Character, кодировки
Возможно, ты где-то уже слышал, что у каждого символа есть код (число). Именно поэтому тип char считается не только символьным, но и числовым типом.
Например код символа А английского алфавита – 65. B – 66, C – 67и так далее. Свои коды есть у больших букв и у маленьких, у русских букв, у китайских (ага, много, много кодов), у цифр, у различных символов – словом практически у всего, что можно назвать символом.
— Т.е. каждой букве или каждому символу соответствует какое-то число?
Символ можно преобразовать в число, а число в символ. Java вообще практически не видит разницы между ними:
char c = 'A'; //код(число) буквы А – 65 c++; //Теперь с содержит число 66 – код буквы B— Так вот, кодировкой называется набор символов и соответствующий им набор кодов. Только таких кодировок придумали не одну, а достаточно много. А потом появилась универсальная – Unicode.
Хотя, сколько бы универсальных стандартов не придумали, от старых никто отказываться не спешит. И все получается прямо как на этой картинке:

Вот представь, что Вася и Коля захотели самостоятельно придумать кодировки.

Вот кодировка Васи:

А вот кодировка Коли:
Они даже используют одни и те же символы, но коды у этих символов разные.

И вот когда строку «ABC-123» в кодировке Васи записывают в файл, туда пишется набор байт:
А теперь этот файл хочет прочитать другая программа, которая использует кодировку Коли:
Вот что она прочитает«345-IJK»
И самое плохое то, что обычно нигде в файле тип кодировки не хранится, и разработчикам программ приходится угадывать их.
— А как их угадывать?
— Это отдельная тема. Но я хочу тебе рассказать, как работать с кодировками. Как ты уже знаешь, размер типа char в Java – два байта. И строки в Java имеют формат Unicode.
Но Java позволяет преобразовать строку в набор байт любой известной ей кодировки. Для этого есть специальные методы у класса String(!). Также в Java есть специальный класс Charset, который описывает конкретную кодировку.
1) Как получить список всех кодировок, с которыми Java может работать?
Для этого есть специальный статический метод availableCharsets. Этот метод возвращает набор пар (имя кодировки, объект описывающий кодировку)
SortedMap charsets = Charset.availableCharsets();У каждой кодировки есть уникальное имя, вот некоторые из них: UTF-8, UTF-16, Windows-1251, KOI8-R,…
2) Как получить текущую активную кодировку (Unicode)?
Для этого есть специальный метод defaultCharset
Charset currentCharset = Charset.defaultCharset();3) Как преобразовать строку в определенную кодировку?
В Java на основе строки можно создать массив байт в любой известной Java кодировке:
byte[] getBytes()String s = "Good news everyone!"; byte[] buffer = s.getBytes()byte[] getBytes(Charset charset)String s = "Good news everyone!"; Charset koi8 = Charset.forName("KOI8-R"); byte[] buffer = s.getBytes(koi8);byte[] getBytes(String charsetName)String s = "Good news everyone!"; byte[] buffer = s.getBytes("Windows-1251")4) А как преобразовать набор байт, которые я прочитал из файла в строку, если я знаю в какой кодировке они были в файле?
Тут все еще проще – у класса String есть специальный конструктор:
String(byte bytes[])byte[] buffer = new byte[1000]; inputStream.read(buffer); String s = new String(buffer);String(byte bytes[], Charset charset)byte[] buffer = new byte[1000]; inputStream.read(buffer); Charset koi8 = Charset.forName("KOI8-R"); String s = new String(buffer, koi8);String(byte bytes[], String charsetName)byte[] buffer = new byte[1000]; inputStream.read(buffer); String s = new String(buffer, "Windows-1251");5) А как преобразовать набор байт из одной кодировки в другую?
Есть много способов. Вот тебе один из самых простых:
Charset koi8 = Charset.forName("KOI8-R"); Charset windows1251 = Charset.forName("Windows-1251"); byte[] buffer = new byte[1000]; inputStream.read(buffer); String s = new String(buffer, koi8); buffer = s.getBytes(windows1251); outputStream.write(buffer);— Я так и думал. Спасибо за интересную лекцию, Риша.
Сказ про кодировки и java
С кодировками в java плохо. Т.е., наоборот, все идеально хорошо: внутреннее представление строк – Utf16-BE (и поддержка Unicode была с самых первых дней). Все возможные функции умеют преобразовывать строку из маленького регистра в большой, проверять является ли данный символ буквой или цифрой, выполнять поиск в строке (в том числе с регулярными выражениями) и прочее и прочее. Для этих операций не нужно использовать какие-то посторонние библиотеки вроде привычных для php mbstring или iconv. Как говорится, поддержка многоязычных тестов “есть в коробке”. Так откуда берутся проблемы? Проблемы возникают, как только строки текста пытаются “выбраться” из jvm (операции вывода текста различным потребителям) или наоборот пытаются в эту самую jvm “залезть” (операция чтения данных от некоторого поставщика).
Сказка про капиталистов
Надо сказать, что unicode это не статическое образование, не принятый еще при царе горохе стандарт, который с тех пор безуспешно пытаются реализовать производители различных продуктов. Это динамический, постоянно развивающийся стандарт, с множество версий и соответствующих спецификаций. Полагаю, с тем, что для хранения текста написанного на различных языках (а для азиатов хватит и одного их родного языка) размера символа в один байт совершенно не достаточно, согласны все. Нет, чтобы взять и прикинуть, сколько там всего языков на всей планете, сколько в их алфавитах символов, сколько разных значков (нотных, графических) может потребоваться на ближайшие 100 лет. Взяли, прикинули: 1 байт – смешно, 2 уже лучше, но все равно маловато, 3 байта (примерно 16 миллионов символов уже хорошо), а если взять для представления символа все 4 байта (4 миллиарда с гаком) – то просто замечательно. Приняли бы такое решение, потом бы издали указ: мол, так и так с первого числа сего месяца начинается новые и улучшенные компьютерные времена, переделали бы все заводы по производству компьютеров, вызывали Била Гейтса на партсобрание, дали бы ценное указание и жизнь стала бы гораздо лучше. Увы, в этом жестком капиталистическом мире, на всей планете найдется всего несколько человек, которые согласятся ради возможности решить раз и навсегда все проблемы на то, чтобы объем их винчестеров и оперативной памяти уменьшится сразу в четыре раза (во сколько раз уменьшится производительность вычислений сказать тяжело – но все равно очень неслабо). Да, еще достижение всеобщего блага привело бы к полной потере всего ранее написанного софта, документов и т.д. Увы капитализм не захотел устроить всемирный субботник, а нам наследникам красного октября приходится это расхлебывать. Конечно, это шутка. Но во всякой шутке, как известно, есть доля шутки. Первая версия Unicode представляла собой кодировку, в которой каждый символ кодировался 2 байтами, для некоторых символов (наиболее часто используемых, а не всех возможных) были выделены определенные области (интервалы). Потом, с течением времени решили, что все же 64 тысяч символов будет маловато и необходим механизм хранения их большего числа. Кроме того, разработчики стандарта поняли, что в разных странах разное понятие о “букве” и все стало еще сложнее. В принципе все это написано на wikipedia, так что прекращаю рассказывать сказки, и перехожу к java, точнее к проблемам связанным с кодировками в java.
Типовые проблемы с которыми сталкиваются java-разработчики
Т.к. java приложения взаимодействуют с различными подсистемами, то и возникающие проблемы бывают разными. Хотя все, в общем случае, сводится к одной из двух проблем:
Проблема 1. Данные были успешно прочитаны, но на стадии отображения не нашлись нужные шрифты. В этом случае отсутствующие картинки шрифта заменяются на квадратики. Лечится проблема путем установки нужных шрифтов (например, при установке windows вас обычно спрашивают, хотите ли вы добавить поддержку шрифтов для азиатских языков). Есть два вида шрифтов: физические и логические. Физические шрифты – это те шрифты, файлы которых установлены либо в папку там_где_ваша_jre/lib/fonts, либо те шрифты которые установлены в стандартное место для вашей операционной системы (все версии jre обязаны поддерживать шрифты TrueType, остальные же форматы — необязательно). Логические шрифты (например, Serif, Sans-Serif, Monospaced, Dialog и DialogInput) – это правила отображения некоторых имен на реальные физические шрифты. Например, для windows логический шрифт serif это ссылка на физический times new roman. Задаются эти правила в файлах fontconfig.properties.src, fontconfig.98.properties.src, fontconfig.Me.properties.src. Для swing приложений, мы можем не только работать с идущими в самой операционной системе шрифтами, но и носить файл шрифта вместе со своим приложением, так чтобы полностью не зависеть от того, где оно будет запущено. В составе класса java.awt.GraphicsEnvironment есть несколько методов позволяющих получить информацию о том, какие шрифты доступны на вашем компьютере.
public Font [] getAllFonts ()
public abstract String [] getAvailableFontFamilyNames ()
Надо сказать, что в качестве параметра второму методу можно передать в качестве параметра объект Locale (сведения о географическом местоположении страницы, ее языке, денежных единицах …). В этом случае будут возвращены шрифты, локализованные для именно этого языка. Если же никакого параметра при вызове не указать, то вы получите список шрифтов привязанных к текущей (по-умолчанию) локали.
Для того, чтобы создать шрифт на основании некоторого файла ttf, необходимо вызвать статический метод createFont из класса Font. В качестве параметров для него следует указать файл, который содержит определение шрифта, а также указать тип этого файла (Font.TRUETYPE_FONT или Font.TYPE1_FONT). Созданный объект шрифта можно “настроить” указав для него размер или стиль (plain, italic, bold). Используйте для этого метод deriveFont.

final JFrame jf = new JFrame ( «barra» ) ;
jf.setDefaultCloseOperation ( JFrame.EXIT_ON_CLOSE ) ;
JPanel pa = new JPanel ( new GridLayout ( 0 , 1 )) ;
JLabel lab_1 = new JLabel ( «Гравитационные волны» ) ;
JLabel lab_2 = new JLabel ( «Гравитационные волны» ) ;
JLabel lab_3 = new JLabel ( «Гравитационные волны» ) ;
JLabel lab_4 = new JLabel ( «Гравитационные волны» ) ;
// используем стандартные шрифты: в первом случае логический шрифт, а во
// втором физический.
// обратите внимание, что на картинке они выглядят одинаково
lab_1.setFont ( new Font ( «Serif» , Font.PLAIN, 24 )) ;
lab_2.setFont ( new Font ( «Times New Roman» , Font.PLAIN, 24 )) ;
// теперь пробуем загрузить шрифт из внешнего файла
Font f_ye = Font.createFont ( Font.TRUETYPE_FONT, new File ( «yermak.ttf» )) ;
lab_3.setFont ( f_ye.deriveFont ( Font.PLAIN, 24.0f )) ;
// и еще один шрифт из внешнего файла
Font f_inv = Font.createFont ( Font.TRUETYPE_FONT,new File ( «invest.ttf» )) ;
lab_4.setFont ( f_inv.deriveFont ( Font.PLAIN, 24.0f )) ;
// получим и выведем в виде JComboBox список всех шрифтов
pa.add ( new JLabel ( «getAllFonts» )) ;
Font [] allFonts = java.awt.GraphicsEnvironment.getLocalGraphicsEnvironment () .getAllFonts () ;
pa.add ( new JComboBox ( allFonts )) ;
pa.add ( new JLabel ( «count fonts = » + allFonts.length )) ;
// список названий всех шрифтов доступных для текущей локали
pa.add ( new JLabel ( «getAvailableFontFamilyNames» )) ;
String [] locFontNames = java.awt.GraphicsEnvironment.
getLocalGraphicsEnvironment () .getAvailableFontFamilyNames () ;
pa.add ( new JComboBox ( locFontNames )) ;
pa.add ( new JLabel ( «count fonts = » + locFontNames.length )) ;
pa.add ( lab_1 ) ;
pa.add ( lab_2 ) ;
pa.add ( lab_3 ) ;
pa.add ( lab_4 ) ;
jf.setContentPane ( pa ) ;
jf.pack () ;
SwingUtilities.invokeLater (
new Runnable () public void run () jf.setVisible ( true ) ;
>
>
) ;
Теперь вернемся к русским буквам и java.
Вторая наиболее часто встречающаяся проблема — это неправильное преобразование кодировки. Например, вы хотите прочитать текстовый файл в кодировке windows-1251. Но при создании объекта InputStreamReader вы указали неверную кодировку (или положились на значение по-умолчанию).
InputStreamReader isr = new InputStreamReader ( new FileInputStream ( «файл_в_кодировке_1251» ) , «utf-8» )) ;
В результате при чтении файла символы будут рассматриваться как принадлежащие определенной кодовой странице. Но вовсе не факт что некоторый код символа корректный для кодировки A будет также корректен для кодировки B. В случае корректности кодов, мы увидим то, что некоторые из символов были заменены на какие-то другие символы. А вот, если код является некорректным (например, зарезервирован на будущее), то такой символ будет заменен на знак “?”.
Для получения списка всех доступных кодировок вы можете использовать следующий код (вызов статического метода Charset.availableCharsets):
SortedMap
final JList list = new JList ( charsetsMap.keySet () .toArray ()) ;
final JScrollPane pane = new JScrollPane ( list ) ;
jf.getContentPane () .add ( pane ) ;
jf.pack () ;
В папке lib есть архив charsets.jar (размером в гадкие 9 мегабайт), в котором находятся классы, управляющие преобразованием из одной кодировки в другую (например, sun\io\ByteToCharCp949.class). Логично, что наиболее частой причиной второго вида ошибок являются не отсутствующие (неизвестные java кодировки), а то, что мы просто не знаем то, в какой из кодировок пришли данные. Эту проблему можно решать различными путями, как техническими, так и административными. И хорошо еще, если мы в состоянии повлиять на тот фрагмент кода, который выполняет чтение данных из файла (конфигурационной переменной или вызовом особого метода, вроде, setCharset …). А что, если проблемный кусок кода зашит где-то глубоко внутри сторонней библиотеки, к которой у нас нет исходников или нет специалистов, способных найти “то самое глючное место и исправить его так, чтобы не рухнуло все остальное”. В том случае, если данные были прочитаны неверно, но мы знаем в какой кодировке они реально пришли и в какой кодировке их ошибочно прочитали. Тогда можно сделать попытку восстановить исходный набор символов. Основан алгоритм восстановления на двух последовательных преобразованиях: преобразовании “неправильной” строки в массив байтов (по правилам ошибочной кодировки), так мы получим данные до преобразования, а затем мы выполним правильное преобразование (в нужную кодировку).
String rightString= new String ( badString.getBytes ( «windows-1251» ) , «utf-8» ) ;
Здесь “utf-8” правильная кодировка, а “windows-1251” – неправильная.
Но предупреждаю сразу – это плохой, очень плохой способ “починить примус”. Помните, что в ходе преобразований возможна потеря символов (из-за несовместимых кодировок). Так что если вы прочитали данные из файла в неверной кодировке, то отсутствующие символы были заменены на значки вопросов. Следовательно попытка восстановить оригинальный массив байтов будет безуспешной.
Java и web.
Web – это то самое место где сталкиваются множество людей работающих под разными версиями операционных систем использующие разные браузеры и написанный нами сайт должен работать всегда и везде.
Давайте рассмотрим, как данные поступают на вход браузеру от веб-сервера и то, как браузер отправляет информацию серверу (точнее веб-приложению исполняющемуся на нем). Есть два метода для отправки запросов от браузера к веб-серверу: get и post. Остальные методы, такие как put, delete, options, доступны при использовании ajax-вызовов, а внутри компонента XmlHttpRequest выполняется конвертация отправляемых данных в “utf-8”, что сразу решает ряд проблем с неизвестными кодировками.
Самая идеальная ситуация — когда отправка идет с помощью метода POST. В этом случае браузер кодирует данные в такой же кодировке, как и в той, что была сформирована веб-страница. За кодировку возвращаемых данных отвечают либо указанная вверху jsp-файла директива:
page contentType="text/html;charset=UTF-8" language="java" pageEncoding="utf-8" %>
Первая из этих опций (contentType) указывает на кодировку выходного документа, а вторая (pageEncoding) на кодировку собственно файла в котором находится код jsp-страницы.
Либо, если вы создаете сервлет, то первым шагом нужно указать выходную кодировку документа:
public class BlaBlaServlet extends HttpServlet <
protected void doPost ( HttpServletRequest request, HttpServletResponse response )
throws ServletException, IOException <
response.setCharacterEncoding ( «utf-8» ) ;
// ну а теперь давайте работать ….
>
protected void doGet ( HttpServletRequest request, HttpServletResponse response )
throws ServletException, IOException <
doPost ( request, response ) ;
>
>
Классно, значит, если мы сформировали страницу в кодировке utf-8, то данные из формы придут к нам в формате “utf-8”. Классно, то классно, но кто сказал, что ваш веб-сервер правильно эти данные сможет раскодировать? Теоретически, когда браузер делает запрос к серверу, то отправляется не только сведения о том какой документ хочет видеть клиент, не только данные из формы, но и сведения об браузере, об поддерживаемых кодировках, об предпочитаемых языках документа, и прочее и прочее и прочее. Может там найдется сведения о кодировке? Давайте проверим. При создании тега form вы должны указать значение не только метода отправки (GET или POST), но и значение атрибута enctype. Его возможные значения: «multipart/form-data» или «application/x-www-form-urlencoded». В первом случае форма будет способна отправлять не только текстовые данные, но и, например, файлы (кто бы мне сказал, почему sun-овцы не могли реализовать парсинг подобного запроса самостоятельно или внести в стандарт для любого servlet-контейнера, а отдали на откуп посторонним?). Рассмотрим как кодируются данные в случае «multipart/form-data»? Ниже пример подобного запроса:
POST /test/servertest.jsp HTTP/1.1 Host: center:1001 Accept-Language: en,ru-ru;q=0.8,ru;q=0.5,en-us;q=0.3 Accept-Encoding: gzip,deflate Accept-Charset: windows-1251,utf-8;q=0.7,*;q=0.7 Content-Type: multipart/form-data; boundary=---------------------------265001916915724 Content-Length: 927 -----------------------------265001916915724 Content-Disposition: form-data; name="txt_1" Гравитация -----------------------------265001916915724 Content-Disposition: form-data; name="user[]" -----------------------------265001916915724 Content-Disposition: form-data; name="user[]" -----------------------------265001916915724 Content-Disposition: form-data; name="foto"; filename="" Content-Type: application/octet-stream -----------------------------265001916915724 Content-Disposition: form-data; name="pics[]"; filename="" Content-Type: application/octet-stream -----------------------------265001916915724 Content-Disposition: form-data; name="pics[]"; filename="" Content-Type: application/octet-stream -----------------------------265001916915724 Content-Disposition: form-data; name="btnsubmit" Send -----------------------------265001916915724--
Как видите, запрос разбит на секции с помощью некоторой уникальной комбинации символов. Итак, где в этом запросе есть указание на то, в какой кодировке пришли данные от браузера? Нигде, нет их. Может быть, кодировка указывается при запросе «application/x-www-form-urlencoded»? Ладно, вот пример еще одного запроса:
POST /test/servertest.jsp HTTP/1.1 Host: center:1001 User-Agent: Mozilla/5.0 (Windows; U; Windows NT 5.1; ru; rv:1.9b1) Gecko/2007110904 Firefox/3.0b1 Accept: text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8 Accept-Language: en,ru-ru;q=0.8,ru;q=0.5,en-us;q=0.3 Accept-Encoding: gzip,deflate Accept-Charset: windows-1251,utf-8;q=0.7,*;q=0.7 Keep-Alive: 300 Connection: keep-alive Content-Type: application/x-www-form-urlencoded Content-Length: 136 txt_1=%D0%A1%D0%BC%D0%B5%D1%80%D1%82%D0%BE%D0%BD%D0%BE%D1%81%D0%BD%D1%8B %D1%85+%D0%B6%D1%83%D0%BA&user%5B%5D=&user%5B%5D=&btnsubmit=Send
Способ кодирования информации отличен: прежде всего, заметьте, как были переданы русские буквы. В первом случае они передаются как есть, т.е. в той кодировке в которой была сформирована и сама страница. Во втором случае буквы превратились во множество значков процента, цифр и букв. Кодировка «application/x-www-form-urlencoded» применяется также и в случае отправки данных методом GET (передается в адресной строке).
Символы, которые не могут быть отправлены по сети (все кроме латиницы, цифр и ряда знаков), предварительно кодируются с помощью алгоритма x-www-form-urlencoded. Байты кодировки заменяются на последовательности вида %XX. Вместо XX подставляются две шестнадцатеричные цифры (http://www.faqs.org/rfcs/rfc1738). Стоп. Самый главный вопрос: x-www-form-urlencoded – это кодировка или нет? Традиционно под кодировкой понимают комбинацию набора символов и схемы кодирования. Например, когда говорят utf-8, то подразумевают схему кодирования utf-8 и набор символов Unicode, ровно, как и для utf-16. А если вы слышите windows-1251, то здесь название кодировки дано по названию набора символов. Т.к. как такового отдельного алгоритма кодирования цифры, под которой в данном наборе фигурирует, например, буква “Ы” — нет. Просто 8 бит – бери и пиши их в файл как есть, без каких-либо дополнительных преобразований. Так что x-www-form-urlencoded – это не кодировка, это способ отправить те самые байты, в которые было выполнено преобразование строки текста согласно некоторой “настоящей” кодировке (точнее схеме кодирования). Следовательно, если я открываю адрес вида: http : //Мой-сайт.ru/ящики_с_пивом
То, в зависимости от используемой кодировки, данные будут отправлены либо так:
%FF%F9%E8%EA%E8_%F1_%EF%E8%E2%EE%EC — так выглядит слово “ящики с пивом” в кодировке windows-1251
%D1%8F%D1%89%D0%B8%D0%BA%D0%B8_%D1%81_%D0%BF%D0%B8%D0%B2%D0%BE%D0%BC – а так выглядит это слово в кодировке utf-8.
Возвращаясь к анализу двух примеров запроса данных, мы нигде не видим указания на то какая кодировка используется для отправки данных. Может, у меня не правильный браузер, и какие то другие, правильные, браузеры указывают кодировку отправляемых данных? Увы, ни internet explorer 6,7 ни firefox 2,3 ни opera 9.5 не указывают сведений о кодировке.
Автоматически определить кодировку tomcat не может, а раз не может, то будет выполнять преобразование поступивших данных из кодировки (по-умолчанию) ISO8859-1. Несколько раз мне встречались в сети рекомендации делать что-то вроде:
String variableX = new String ( request.getParameter ( «fio» ) .getBytes ( «Cp1251» )) ;
Это очень плохой совет. Помните, что неправильные операции преобразования могут приводить к потере данных и, притом, необратимому. Значит, нужно подсказать tomcat-у, как правильно выполнить декодирование (а иначе, без нашего указания, он такого на раскодирует … не исправить).
Когда вызывается ваш сервлет (или jsp, что суть одно и то же). То вы можете узнать в какой кодировке к вам пришли данные, например, так:
String chenc = hreq.getCharacterEncoding () ;
Если значение кодировки null (а оно равно этой величине почти всегда), тогда tomcat решает, что входные данные были в формате ISO8859-1 и пытается именно так выполнить парсинг строки. Существует народное поверье, что если создать специальный сервлет-фильтр, который будет вызываться до того, как будет выполнено первое обращение к списку передаваемых параметров и установит значение правильной кодировки, то все заработает без проблем, например:
// выполнение фильтрации запроса
public void doFilter ( ServletRequest req, ServletResponse resp,
FilterChain chain ) throws ServletException, IOException
req.setCharacterEncoding ( «utf-8» ) ;
chain.doFilter ( req, resp ) ;
>
Теперь при первом же обращении к какому-либо из входных параметров:
fio = request.getParameter ( «fio» ) ;
Равно как и для jstl:
value="$"/>
Будет выполнено раскодирование входных данных с учетом указанной вами кодировки.
Наверное, форсировать установку значения для кодировки не всегда правильно. С другой стороны, если ваше веб-приложение содержит страницы, формируемые в разных кодировках (непонятно, правда, зачем вам это понадобилось), то можно тонко настроить шаблон для тех адресов jsp-страниц, которые будут обслуживаться этим фильтром:
MegaFilterToUTF8 /utf-8-dir/*
Можно обойтись и меньшей кровью, выполнив эту команду внутри вашего сервлета самой первой строкой кода (нужно только быть уверенным в том, что никакой другой код не пытался получить значения переменных до вас):
request.setCharacterEncoding ( «utf-8» ) ;
Или, если вы создаете jsp-файл с использованием jstl-тегов, то такую команду:
taglib prefix="fmt" uri="http://java.sun.com/jsp/jstl/fmt"%> value="utf-8"/>
Однако для того, чтобы указанное значение кодировки было применено к параметрам переданным методом GET (применительно к tomcat) нужно выполнить правку конфигурационного файла server.xml и добавить для элемента Connector атpибут useBodyEncodingForURI равный значению “true”. В этом случае разбор параметров будет выполнен с такой кодировкой, которую вы установили с помощью вызова request.setCharacterEncoding(«utf-8»).
| URIEncoding | This specifies the character encoding used to decode the URI bytes, after %xx decoding the URL. If not specified, ISO-8859-1 will be used. |
| useBodyEncodingForURI | This specifies if the encoding specified in contentType should be used for URI query parameters, instead of using the URIEncoding. This setting is present for compatibility with Tomcat 4.1.x, where the encoding specified in the contentType, or explicitely set using Request.setCharacterEncoding method was also used for the parameters from the URL. The default value is false. |
Проще говоря, либо вы указывате явно значение кодировки для всех входных запросов с помощью параметра URIEncoding (а-га, вот как будто бы всегда и для всех приложений на этом хостинге только такая кодировка является допустимой). Либо устанавливаете вторую перменную |useBodyEncodingForURI равной значению true (по-умолчанию ее значение false).
Единственная проблема в том, что мы выполнять правку файла server.xml мы можем лишь, в случае если имеем прямой доступ к каталогу, где установлен tomcat. Согласитесь, что в случае типового виртуального хостинга мы можем управлять приложением только с помощью файлов web.xml и еще META-INF/context.xml – а это не то. Также, если ваше приложение запущено под другим веб-сервером, то вам нужно будет разбираться с его специфическим настройками.
Некоторое время назад я пытался разобраться с настройками для resin. В FAQ написано, что на разбор данных оказывают влияние следующие значения:
1. request.getAttribute("caucho.form.character.encoding") 2. The response.setContentType() encoding of the page. 3. The character-encoding tag in the resin.conf.
Тег character-encoding, может быть дочерним по отношению к следующим уровням настройки: resin, server, host-default, host, web-app-default, web-app (на уровне приложения, а значит мы можем настроить свое приложение даже на самом обычном виртуальном хостинге).
xml version="1.0" encoding="UTF-8"?> xmlns="http://caucho.com/ns/resin" xmlns:resin="http://caucho.com/ns/resin/core"> utf-8
Обратите внимание на схему, которая регламентирует содержимое web.xml в следующем примере (традиционная )
version="2.4" xmlns="http://java.sun.com/xml/ns/j2ee" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://java.sun.com/xml/ns/j2ee http://java.sun.com/xml/ns/j2ee/web-app_2_4.xsd" > .
То такой пример не будет работать: т.к. тег character-encoding является специфическим именно для resin.
Если же значение кодировки явно не указано, то для чтения данных используется кодировка по-умолчанию для jvm (file.encoding). К сожалению, мои попытки запустить resin с указанием входной кодировки ничем хорошим не закончились (после установки значения кодировки в web.xml переданные рускоязычные символы превращались в черт его знает что). Так что пришлось обходиться привычным request.setCharacterEncoding (‘utf-8’); Тогда у меня было мало времени разбираться в особенностях поведения resin, также я не исключаю что это был хитрый баг, так что если у кого-то есть заметки по этому поводу, то прошу поделиться с общественностью.
Как вывод: если данные передаются методом POST, то проблем нет. Если методом GET то проблемы есть; и особенно большие проблемы в случае, если кодировки для метода GET и POST отличаются друг от друга, или некоторые GET запросы приходят в одной кодировке, а некоторые – в другой. Думаете, такого не может быть? Может. Ситуация была такова: есть сайт в кодировке utf-8 на его страницах находится множество ссылок ссылающихся на разделы этого же сайта, и, внимание, в тексте ссылок содержались русскоязычные названии (как некое подобие wikipedia). Если человек жмет на такую ссылку то адресная строка перед кодированием ее с помощью x-www-form-urlencoded, подвергалась кодированию в utf-8 (кодировку страницы). Однако если такую ссылку вводили в адресную строку браузера руками, то кодировка была windows-1251 (это для русскоязычной windows). Для linux машины, на которой стояла fedora, кодировка была utf-8. как решили проблему? Как обычно: матюгами и напильником.
A может Вас также заинтересует что-нибудь из этого:
Работа со строками

We use cookies. Read the Privacy and Cookie Policy I accept
Очень большое место в обработке информации занимает работа с текстами. Как и многое другое, текстовые строки в языке Java являются объектами. Они представляются экземплярами класса String или класса StringBuilder. В многопоточной среде вместо класса StringBuilder, не обеспечивающего синхронизацию, следует использовать класс stringBuffer, но эти вопросы мы отложим до главы 23.
Класс StringBuilder введен в стандартную библиотеку Java, начиная с версии Java SE 5, для ускорения работы с текстом в одном подпроцессе.
Все эти классы реализуют интерфейс charSequence, в котором описаны общие методы работы со строками любого типа. Таких методов немного:
? length () — возвращает количество символов в строке;
? charAt (int pos) — возвращает символ, стоящий в позиции pos строки. Символы в
строке нумеруются, начиная с нуля;
? subSequence (int start, int end) — возвращает подстроку, начинающуюся с позиции
start и заканчивающуюся перед позицией end исходной строки.
Поначалу представление строк объектами необычно и кажется слишком громоздким, но, привыкнув, вы оцените удобство работы с классами, а не с массивами символов.
Конечно, можно занести текст в массив символов типа char или даже в массив байтов типа byte, но тогда вы не сможете использовать готовые методы работы с текстовыми строками.
Зачем в язык введены три класса для хранения строк? В объектах класса String хранятся строки-константы неизменной длины и содержания, так сказать, отлитые в бронзе. Это значительно ускоряет обработку строк и позволяет экономить память. Компилятор создает только один экземпляр строки класса String и направляет все ссылки на него. Длину строк, хранящихся в объектах классов StringBuilder и StringBuffer, можно менять, вставляя и добавляя строки и символы, удаляя подстроки или сцепляя несколько строк в одну. Во многих случаях, когда надо изменить длину строки типа String, компилятор Java неявно преобразует ее к типу StringBuilder или StringBuffer, меняет длину, потом преобразует обратно в тип String. Например, следующее действие:
String s = «Это» + » одна » + «строка»;
компилятор выполнит примерно так:
String s = new StringBuffern.appendC^To’^.appendC одна «)
Будет создан объект класса StringBuffer или класса StringBuilder, в него методом append ( ) последовательно будут добавлены строки «Это», » одна «, «строка», и получившийся объект класса StringBuffer или StringBuilder будет приведен к типу String методом toString ( ).
Напомним, что символы в строках хранятся в кодировке Unicode, в которой каждый символ занимает два байта. Тип каждого символа — char.
Класс String
Перед работой со строкой ее следует создать, как и объект всякого класса. Это можно сделать разными способами.
Как создать строку
Самый простой способ создать строку — это организовать ссылку типа String на строку-константу:
String s1 = «Это строка.»;
Если константа длинная, можно записать ее в нескольких строках текстового редактора, связывая их операцией сцепления:
String s2 = «Это длинная строка типа String, » +
«записанная в двух строках исходного текста»;
Замечание
Не забывайте о разнице между пустой строкой String s = «», не содержащей ни одного символа, и пустой ссылкой String s = null, не указывающей ни на какую строку и не являющейся объектом.
Самый правильный способ создать объект с точки зрения ООП — это вызвать его конструктор в операции new. Класс String предоставляет вам более десяти конструкторов:
? String () — создается объект с пустой строкой;
? String (String str) — конструктор копирования: из одного объекта создается его точная копия, поэтому данный конструктор используется редко;
? String (StringBuffer str) -преобразованная копия объекта класса StringBuffer;
? String(StringBuilder str) — преобразованная копия объекта класса StringBuilder;
? String(byte[] byteArray) — объект создается из массива байтов byteArray;
? String (char [ ] charArray) — объект создается из массива charArray символов Unicode;
? String(byte[ ] byteArray, int offset, int count) — объект создается из части массива байтов byteArray, начинающейся с индекса offset и содержащей count байтов;
? String (char [ ] charArray, int offset, int count) — то же, но массив состоит из символов Unicode;
? String (int [ ] intArray, int offset, int count) -то же, но массив состоит из символов
Unicode, записанных в массив целого типа, что позволяет использовать символы Unicode, занимающие больше двух байтов;
? String(byte [ ] byteArray, String encoding) — символы, записанные в массиве байтов, задаются в Unicode-строке с учетом кодировки encoding;
? String(byte[] byteArray, int offset, int count, String encoding) — то же самое, но только для части массива;
? String(byte [ ] byteArray, Charset charset) — символы, записанные в массиве байтов, задаются в Unicode-строке с учетом кодировки, заданной объектом charset;
? String(byte[] byteArray, int offset, int count, Charset charset) — то же самое, но только для части массива.
При неправильном задании индексов offset, count или кодировки encoding возникает исключительная ситуация.
Конструкторы, использующие массив байтов byteArray, предназначены для создания Unicode-строки из массива байтовых ASCII-кодировок символов. Такая ситуация возникает при чтении ASCII-файлов, извлечении информации из базы данных или при передаче информации по сети.
В самом простом случае компилятор для получения двухбайтовых символов Unicode добавит к каждому байту старший нулевой байт. Получится диапазон ‘u0000’ — ‘u00FF’ кодировки Unicode, соответствующий кодам Latinl. Тексты, записанные кириллицей, будут выведены неправильно.
Если же на компьютере сделаны местные установки, как говорят на жаргоне «установлена локаль» (locale) (в MS Windows это выполняется утилитой Regional Options (Язык и стандарты) в окне Control Panel (Панель управления)), то компилятор, прочитав эти установки, создаст символы Unicode, соответствующие местной кодовой странице. В русифицированном варианте MS Windows это обычно кодовая страница CP1251.
Если исходный массив с кириллическим ASCII-текстом был в кодировке CP1251, то строка Java будет создана правильно. Кириллица попадет в свой диапазон ‘u0400’— ‘u04FF’ кодировки Unicode.
Но у кириллицы есть еще по меньшей мере четыре кодировки:
? в MS-DOS применяется кодировка CP866;
? в UNIX обычно применяется кодировка KOI8-R;
? на компьютерах Apple Macintosh используется кодировка MacCyrillic;
? есть еще и международная кодировка кириллицы ISO8859-5.
Например, байт 11100011 (0xE3 — в шестнадцатеричной форме) в кодировке CP1251 представляет кириллическую букву г, в кодировке CP866 — букву у, в кодировке KOI8-R — букву ц, в ISO8859-5 — букву у, в MacCyrillic — букву г.
Если исходный кириллический ASCII-текст был в одной из этих кодировок, а местная кодировка — CP1251, то Unicode-символы строки Java не будут соответствовать кириллице.
В этих случаях применяются последние четыре конструктора, в которых параметром encoding или charset указывается, какую кодовую таблицу использовать конструктору при создании строки.
Листинг 5.1 показывает различные случаи записи кириллического текста. В нем создаются три массива байтов, содержащих слово «Россия» в трех кодировках:
? массив byteCp1251 содержит слово «Россия» в кодировке CP1251;
? массив byteCp866 содержит слово «Россия» в кодировке CP866;
? массив byteKOI8R содержит слово «Россия» в кодировке KOI8-R.
Из каждого массива создаются по три строки с использованием трех кодовых таблиц.
Кроме того, из массива символов c[] создается строка s1, из массива байтов, записанного в кодировке CP866, создается строка s2. Наконец, создается ссылка s3 на строку-константу.
Листинг 5.1. Создание кириллических строк
null, winLikeUNIX = null null, dosLikeUNIX = null null, unixLikeUNIX = null
(byte)0xD0, (byte)0xEE, (byte)0xF1, (byte)0xF1, (byte)0xE8, (byte)0xFF
(byte)0x90, (byte)0xAE, (byte)0xE1, (byte)0xE1, (byte)0xA8, (byte)0xEF
(byte)0xF2, (byte)0xCF, (byte)0xD3, (byte)0xD3, (byte)0xC9, (byte)0xD1
String s1 = new String(c);
String s2 = new String(byteCp866); // Для консоли MS Windows
String s3 = «Россия»;
// Сообщение в Cp866 для вывода на консоль MS Windows msg = new String(» «Россия» в «.getBytes(«Cp866») , «Cp1251»); winLikeWin = new String(byteCp1251, «Cp1251»); // Правильно winLikeDOS = new String(byteCp1251, «Cp866»); winLikeUNIX = new String(byteCp1251, «KOI8-R»); dosLikeWin = new String(byteCp866, «Cp1251»); // Для консоли dosLikeDOS = new String(byteCp866, «Cp866»); // Правильно dosLikeUNIX = new String(byteCp866, «KOI8-R») ; unixLikeWin = new String(byteKOI8R, «Cp1251»); unixLikeDOS = new String(byteKOI8R, «Cp866»); unixLikeUNIX = new String(byteKOI8R, «KOI8-R») ; // Правильно
«char array : II + s1); «default encoding: II + s2); «string constant : II + s3); «Cp1251 -> Cp1251 II + winLikeWin); «Cp1251 -> Cp866 : II + winLikeDOS); «Cp1251 -> KOI8-R II + winLikeUNIX); «Cp866 -> Cp1251 II + dosLikeWin); «Cp866 -> Cp866 : II + dosLikeDOS); «Cp866 -> KOI8-R II + dosLikeUNIX); «KOI8-R -> Cp1251 II + unixLikeWin); «KOI8-R -> Cp866 : II + unixLikeDOS); «KOI8-R -> KOI8-R II + unixLikeUNIX)
Все эти данные выводятся на консоль MS Windows 2000, как показано на рис. 5.1.
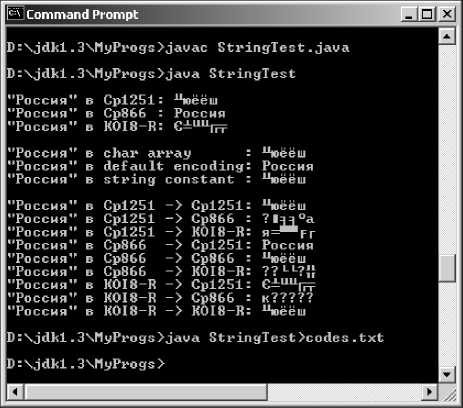
Рис. 5.1. Вывод кириллической строки на консоль MS Windows 2000
В первые три строки консоли без преобразования в Unicode выводятся массивы байтов
byteCp1251, byteCp866 и byteKOI8R. Это выполняется методом write() класса FilterOutputStream из пакета java.io.
В следующие три строки консоли выведены строки Java, полученные из массива символов c[], массива byteCp866 и строки-константы.
Далее строки консоли содержат преобразованные массивы.
Вы видите, что на консоль правильно выводится только массив в кодировке CP866, записанный в строку с использованием кодовой таблицы CP1251. В чем дело? Здесь свой вклад в проблему русификации вносит вывод потока символов на консоль или в файл.
Как уже упоминалось в главе 1, в консольное окно Command Prompt операционных систем MS Windows текст выводится в кодировке CP866.
Для того чтобы учесть это, слова «»Россия» в» преобразованы в массив байтов, содержащий символы в кодировке CP866, а затем переведены в строку msg.
В предпоследней строке рис. 5.1 сделано перенаправление вывода программы в файл codes.txt. В MS Windows вывод текста в файл происходит в кодировке CP1251. На рис. 5.2 показано содержимое файла codes.txt в окне программы Notepad (Блокнот).
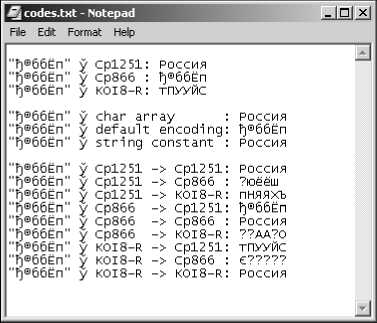
Рис. 5.2. Вывод кириллической строки в файл
Как видите, кириллица выглядит совсем по-другому. Правильные символы Unicode кириллицы получаются, если использовать ту же кодовую таблицу, в которой записан исходный массив байтов.
Вопросы русификации мы еще будем обсуждать в главах 9 и 24, а пока заметьте, что при создании строки из массива байтов лучше указывать ту же самую кириллическую кодировку, в которой записан массив. Тогда вы получите строку Java с правильными символами Unicode.
При выводе же строки на консоль, в окно, в файл или при передаче по сети лучше преобразовать строку Java с символами Unicode по правилам вывода в нужное место.
Еще один способ создать строку — это использовать два статических метода:
copyValueOf(char[] charArray, int offset, int length);
Они формируют строку по заданному массиву символов и возвращают ее в качестве результата своей работы. Например, после выполнения следующего фрагмента программы
String s1 = String.copyValueOf(c);
String s2 = String.copyValueOf(c, 3, 7);
получим в объекте s1 строку «Символьный», а в объекте s2-строку «вольный».
Упражнение
1. Потренируйтесь в преобразованиях строки в массивы байтов с разной кириллической кодировкой.
Сцепление строк
Со строками можно производить операцию сцепления строк (concatenation), обозначаемую знаком плюс (+). Эта операция создает новую строку, просто составленную из состыкованных первой и второй строк, как показано в начале данной главы. Ее можно применять и к константам, и к переменным. Например:
String attention = «Внимание: «;
String s = attention + «неизвестный символ»;
Вторая операция — присваивание += — применяется к переменным в левой части:
Поскольку операция + перегружена со сложения чисел на сцепление строк, встает вопрос о приоритете этих операций. У сцепления строк приоритет выше, чем у сложения, поэтому записав «2» + 2 + 2, получим строку «222». Но записав 2 + 2 + «2», получим строку «42», поскольку действия выполняются слева направо. Если же запишем «2» + (2 + 2), то получим «24».
Кроме операции сцепления соединить строки можно методом concat (), например:
String s = attention.concat(«иеизвестиый символ»);
Как узнать длину строки
Для того чтобы узнать длину строки, т. е. количество символов в ней, надо обратиться к методу length ( ):
String s = «Write once, run anywhere.»; int len = s.length();
int len = «Write once, run anywhere.».length();
поскольку строка-константа — полноценный объект класса String.
Заметьте, что строка — это не массив, у нее нет поля length.
Внимательный читатель, изучивший рис. 4.7, готов со мной не согласиться. Ну что же, действительно, символы хранятся в массиве, но он закрыт, как и все поля класса String.
Логический метод isEmpty(), появившийся в Java SE 6, возвращает true, если строка пуста, в ней нет ни одного символа.
Как выбрать символы из строки
Выбрать символ с индексом ind (индекс первого символа равен нулю) можно методом charAt(int ind). Если индекс ind отрицателен или не меньше, чем длина строки, возникает исключительная ситуация. Например, после определения
char ch = s.charAt(3);
переменная ch будет иметь значение ‘t’ .
Все символы строки в виде массива символов можно получить методом toCharArray( ).
Если же надо включить в массив символов dst, начиная с индекса ind массива, подстроку от индекса begin включительно до индекса end исключительно, то используйте метод
getChars(int begin, int end, char[] dst, int ind) типа void. В массив будет записано end — begin символов, которые займут элементы массива, начиная с индекса ind до индекса ind + (end — begin) — 1.
Этот метод создает исключительную ситуацию в следующих случаях:
? ссылка dst == null;
? индекс begin отрицателен;
? индекс begin больше индекса end;
? индекс end больше длины строки;
? индекс ind отрицателен;
? ind + (end — begin) больше dst.length.
Например, после выполнения
«Пароль легко иайти».getChars(2, 8, ch, 2);
результат будет таков:
Если надо получить массив байтов, содержащий все символы строки в байтовой кодировке ASCII, то используйте метод getBytes (). Этот метод при переводе символов из Unicode в ASCII использует локальную кодовую таблицу.
Если же надо получить массив байтов не в локальной кодировке, а в какой-то другой, применяйте метод getBytes (String encoding) или метод getBytes (Charset encoding).
Так сделано в листинге 5.1 при создании объекта msg. Строка «»Россия в»» перекодировалась в массив СР866-байтов для правильного вывода кириллицы в консольное окно Command Prompt операционных систем MS Windows.
Как выбрать подстроку
Метод substring (int begin, int end) выделяет подстроку от символа с индексом begin включительно до символа с индексом end исключительно. Длина подстроки будет равна end — begin. Индекс можно задать любым целым типом, кроме типа long.
Метод substring ( int begin) выделяет подстроку от индекса begin включительно до конца строки.
Если индексы отрицательны, индекс end больше длины строки или begin больше, чем end, то возникает исключительная ситуация.
Например, после выполнения следующего фрагмента
String s = «Write once, run anywhere.»;
String sub1 = s.substring(6, 10);
String sub2 = s.substring(16);
получим в строке sub1 значение «once», а в sub2-значение «anywhere.».
Как разбить строку на подстроки
Метод split (String regExp) разбивает строку на подстроки, используя в качестве разделителей символы, входящие в параметр regExp, записывает подстроки в массив строк и возвращает ссылку на этот массив. Сами разделители не входят ни в одну подстроку.
Например, после выполнения следующего фрагмента
String s = «Write:once,:run:anywhere.»;
String[] sub = s.split(«:»);
получим в строке sub[0] значение «Write», в строке sub[1] значение «once,», в строке sub[2] значение «run», а в sub[3] — значение «anywhere.».
Метод split(String regExp, int n) разбивает строку на n подстрок. Если параметр n меньше числа подстрок, то весь остаток строки заносится в последний элемент создаваемого массива строк. Применение метода
String[] sub = s.split(«:», 2);
в предыдущем примере даст массив sub из двух элементов со значением sub[0], равным
«Write», и значением sub[1], равным «once, :run:anywhere.».
Разбить строку можно практически на любые подстроки, поскольку значением параметра regExp может быть любое регулярное выражение. Регулярное выражение (regular expression) — это шаблон для отбора строк, составляемый по сложным правилам, изложению которых посвящены целые книги. Регулярные выражения выходят за рамки нашей книги, но все-таки я приведу пример разбиения строки на слова, разделенные пробельными символами:
String[] word = s.split(«s+»);
Как сравнить строки
Операция сравнения == сопоставляет только ссылки на строки. Она выясняет, указывают ли ссылки на одну и ту же строку. Например, для строк
String si = «Какая-то строка»;
String s2 = «Другая строка»;
сравнение s1 == s2 дает в результате false.
Значение true получится, только если обе ссылки указывают на одну и ту же строку, например после присваивания s1 = s2.
Интересно, что если мы определим s3 так:
String s3 = «Какая-то строка»;
то сравнение s1 == s3 даст в результате true, потому что компилятор устроен так, что он создаст только один экземпляр константы «Какая-то строка» и направит на него все ссылки — и ссылку s1, и ссылку s3. Это не приводит к недоразумениям, поскольку строка типа String неизменяема.
Вы, разумеется, хотите сравнивать не ссылки, а содержимое строк. Для этого есть несколько методов.
Логический метод equals(Object obj), переопределенный из класса Object, возвращает true, если параметр obj не равен null, является объектом класса String, и строка, содержащаяся в нем, полностью идентична данной строке вплоть до совпадения регистра букв. В остальных случаях возвращается значение false.
Логический метод equalsIgnoreCase(Object obj) работает так же, но одинаковые буквы, записанные в разных регистрах, считаются совпадающими.
Например, s2.equals(«другая строка») даст в результате false, а s2.equalsIgnoreCase( «другая строка» ) возвратит true.
Метод compareTo (String str) возвращает целое число типа int, вычисленное по следующим правилам:
1. Сравниваются символы данной строки this и строки str с одинаковым индексом, пока не встретятся различные символы с индексом, допустим, k или пока одна из строк не закончится.
2. В первом случае возвращается значение this.charAt(k) — str.charAt(k), т. е. разность кодировок Unicode первых несовпадающих символов.
3. Во втором случае возвращается значение this.length() — str.length(), т. е. разность длин строк.
4. Если строки совпадают, возвращается 0.
Если значение str равно null, возникает исключительная ситуация.
Нуль возвращается в той же ситуации, в которой метод equals () возвращает true.
Метод compareToIgnoreCase (String str) производит сравнение без учета регистра букв, точнее говоря, выполняется метод
Эти методы не учитывают алфавитное расположение символов в локальной кодировке.
Русские буквы расположены в Unicode по алфавиту, за исключением одной буквы. Заглавная буква Ё находится перед всеми кириллическими буквами, ее код ‘u0401’, а строчная буква ё — после всех русских букв, ее код ‘u0451’.
Если вас такое расположение не устраивает, задайте свое размещение букв с помощью класса RuleBasedCollator из пакета java.text.
Сравнить подстроку данной строки this с подстрокой той же длины len другой строки str можно логическим методом
regionMatches(int ind1, String str, int ind2, int len);
Здесь ind1 — индекс начала подстроки данной строки this, ind2 — индекс начала подстроки другой строки str. Результат false получается в следующих случаях:
? хотя бы один из индексов ind1 или ind2 отрицателен;
? хотя бы одно из ind1 + len или ind2 + len больше длины соответствующей строки;
? хотя бы одна пара символов не совпадает.
Этот метод различает символы, записанные в разных регистрах. Если надо сравнивать подстроки без учета регистров букв, то используйте логический метод:
regionMatches(boolean flag, int ind1, String str, int ind2, int len);
Если первый параметр flag равен true, то регистр букв при сравнении подстрок не учитывается, если false — учитывается.
Как найти символ в строке
Поиск всегда ведется с учетом регистра букв.
Первое появление символа ch в данной строке this можно отследить методом indexOf(int ch), возвращающим индекс этого символа в строке или -1, если символа ch в строке this нет.
Например, «Молоко».^ехО^ ‘о’) выдаст в результате индекс 1.
Конечно, этот метод реализован так, что он выполняет в цикле последовательные сравнения this. charAt (k++) == ch, пока не получит значение true.
Второе и следующие появления символа ch в данной строке this можно отследить методом indexOf(int ch, int ind). Этот метод начинает поиск символа ch с индекса ind. Если ind < 0, то поиск идет с начала строки, если ind больше длины строки, то символ не ищется, т. е. возвращается -1.
Например, «Молоко».^ех0^’о’, indexOf (‘о’) + 1) даст в результате индекс 3.
Последнее появление символа ch в данной строке this отслеживает метод lastIndexOf(int ch). Он просматривает строку в обратном порядке. Если символ ch не найден, возвращается -1.
Например, «Молоко».lastIndexOf( ‘о’) даст в результате индекс 5.
Предпоследнее и предыдущие появления символа ch в данной строке this можно отследить методом lastIndexOf(int ch, int ind), который просматривает строку в обратном порядке, начиная с индекса ind. Если ind больше длины строки, то поиск идет от конца строки; если ind < 0, то возвращается -1.
Как найти подстроку
Поиск всегда ведется с учетом регистра букв.
Первое вхождение подстроки sub в данную строку this отыскивает метод indexOf(String sub). Он возвращает индекс первого символа первого вхождения подстроки sub в строку или -1, если подстрока sub не входит в строку this. Например, «Раскраска» . indexOf («рас») даст в результате 4.
Если вы хотите начать поиск не с начала строки, а с какого-то индекса ind, используйте метод indexOf (String sub, int ind). Если ind < 0, то поиск идет с начала строки; если ind больше длины строки, то символ не ищется, т. е. возвращается -1.
Последнее вхождение подстроки sub в данную строку this можно отыскать методом lastIndexOf(String sub), возвращающим индекс первого символа последнего вхождения подстроки sub в строку this или -1, если подстрока sub не входит в строку this.
Последнее вхождение подстроки sub не во всю строку this, а только в ее начало до индекса ind можно отыскать методом lastIndexOf(String str, int ind). Если ind больше длины строки, то поиск идет от конца строки; если ind < 0, то возвращается -1.
Для того чтобы проверить, не начинается ли данная строка this с подстроки sub, используйте логический метод startsWith(String sub), возвращающий true, если данная строка this начинается с подстроки sub или совпадает с ней, или подстрока sub пуста.
Можно проверить и появление подстроки sub в данной строке this, начиная с некоторого индекса ind логическим методом startsWith(String sub, int ind). Если индекс ind отрицателен или больше длины строки, возвращается false.
Для того чтобы проверить, не заканчивается ли данная строка this подстрокой sub, используйте логический метод endsWith(String sub). Учтите, что он возвращает true, если подстрока sub совпадает со всей строкой или подстрока sub пуста.
Например, if (fileName.endsWith(«.java») ) отследит имена файлов с исходными текстами Java.
Перечисленные ранее методы создают исключительную ситуацию, если sub == null.
Если вы хотите осуществить поиск, не учитывающий регистр букв, измените предварительно регистр всех символов строки.
Как изменить регистр букв
Метод toLowerCase () возвращает новую строку, в которой все буквы переведены в нижний регистр, т. е. сделаны строчными.
Метод toUpperCase () возвращает новую строку, в которой все буквы переведены в верхний регистр, т. е. сделаны прописными.
При этом используется локальная кодовая таблица по умолчанию. Если нужна другая локаль, то применяются методы
toLowerCase(Locale loc); toUpperCase(Locale loc);
Как заменить отдельный символ
Метод replace (char old, char new) возвращает новую строку, в которой все вхождения символа old заменены символом new. Если символа old в строке нет, то возвращается ссылка на исходную строку.
Например, после выполнения «Рука в руку сует хлеб».гер1асе(‘у’, ‘е’) получим новую строку «Река в реке сеет хлеб».
Регистр букв при замене учитывается.
Как заменить подстроку
Метод replace (String old, String new) возвращает новую строку, в которой все вхождения подстроки old заменены строкой new. Если подстроки old в исходной строке нет, то возвращается ссылка на исходную строку.
Метод replaceAll (String oldRegEx, String new) возвращает новую строку, в которой все вхождения подстроки oldRegEx заменены строкой new. Если подстроки old в исходной строке нет, то возвращается ссылка на исходную строку. В отличие от предыдущего метода аргументом oldRegEx может служить регулярное выражение, пользуясь которым можно сделать очень сложную замену.
Метод replaceFirst (String oldRegEx, String new) возвращает новую строку, в которой сделана только одна, первая, замена.
Регистр букв при замене учитывается.
Как убрать пробелы в начале и конце строки
Метод trim () возвращает новую строку, в которой удалены начальные и конечные символы с кодами, не превышающими ‘u0020’.
Как преобразовать в строку данные другого типа
В языке Java принято соглашение — каждый класс отвечает за преобразование других типов в тип данного класса и должен содержать нужные для этого методы.
Класс String содержит восемь статических методов valueOf(type elem) преобразования в строку примитивных типов boolean, char, int, long, float, double, массива char [] и просто объекта типа Obj ect.
Девятый метод valueOf(char[] ch, int offset, int len) преобразует в строку подмассив массива ch, начинающийся с индекса offset и имеющий len элементов.
Кроме того, в каждом классе есть метод toString(), переопределенный или просто унаследованный от класса Obj ect. Он преобразует объекты класса в строку. Фактически метод valueOf () вызывает метод toString() соответствующего класса. Поэтому результат преобразования зависит от того, как реализован метод toString ().
Еще один простой способ — сцепить значение elem какого-либо типа с пустой строкой: «» + elem. При этом неявно вызывается метод elem.toString( ).
Упражнения
2. Подсчитайте количество появлений того или иного символа в заданной строке.
3. Подсчитайте количество слов в заданной строке.
4. Найдите число появлений заданного слова в заданной строке.
В какой кодировке хранятся строки в java
Наверно, ни для кого не является секретом, что строки в Java представлены в виде массива символов char[]. При этом каждый символ в памяти занимает 2 байта (16 бит), т.к. Java использует кодировку UTF-16.
Например, если строка содержит слово на английском языке, то 8 первых бит у каждого символа будут равны 0, поскольку символ ASCII может быть представлен одним байтом вместо двух.
Многим символам необходимо 16 бит для их представления, но по статистике для большинства данных требуется только 8 бит, представленных символами LATIN-1. Исходя из этого можно попробовать улучшить потребление памяти и производительность.
Также важно то, что строки обычно занимают большую часть пространства кучи JVM. И, как сказано выше, в большинстве случаев они могут занимать места в два раза больше, чем им в действительности необходимо.
В этой статье мы обсудим опцию Compressed String (сжатая строка), представленную в JDK 6, и новую Compact String (компактную строку), появившуюся в JDK 9. Обе опции были разработаны для оптимизации потребления памяти строками в JVM.
2. Сжатие строк в Java 6
В JDK 6 в 21 обновлении была представлена новая опция для JVM:
-XX: + UseCompressedStrings
Когда эта опция включена, строки хранятся не как char[], а как byte[], что экономит много памяти. Однако эта опция была в конечном итоге удалена в JDK 7 из-за непредсказуемых последствий для производительности.
3. Компактные строки в Java 9
В Java 9 вернули концепцию компактных строк.
Это означает, что всякий раз, когда мы создаем строку символы которой могут быть представлены с использованием одного байта – в LATIN-1, то для хранения строк будет использоваться байтовый массив. Но, если какой-либо символ требует более 8 бит для своего представления, то каждый символы сроки будет занимать два байта (UTF-16).
Теперь вопрос — как будут работать все операции со строками? Как будут различаться кодировки строк?
Для решения этой проблемы было внесено ещё одно изменение во внутреннюю реализацию String. Теперь данный класс содержит поле private final byte coder, которое хранит эту информацию.
3.1 Реализация строк в Java 9
До сих пор строка хранилась, как массив символов char[]:
private final char[] value;
Теперь это массив байт byte[]:
private final byte[] value;
Идентификатор, отвечающий за кодировку coder :
private final byte coder;
При этом идентификатор поддерживает следующие значения:
static final byte LATIN1 = 0; static final byte UTF16 = 1;
Большинство методов класса String теперь проверяют поле coder и в зависимости от его значения использую разную реализацию:
public int indexOf(int ch, int fromIndex) < return isLatin1() ? StringLatin1.indexOf(value, ch, fromIndex) : StringUTF16.indexOf(value, ch, fromIndex); >private boolean isLatin1()
Для отключения компактных строк существует опция:
+XX:-CompactStrings
3.2. Как работает coder
В реализации класса String в Java 9 длина вычисляется так:
public int length () < return value.length >> coder; >
Если строка содержит только LATIN-1, значение кодировщика будет равно 0, поэтому длина строки будет равна длине байтового массива.
Если строка представлена в виде UTF-16, то значение кодировщика будет равно 1, и, следовательно, длина будет вдвое меньше размера фактического байтового массива.
4. Compact Strings vs. Compressed String
В Compressed Strings в JDK 6 основной проблемой было то, что конструктор String принимал в качестве аргумента только массив символов char[] не смотря на то, что многие операции со String зависят от представления char[], а не от байтового массива. Из-за этого приходилось производить распаковку, что сказывалось на производительности.
Обратите внимание, что в случае Compact String содержание дополнительного поля coder также может увеличить нагрузку. Чтобы снизить «стоимость» кодера и распаковку байтов в символы (в случае представления UTF-16), некоторые методы являются встроенными, и код ASM, сгенерированный компилятором JIT, также был улучшен.

Эти изменение привели к некоторым неожиданным результатам. LATIN-1 indexOf(String) вызывает встроенный метод, тогда как indexOf(char) — нет. В случае UTF-16 оба эти метода вызывают встроенный метод. Эта проблема касается только строки LATIN-1 и будет исправлена в будущих выпусках.
Таким образом, с точки зрения производительности, компактные строки Compact Strings лучше, чем сжатые строки Compressed Strings.
Чтобы узнать, сколько памяти сохранено с помощью Compact Strings, были проанализированы различные дампы кучи (heap) Java-приложений. И, хотя результаты сильно зависели от конкретных приложений, общие улучшения были почти всегда значительными.
4.1. Различия в производительности
Давайте рассмотрим очень простой пример, демонстрирующий разницу в производительности между включенным и отключенным Compact Strings:
package ru.topjava; import java.util.List; import java.util.stream.Collectors; import java.util.stream.IntStream; public class CompactStringTest < public static void main(String[] args) < long startTime = System.currentTimeMillis(); Liststrings = IntStream.rangeClosed(1, 100_000) .mapToObj(Integer::toString) .collect(Collectors.toList()); long totalTime = System.currentTimeMillis() - startTime; System.out.println("Generated " + strings.size() + " strings in " + totalTime + " ms."); startTime = System.currentTimeMillis(); String appended = strings.stream() .reduce("", (l, r) -> l + r); totalTime = System.currentTimeMillis() - startTime; System.out.println("Created string of length " + appended.length() + " in " + totalTime + " ms."); > >