GDPR, необходимо для предприятий, работающих с цифровой информацией. Интеграция базы данных обеспечивает централизованное управление, упрощая обеспечение соответствия требованиям в масштабах всей организации.
Создайте единый источник истины
Во время слияний или поглощений компании должны интегрировать свои данные, хранящиеся в разных местах, для создания единого представления. Инструменты интеграции баз данных помогают консолидировать данные из различных источников, которые очищаются, преобразуются и загружаются в нужную целевую систему(ы).
Интегрируйте данные из разрозненных источников
Интеграция данных невозможна без объединения данных из разрозненных источников – устаревших систем, облачных баз данных и локальных систем. Каждое предприятие использует различное программное обеспечение. Большая часть данных, собираемых этим программным обеспечением, находится в разрозненных системах. Для целей бизнес-аналитики (BI) и прогнозирования предприятия крайне важно консолидировать все данные в единую систему. информационное хранилище.
Автоматизируйте управление данными с помощью Astera Стек данных
Интеграция базы данных с Astera Centerprise
Комплексное решение для системы интеграции данных, Astera Centerprise позволяет пользователям соединять данные из разных источников с помощью графического пользовательского интерфейса (графического интерфейса пользователя) с помощью перетаскивания.
Платформа имеет обширные возможности, такие как:
- Встроенные преобразования.
- Предварительно построенный Разъемы для современных и традиционных источников данных.
- Планирование работы.
- Автоматизация рабочего процесса.
Эти функции поддерживают двустороннюю интеграцию между различными базами данных, такими как SQL, каждая из которых имеет свои преимущества и недостатки. Например, преимущества SQL Server перед Access — это более высокая производительность, улучшенная масштабируемость и повышенная надежность. Однако список популярных соединителей в программном обеспечении для интеграции баз данных включает:
Интеграция базы данных в среде без кода
Astera Centerprise также включает веб-сайт Интеграция данных не написав ни единой строчки кода. Это помогает объединить данные с разных веб-страниц, которые действуют как базы данных. Интеграция данных без кода также помогает снизить риск ошибок, ручных усилий и затрат на ИТ.
Удобные функции, такие как мгновенный просмотр данных, позволяют пользователям гарантировать точность сопоставления данных на каждом этапе процесса трансформации в режиме реального времени. Кроме того, это позволяет пользователям быстро выявлять ошибки и пресекать их в зародыше перед выполнением задания.
Пример интеграции базы данных: как унифицировать данные?
Astera Centerpriseведущий Инструмент ETL, обеспечивает интеграцию без кода. Это снижает риск ошибок, ручных усилий и затрат на ИТ. Вы также можете обеспечить точность сопоставления данных за счет быстрого выявления ошибок до выполнения задания.
В приведенном ниже примере интеграции данных SQL показан простой поток данных. Здесь, Оформить заказ данные из PostgreSQL интегрируются с SQL Server после применения условия к Порядок Дата с помощью преобразования «Фильтр».

Рисунок 1. Интеграция базы данных в Astera Centerprise
Условие пересылает только те записи в целевой базе данных, в которых Дата отгрузки соответствует 1997 году.

Рисунок 2: Построитель выражений
Достигните повышения производительности с помощью оптимизации с понижением
Astera Centerprise позволяет пользователям передавать задания по преобразованию данных в реляционную базу данных для достижения высокой производительности и оптимального использования ресурсов базы данных. Это действие обеспечивает экономию времени, оптимальное использование ресурсов обработки и повышение производительности разработчиков.
Astera Centerprise поддерживает два типа режимы оптимизации с понижением:
1. Режим частичной оптимизации: Команда Astera Centerprise сервер отправляет преобразование в исходную или целевую базу данных, в зависимости от поставщика базы данных или преобразования.
Например, на рисунке 3 показано выполнение задания в режиме частичной передачи вниз. Продажа данные, хранящиеся в SQL Server, агрегируются относительно Название компании. Затем он распределяется по трем отдельным файлам в зависимости от применяемых условий.

Рисунок 3. Выполнение задания в режиме частичной оптимизации.
2. Режим полной оптимизации: В этом режиме задание выполняется от начала до конца в режиме pushdown.
Поток данных ниже показывает выполнение задания в режиме полной оптимизации. Здесь данные SQL Server фильтруются относительно Страна. Затем он передается в базу данных назначения, которой также является SQL Server.

Рис. 4. Выполнение задания в режиме полной оптимизации с понижением уровня.
Обеспечьте целостность базы данных во время миграции с помощью качества данных и профилирования
Программное обеспечение для интеграции баз данных со встроенным Качество данныхФункции очистки, очистки и профилирования в единой среде упрощают создание и выполнение перенос данных проект.
Применяя правила качества данных, вы можете гарантировать достоверность и согласованность исходных данных в любой момент. Более того, используя профилирование данных, вы можете получить разбивку ваших данных с точки зрения структуры, количества ошибок, процента дублирования и т. д. Эти функции обеспечивают точность миграции вашей базы данных.
В примере ниже показана миграция Оформить заказ данные из SQL Server в PostgreSQL. Прежде чем данные будут отправлены в пункт назначения, они профилируются и сортируются на основе Идантификационный номер продукта. Данные также проверяются на наличие ошибок в Количество поле с использованием правил качества данных.

Рисунок 5. Миграция базы данных в Astera Centerprise
Улучшите методы интеграции баз данных с помощью Centerprise
Масштабный рост объема и разнообразия данных делает программное обеспечение для интеграции баз данных важным инструментом в деловом мире. Большинство предприятий терпят неудачу в проектах интеграции баз данных из-за отсутствия подходящих инструментов. Или им просто не предлагают должного решения для интеграции данных.
Предприятия осознали, что данные, интегрированные на уровне базы данных, могут значительно сэкономить время. Это может ускорить извлечение действенной информации на основе данных. Для этого им нужны инструменты интеграции для выполнения работы. Astera Centerprise упрощает процесс интеграции базы данных и предлагает постоянную поддержку!
Опыт подключения к широкому спектру баз данных
Хотите на собственном опыте убедиться, как наша унифицированная платформа упрощает интеграцию баз данных? Запросить бесплатную пробную версию и посмотрим, Astera Centerprise в действии.
Вам также может понравиться
10 лучших альтернатив матиллиону в 2024 году
Инструменты ETL стали популярными благодаря своим возможностям автоматизации и простоте использования. Они позволяют нетехническим людям создавать.
Ваше введение в аналитику маркетинговых данных
Знаете ли вы, что руководители высокопроизводительных компаний на 57% чаще корректируют долгосрочные стратегии на основе данных и.
Data Vault против Data Mesh: выбор правильной архитектуры данных
Объем данных продолжает расти, ежегодно увеличиваясь на 19.2%. Это означает, что организации должны искать способы.
принимая во внимание Astera Для ваших потребностей в управлении данными?
Установите соединение без кода с вашими корпоративными приложениями, базами данных и облачными приложениями для интеграции всех ваших данных.