Библиотеки Python с областью действия записной книжки
Библиотеки с областью действия записной книжки позволяют создавать, изменять, сохранять, повторно и совместно использовать пользовательские среды Python, относящиеся к записной книжке. При установке библиотеки с областью действия записной книжки доступ к этой библиотеке имеют только текущая записная книжка и все задания, связанные с этой записной книжкой. На другие записные книжки, подключенные к тому же кластеру, это не повлияет.
Библиотеки, область действия которых ограничена записной книжкой, не сохраняются в сеансах. Необходимо переустанавливать библиотеки, область действия которых ограничена записной книжкой, в начале каждого сеанса или при отсоединении записной книжки от кластера.
Databricks рекомендует использовать магическую %pip команду для установки библиотек Python с область записной книжкой.
Записные книжки, запланированные в качестве заданий, можно использовать %pip в записных книжках. Если вам нужно управлять средой Python в записной книжке Scala, SQL или R, используйте магическую %python команду в сочетании с %pip .
При работе с установками библиотеки область записной книжки может возникнуть больше трафика на узел драйвера. Узнайте, насколько большой узел драйвера должен быть при работе с библиотеками записных книжек область?.
Чтобы установить библиотеки для всех записных книжек, подключенных к кластеру, используйте библиотеки кластера. Дополнительные сведения см. в статье Библиотеки кластера.
В Databricks Runtime 10.5 и ниже можно использовать служебную программу библиотеки Azure Databricks. Программа библиотеки поддерживается только в Databricks Runtime, а не Databricks Runtime ML. См. служебную программу библиотеки (dbutils.library).
Управление библиотеками с помощью команд %pip
Команда %pip эквивалентна команде pip и поддерживает тот же API. В следующих разделах приведены примеры использования команд %pip для управления средой. Для получения дополнительной информации об установке пакетов Python с использованием pip см. документацию по установке pip и связанные с ней страницы.
- Начиная с команд Databricks Runtime 13.0 %pip не перезапускать процесс Python автоматически. Если вы устанавливаете новый пакет или обновляете существующий пакет, может потребоваться использовать dbutils.python.restartPython() для просмотра новых пакетов. См . статью «Перезапуск процесса Python» в Azure Databricks.
- В Databricks Runtime 12.2 LTS и ниже Databricks рекомендует размещать все %pip команды в начале записной книжки. Состояние записной книжки сбрасывается после выполнения любой команды %pip , которая изменяет среду. Если вы создаете методы или переменные Python в записной книжке, а затем используете команды %pip в более поздней ячейке, эти методы или переменные не сохраняются.
- Обновление, изменение или удаление основных пакетов Python (например, IPython) с помощью %pip может привести к тому, что некоторые функции перестанут работать должным образом. При возникновении таких проблем сбросьте среду, отключив и повторно присоединив записную книжку или перезапустив кластер.
Установка библиотеки с помощью %pip
%pip install matplotlib Установка пакета колес Python с помощью %pip
%pip install /path/to/my_package.whl Удаление библиотеки с помощью %pip
Вы не можете удалить библиотеку, включенную в заметки о выпуске Databricks Runtime, версии и совместимость или библиотеку, установленную в качестве библиотеки кластера. Если установлена версия библиотеки, отличная от версии, входящей в Databricks Runtime или установленной в кластере, можно использовать %pip uninstall для возврата библиотеки к версии по умолчанию в Databricks Runtime или версии, установленной в кластере, но нельзя использовать команду %pip для удаления версии библиотеки, входящей в Databricks Runtime или установленной в кластере.
%pip uninstall -y matplotlib Параметр -y является обязательным.
Установка библиотеки из системы управления версиями с помощью %pip
%pip install git+https://github.com/databricks/databricks-cli Вы можете добавить параметры в URL-адрес, чтобы указать такие элементы, как версия или подкаталог Git. Для получения дополнительной информации и примеров использования других систем управления версиями см. Поддержка VCS.
Установка частного пакета с учетными данными, управляемыми секретами Databricks с помощью %pip
PIP поддерживает установку пакетов из частных источников с помощью базовой аутентификации, включая закрытые системы управления версиями и закрытые репозитории пакетов, такие как Nexus и Artifactory. Управление секретами доступно через API секретов Databricks, который позволяет хранить маркеры и пароли аутентификации. Используйте DBUtils API для доступа к секретам из записной книжки. Обратите внимание, что в магических командах можно использовать $variables .
Чтобы установить пакет из частного репозитория, укажите URL-адрес репозитория с параметром —index-url до %pip install или добавьте его в файл конфигурации pip в ~/.pip/pip.conf .
token = dbutils.secrets.get(scope="scope", key="key") %pip install --index-url https://:$token@.com/ == --extra-index-url https://pypi.org/simple/ Аналогичным образом можно использовать управление секретами с помощью магических команд для установки частных пакетов из систем управления версиями.
token = dbutils.secrets.get(scope="scope", key="key") %pip install git+https://:$token@.com/ Установка пакета из DBFS с помощью %pip
С помощью %pip можно установить частный пакет, сохраненный в DBFS.
При отправке в DBFS файл автоматически переименовывается, заменяя пробелы, точки и дефисы символами подчеркивания. Для файлов pip колес Python требуется, чтобы имя файла использовало периоды в версии (например, 0.1.0) и дефисы вместо пробелов или подчеркивания, поэтому эти имена файлов не изменяются.
%pip install /dbfs/mypackage-0.0.1-py3-none-any.whl Установка пакета из тома с помощью %pip
С помощью Databricks Runtime 13.2 и более поздних версий можно установить %pip частный пакет, сохраненный в томе.
При отправке файла в том он автоматически переименовывает файл, заменяя пробелы, точки и дефисы подчеркиванием. Для файлов pip колес Python требуется, чтобы имя файла использовало периоды в версии (например, 0.1.0) и дефисы вместо пробелов или подчеркивания, поэтому эти имена файлов не изменяются.
%pip install /Volumes////mypackage-0.0.1-py3-none-any.whl Установка пакета, хранящегося в виде файла рабочей области с помощью %pip
С помощью Databricks Runtime 11.3 LTS и более поздних версий можно установить %pip частный пакет, сохраненный в виде файла рабочей области.
%pip install /Workspace//mypackage-0.0.1-py3-none-any.whl Сохранение библиотек в файле требований
%pip freeze > /dbfs/requirements.txt Все подкаталоги в пути к файлу должны уже существовать. Выполнение команды %pip freeze > /dbfs//requirements.txt завершится ошибкой, если каталог /dbfs/ еще не существует.
Использование файла требований для установки библиотек
Файл требований содержит список пакетов к установке с помощью pip . Пример использования файла требований:
%pip install -r /dbfs/requirements.txt См. Формат файла требований для получения дополнительной информации о requirements.txt файлах.
Насколько большой узел драйвера должен быть при работе с библиотеками записных книжек область?
Использование библиотек с областью записной книжки может привести к большему объему трафика на узел драйвера, так как он работает для согласования среды между узлами исполнителя.
При использовании кластера с 10 или более узлами в Databricks рекомендуется использовать следующие спецификации в качестве минимальных требований для узла драйвера:
- Для узла кластера ЦП 100 используйте Standard_DS5_v2.
- Для узла кластера GPU 10 используйте Standard_NC12.
Для кластеров большего объема используйте узел драйвера большего размера.
Можно ли использовать %sh pip , !pip или pip ? Что такое разница?
%sh и ! выполните команду оболочки в записной книжке; прежнее — это вспомогательное магическое действие Databricks, а последнее — функция IPython. pip — это сокращенное значение %pip при включении автомагии , которое используется по умолчанию в записных книжках Python Для Azure Databricks.
В Databricks Runtime 11.0 и более поздних версиях %pip , %sh pip , и !pip устанавливают библиотеку как библиотеку Python с областью действия записной книжки. В Databricks Runtime 10.4 LTS и ниже Databricks рекомендует использовать только библиотеки %pip pip с область записной книжкой. Поведение %sh pip и !pip не согласовано в Databricks Runtime 10.4 LTS и ниже.
Известные проблемы
- В Databricks Runtime 10.3 и более ранних версий библиотеки с областью действия записной книжки несовместимы с заданиями пакетной потоковой передачи. Вместо них рекомендуется использовать библиотеки кластера или ядро IPython.
Установить библиотеки из Git-репозитория
Вы можете клонировать Git-репозитории в NFS для последующей работы с нужными библиотеками из них.
Чтобы установить библиотеку из репозитория:
- Перейдите в Environments → Jupyter Servers .
- Откройте терминал в Jupyter Notebook или JupyterLab и выполните команду:
git clone
Примечание Некоторые библиотеки требуют компиляции. Например, чтобы собрать библиотеку torch-blocksparse из репозитория, необходимо выполнить команду
sudo apt-get install llvm-9-dev
Исполнение этой команды требует прав администратора на NFS, но пользователям такие права не предоставляются. Для использования sudo и работы c такими библиотеками используйте кастомные образы .
Руководство по Jupyter Notebook для начинающих
Jupyter Notebook — это мощный инструмент для разработки и представления проектов Data Science в интерактивном виде. Он объединяет код и вывод все в виде одного документа, содержащего текст, математические уравнения и визуализации.
Такой пошаговый подход обеспечивает быстрый, последовательный процесс разработки, поскольку вывод для каждого блока показывается сразу же. Именно поэтому инструмент стал настолько популярным в среде Data Science за последнее время. Большая часть Kaggle Kernels (работы участников конкурсов на платформе Kaggle) сегодня созданы с помощью Jupyter Notebook.
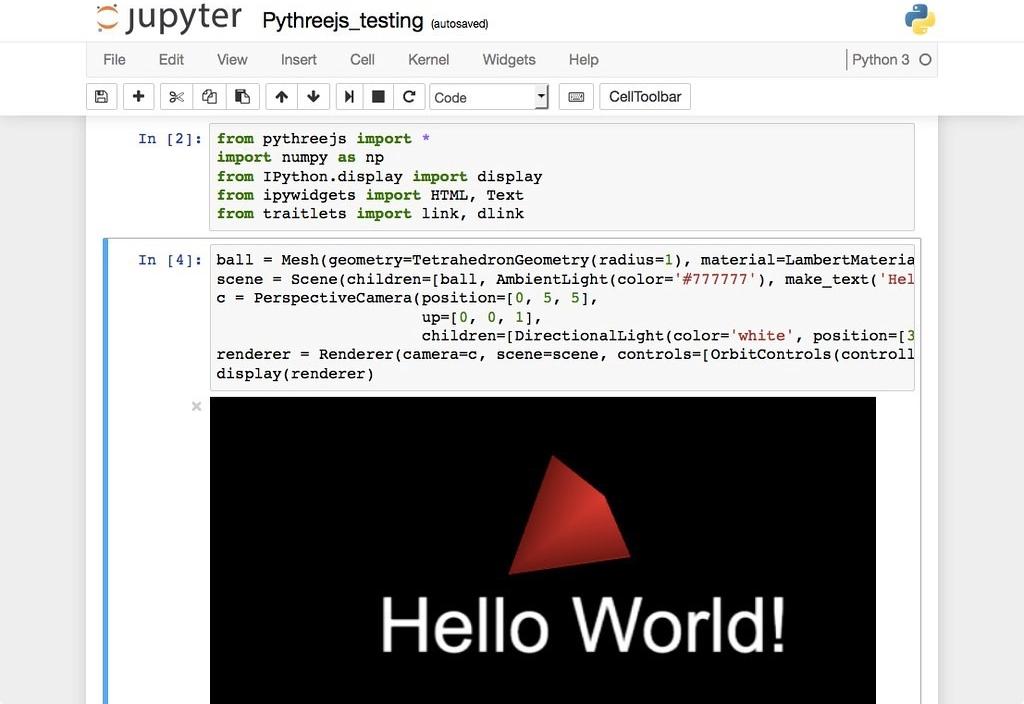
Этот материал предназначен для новичков, которые только знакомятся с Jupyter Notebook, и охватывает все этапы работы с ним: установку, азы использования и процесс создания интерактивного проекта Data Science.
Настройка Jupyter Notebook
Чтобы начать работать с Jupyter Notebook, библиотеку Jupyter необходимо установить для Python. Проще всего это сделать с помощью pip:
pip3 install jupyter Лучше использовать pip3 , потому что pip2 работает с Python 2, поддержка которого прекратится уже 1 января 2020 года.
Теперь нужно разобраться с тем, как пользоваться библиотекой. С помощью команды cd в командной строке (в Linux и Mac) в первую очередь нужно переместиться в папку, в которой вы планируете работать. Затем запустите Jupyter с помощью следующей команды:
jupyter notebook Это запустит сервер Jupyter, а браузер откроет новую вкладку со следующим URL: https://localhost:8888/tree. Она будет выглядеть приблизительно вот так:
Отлично. Сервер Jupyter работает. Теперь пришло время создать первый notebook и заполнять его кодом.
Основы Jupyter Notebook
Для создания notebook выберите «New» в верхнем меню, а потом «Python 3». Теперь страница в браузере будет выглядеть вот так:
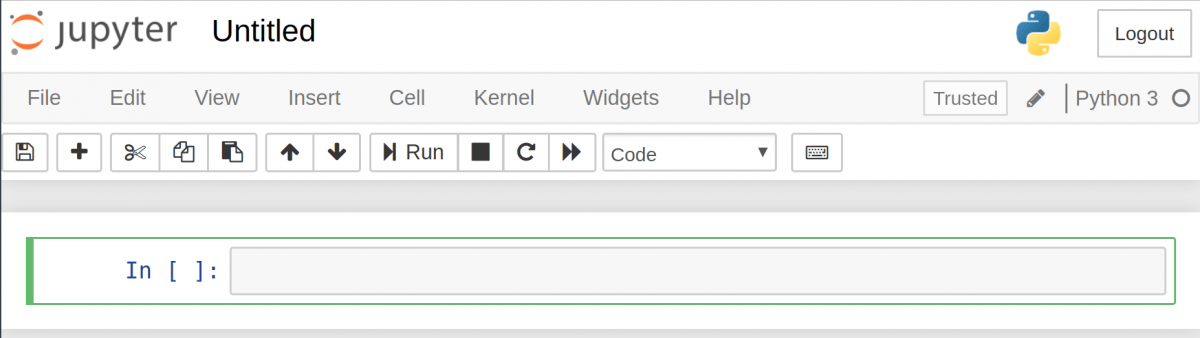
Обратите внимание на то, что в верхней части страницы, рядом с логотипом Jupyter, есть надпись Untitled — это название notebook. Его лучше поменять на что-то более понятное. Просто наведите мышью и кликните по тексту. Теперь можно выбрать новое название. Например, George’s Notebook .
Теперь напишем какой-нибудь код!
Перед первой строкой написано In [] . Это ключевое слово значит, что дальше будет ввод. Попробуйте написать простое выражение вывода. Не забывайте, что нужно пользоваться синтаксисом Python 3. После этого нажмите «Run».
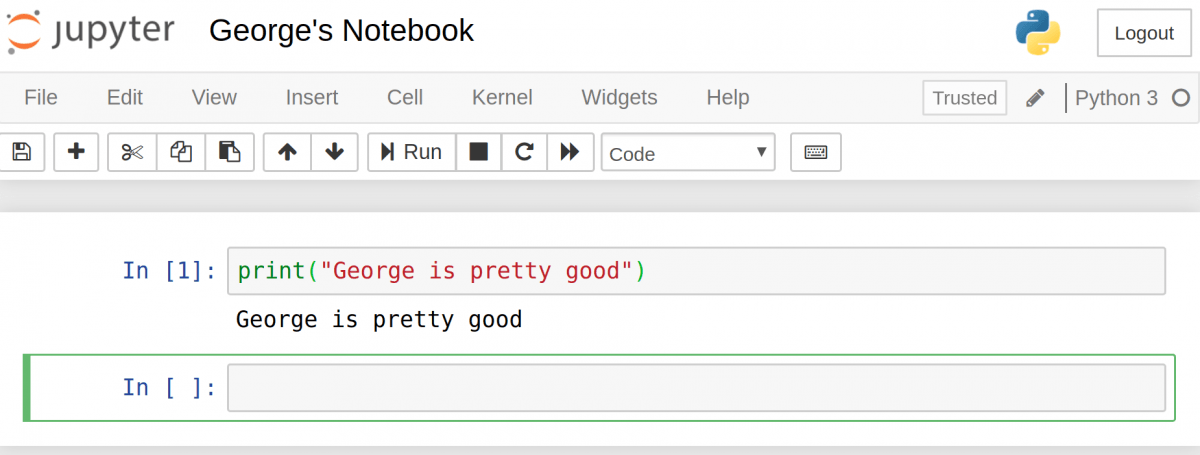
Вывод должен отобразиться прямо в notebook. Это и позволяет заниматься программированием в интерактивном формате, имея возможность отслеживать вывод каждого шага.
Также обратите внимание на то, что In [] изменилась и вместе нее теперь In [1] . Число в скобках означает порядок, в котором эта ячейка будет запущена. В первой цифра 1 , потому что она была первой запущенной ячейкой. Каждую ячейку можно запускать индивидуально и цифры в скобках будут менять соответственно.
Рассмотрим пример. Настроим 2 ячейки, в каждой из которых будет разное выражение print . Сперва запустим вторую, а потом первую. Можно увидеть, как в результате цифры в скобках меняются.
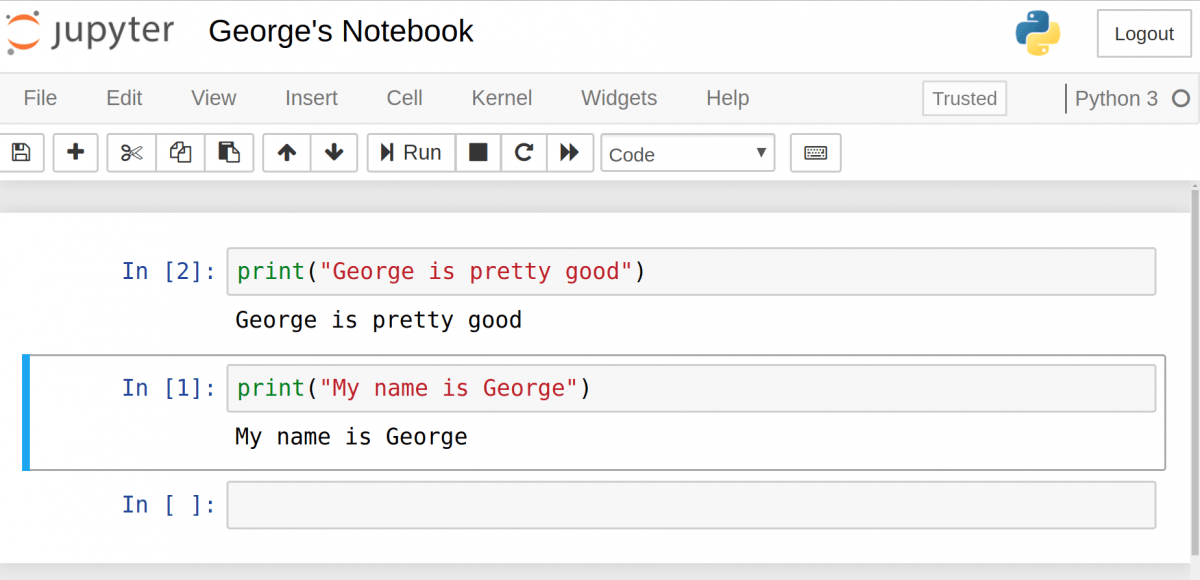
Если есть несколько ячеек, то между ними можно делиться переменными и импортами. Это позволяет проще разбивать весь код на связанные блоки, не создавая переменную каждый раз. Главное убедиться в запуске ячеек в правильном порядке, чтобы переменные не использовались до того, как были созданы.
Добавление описания к notebook
В Jupyter Notebook есть несколько инструментов, используемых для добавления описания. С их помощью можно не только оставлять комментарии, но также добавлять заголовки, списки и форматировать текст. Это делается с помощью Markdown.
Первым делом нужно поменять тип ячейки. Нажмите на выпадающее меню с текстом «Code» и выберите «Markdown». Это поменяет тип ячейки.
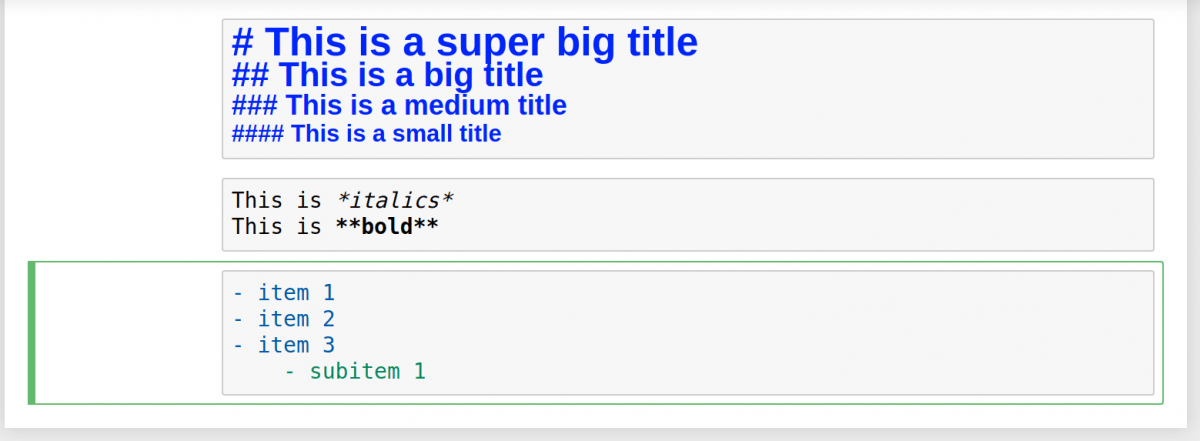
Попробуем несколько вариантов. Заголовки можно создавать с помощью символа # . Один такой символ создаст самый крупный заголовок верхнего уровня. Чем больше # , тем меньше будет текст.
Сделать текст курсивным можно с помощью символов * с двух сторон текста. Если с каждой стороны добавить по два * , то текст станет полужирным. Список создается с помощью тире и пробела для каждого пункта.
Интерактивная наука о данных
Соорудим простой пример проекта Data Science. Этот notebook и код взяты из реального проекта.
Начнем с ячейки Markdown с самым крупным текстом, который делается с помощью одного # . Затем список и описание всех библиотек, которые необходимо импортировать.
Следом идет первая ячейка, в которой происходит импорт библиотек. Это стандартный код для Python Data Science с одним исключение: чтобы прямо видеть визуализации Matplotlib в notebook, нужна следующая строчка: %matplotlib inline .

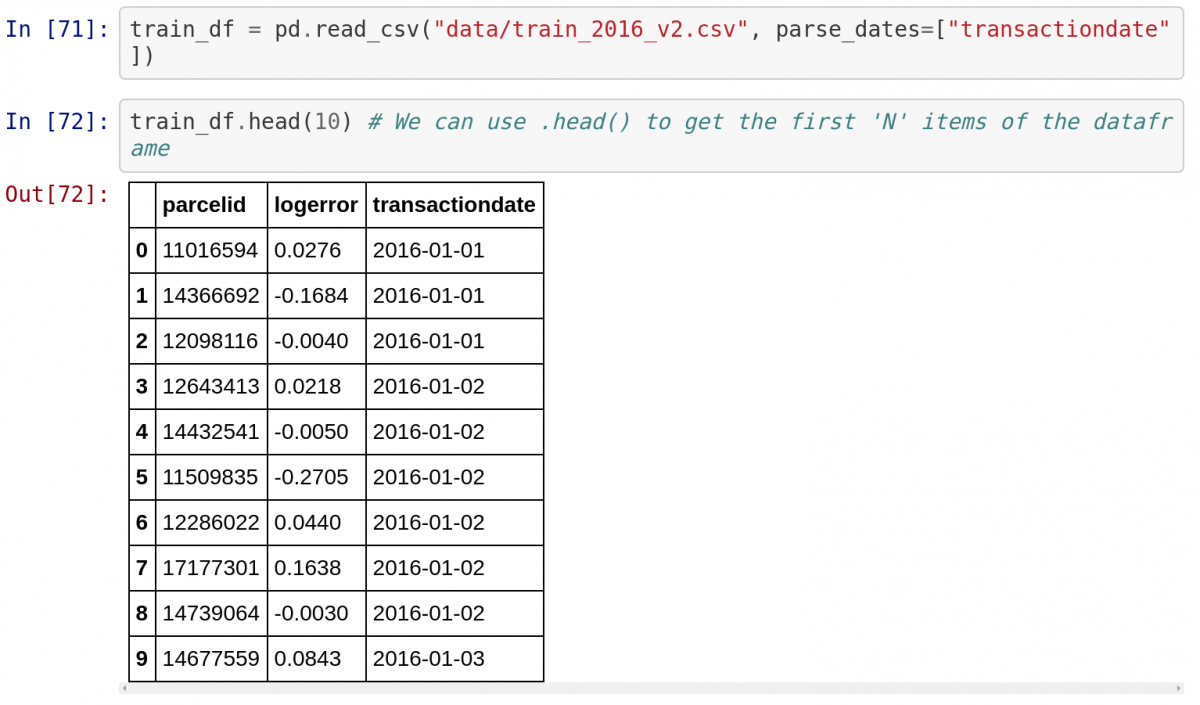
Следом нужно импортировать набор данных из файла CSV и вывести первые 10 пунктов. Обратите внимание, как Jupyter автоматически показывает вывод функции .head() в виде таблицы. Jupyter отлично работает с библиотекой Pandas!
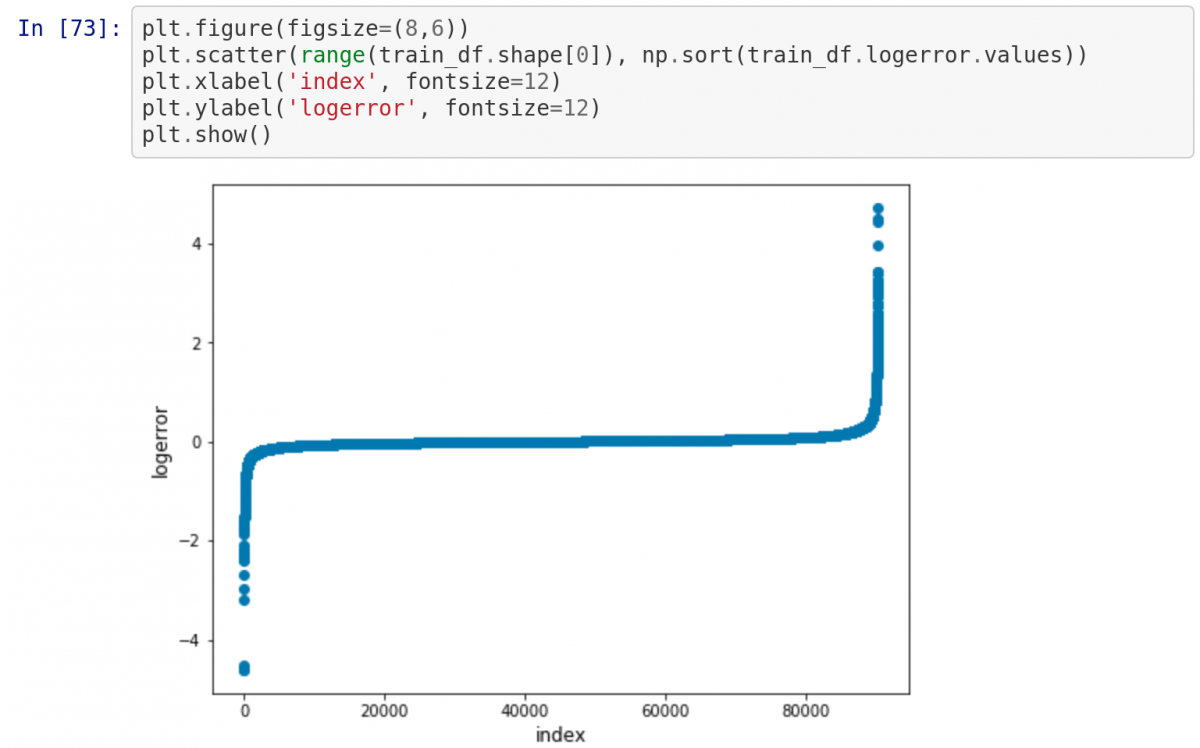
Теперь нарисуем диаграмму прямо в notebook. Поскольку наверху есть строка %matplotlib inline , при написании plt.show() диаграмма будет выводиться в notebook!
Также обратите внимание на то, как переменные из предыдущих ячеек, содержащие данные из CSV-файла, используются в последующих ячейках в том случае, если по отношению к первым была нажата кнопка «Run».
Это простейший способ создания интерактивного проекта Data Science!
Меню
На сервере Jupyter есть несколько меню, с помощью которых от проекта можно получить максимум. С их помощью можно взаимодействовать с notebook, читать документацию популярных библиотек Python и экспортировать проект для последующей демонстрации.
Файл (File): отвечает за создание, копирование, переименование и сохранение notebook в файл. Самый важный пункт в этом разделе — выпадающее меню Download , с помощью которого можно скачать notebook в разных форматах, включая pdf, html и slides для презентаций.
Редактировать (Edit): используется, чтобы вырезать, копировать и вставлять код. Здесь же можно поменять порядок ячеек, что понадобится для демонстрации проекта.
Вид (View): здесь можно настроить способ отображения номеров строк и панель инструментов. Самый примечательный пункт — Cell Toolbar , к каждой ячейке можно добавлять теги, заметки и другие приложения. Можно даже выбрать способ форматирования для ячейки, что потребуется для использования notebook в презентации.
Вставить (Insert): для добавления ячеек перед или после выбранной.
Ячейка (Cell): отсюда можно запускать ячейки в определенном порядке или менять их тип.
Помощь (Help): в этом разделе можно получить доступ к важной документации. Здесь же упоминаются горячие клавиши для ускорения процесса работы. Наконец, тут можно найти ссылки на документацию для самых важных библиотек Python: Numpy, Scipy, Matplotlib и Pandas.
Как установить NumPy
Как правило, библиотека NumPy уже предустановлена в пакете Anaconda . В тех редких случаях, когда это не так, можно воспользоваться установщиком этой сборки:
conda install -c anaconda numpy
В Jupyter Notebook это будет выглядеть так:
import sys !conda install --yes --prefix numpy
Импортирование модуля NumPy и проверка версии
Инструкция для импорта NumPy выглядит следующим образом:
import numpy as np
Данный код заменяет в пространстве имен numpy на np , что дает возможность использовать в префиксе функций, методов и атрибутов np вместо numpy . Это стандартное сокращение, которое используется во всех пособиях по NumPy.
Для проверки номера установленной версии используется следующий код:
print (np.__version__)
Output