Как скачать файлы с сайта через код страницы.
Мне нужно скачать около трехсот png (единый pdf сайт не дает) и при этом не тыкать на каждый пкм -> открыть в новой вкладке и скачать. Они не выделяются.
Голосование за лучший ответ
Есть программы граббер сайта …используй их))
Ссылку на сайт с этими картинками можно?
Андрей КейльЗнаток (487) 2 года назад
Это сайт типографии учебника, злые люди не дают учебник (только купить доступ на год за 150 рублей онлайн, скачать его нельзя)
Lame Wolf Искусственный Интеллект (355791) Андрей Кейль, Мне насрать кто там не дает тебе книги! Тебя просили ссылку на сайт!
На странице с нужными картинками:
ПКМ — Сохранить как html
Затем посмотреть любым текстовым редактором (например Notepad++) на наличие ссылок на картинки.
Если таковые имеются, то попытаться найти все такие (см. скриншот 1)
Ещё немного терпения… Может быть какие-то дополнительные условия… Может быть с помощью макросов… Получим голый список (см. скриншот 2)
Сохранить его в файл и с помощью какой-нибудь утилитки типа WGET (https://eternallybored.org/misc/wget/) и скармливаем ему этот файлик…
Но это при условии, что нужные картинки именно в html присутствуют. Динамические сайты не всегда это дают.
Прячут картинки за своими движками… ;–)


Как утащить простой сайт за 5 минут
Когда начинаешь практиковаться в вёрстке сайтов, может быть очень полезно разобраться, как устроены сайты у других ребят. Вот как это сделать.
�� Всё, что мы делаем в этой статье, мы делаем в учебных целях. Если вы просто скопируете себе чужой сайт и будете выдавать его за свой, это может плохо кончиться.
�� На самом деле всё сказанное в этой статье нужно для тех, кто боится отключения интернета и хочет сохранить у себя на компьютере самую важную информацию. Но эта мысль бредовая сразу на стольких уровнях, что мы стесняемся её произносить вслух. Разве что шёпотом.
В чём идея
Мы будем копировать чужой сайт, чтобы его можно было запустить на своём сервере или на домашнем компьютере. Задача — не просто открыть сайт в браузере и посмотреть его код, а забрать из него все важные файлы — и стили, и скрипты, и изображения. Чтобы было проще, мы будем практиковаться на одностраничном сайте, но всё то же самое будет работать и на многостраничном.
❌ Мы не сможем утащить чужие PHP-скрипты и страницы, связанные с данными пользователя (например, не сможем утащить из интернет-магазина рабочую версию корзины с покупками). Для этого нужен доступ к файлам сервера, а этого у нас нет.
Главный принцип этой работы: когда ваш браузер запрашивает страницу чужого сайта, веб-сервер отправляет ему эту страницу, в буквальном смысле. То же с картинками, стилями и скриптами: каждый раз, когда вы посещаете сайт, вы как будто делаете его копию у себя на компьютере. Браузер получает страницу от сервера и выводит её копию на экран, а в памяти держит исходный код. Разве что он не сохраняет эту страницу на диск, чтобы вы могли её редактировать.
Вот этот последний этап мы и исправим: теперь мы будем сохранять чужие сайты к себе на диск.
Весь процесс покажем на примере сайта ux-posters.ru – простом одностраничном сайте, где есть картинки, стили и скрипты. Автору этого текста пришлось помогать авторам этого сайта с похожей задачей, так что пример свеженький.
Быстрый путь: грабберы
Есть категория программ под названием «веб-грабберы», или «веб-рипперы». Они работают так:
- Ты говоришь программе, на какую страницу сайта зайти.
- Программа собирает все ссылки с этой страницы, переходит по этим ссылкам и строит себе виртуальную карту сайта — то есть пытается понять, сколько на этом сайте страниц и как они связаны.
- Потом граббер начинает ползать по этим страницам подряд, запрашивать их у сервера, получать ответы и сохранять ответы на вашем жёстком диске.
- В какой-то момент граббер останавливается, потому что он скачал все доступные ему страницы с этого сайта.
После работы граббер оставляет у вас на диске гору файлов, которые представляют собой статичный отпечаток чужого сайта. Эту гору можно загрузить на собственный сервер, и издалека это будет похоже на чужой сайт.
✅ Плюсы: граббер может быстро охватить много страниц и скачать из них огромное количество стилей, картинок и всего подряд. Работа очень быстрая и хорошо автоматизирована.
❌ Минусы: часто он качает всё без разбора, оставляя на диске много дублей. Также он бессилен с сайтами, в которых контент выводится динамически или имеет нестандартную систему адресации.
�� В целом грабберы можно использовать, чтобы скачивать сайты библиотек, архивов и других мест, где документов много и всё устроено логично. Например, с помощью граббера можно скачать какую-нибудь классическую книгу из онлайн-библиотеки.
Вот ссылки на грабберы для разных платформ:
- HTTrack — старый интерфейс из нулевых, но свою задачу выполняет полностью. Бесплатный и надёжный, работает везде.
- Getleft — мультиплатформенный граббер, который пытается выкачивать всё, до чего дотянется, включая PHP-скрипты.
- Cyotek WebCopy — для тех, кто любит только Windows, тоже бесплатный.
Сложный путь: ручное сохранение
Допустим, мы хотим сохранить какую-то отдельную страницу сайта или конкретные её части (например, картинки). Но эти картинки как-то так хитро встроены, что вы не можете просто нажать «Сохранить картинку как. ». Тогда потребуется ручной метод.
Заходим на страницу и нажимаем в браузере Ctrl + I (в Виндоус) или ⌥ + ⌘ + I (если у вас мак). Появляется окно «Инспектора», где видна внутренняя структура страницы:
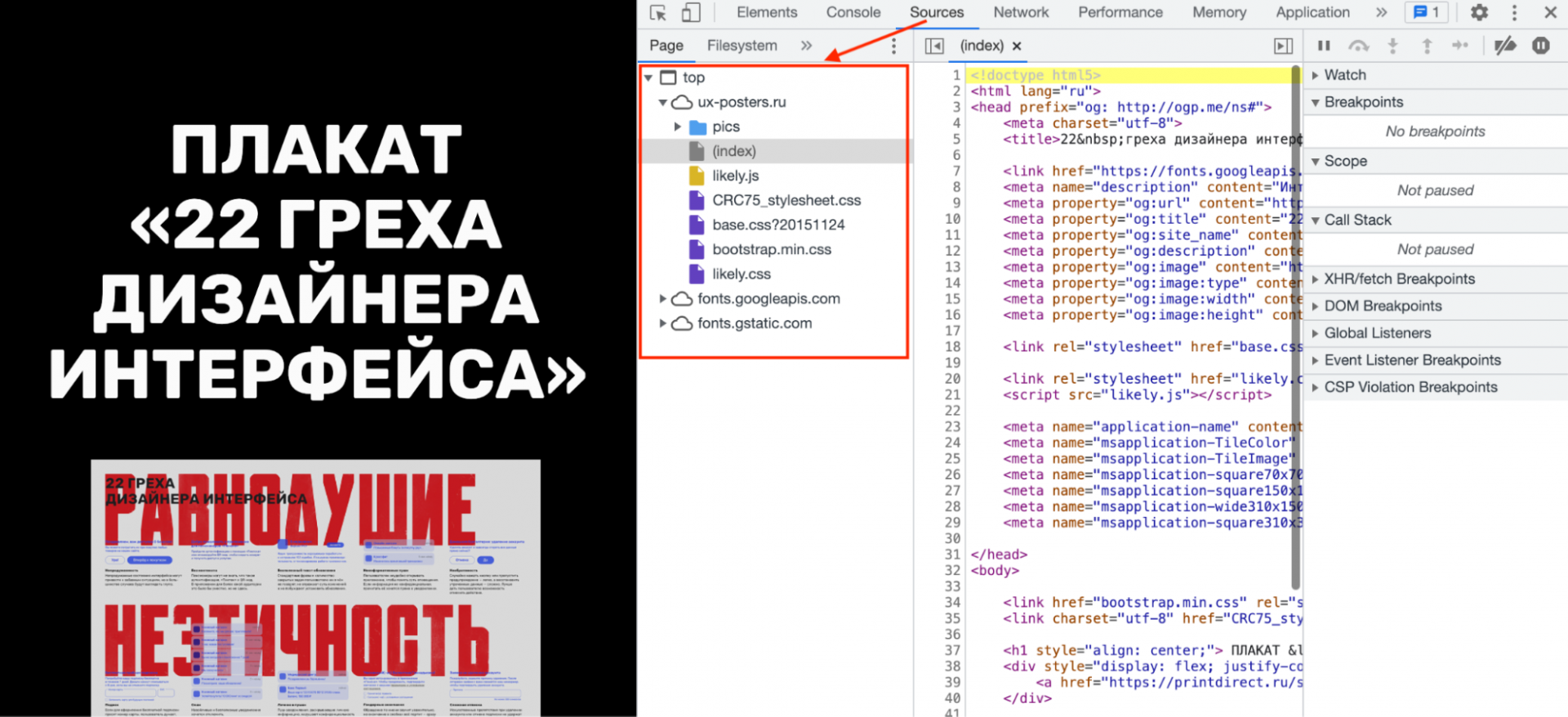
Мы видим, что текущий документ в браузере состоит:
- из страницы index.html;
- скрипта likely.js;
- четырёх таблиц стилей;
- шрифтов, подключённых через сервис Google;
- папки с картинками.
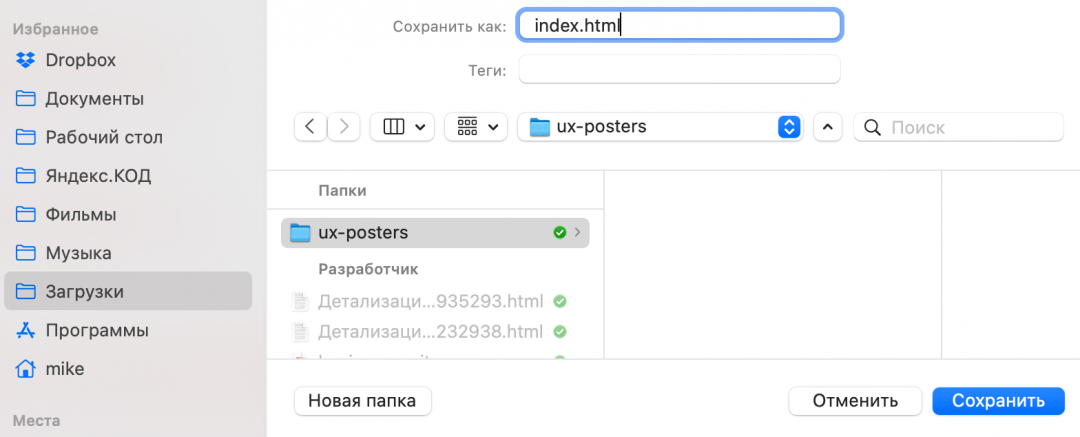
Шрифты нам скачивать необязательно — сайт и так их подключит с сервера гугла, а всё остальное скачать нужно. Чтобы не создавать хаос на компьютере, создадим сначала папку ux-posters — в ней будет храниться наш сайт. Потом в эту папку сохраняем все файлы таким способом:
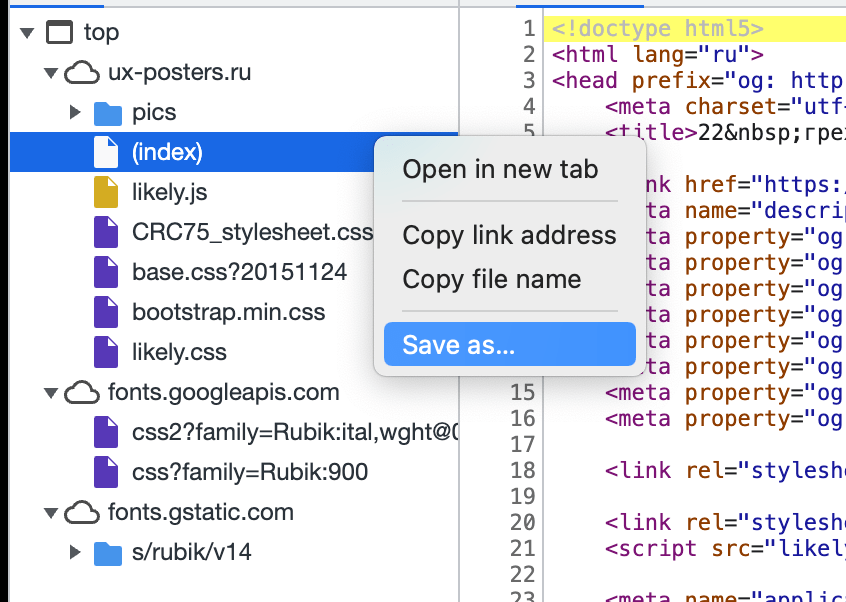
- Нажимаем правой кнопкой мыши на очередной файл.
- Выбираем пункт Save as, или «Сохранить как».
- Пишем имя и расширение файла — точно так, как указано в списке.
- Если лень писать самому — скопируйте перед этим название файла, нажав правую кнопку мыши и выбрав Copy file name, или «Скопировать имя файла».
- Чаще всего название файла подставится само, но если нет — смотрите пункт 4.
Исключения в названии файлов два:
- (index) — это index.html.
- В любом файле знак вопроса и всё, что после него, писать не нужно.
Скачать можно всё, а можно только то, что вам нужно для работы и экспериментов. Например, если вам нужны только стили и код страницы, сохраняйте файлы .css и (index). Если нужны картинки, заходите в папку pics и сохраняйте всё оттуда.
Что в итоге
Если мы пройдёмся по всем папкам и сохраним в них всё нужное нам, у нас получится локальный слепок сайта. Теперь можно:
- Изучить, как он устроен, что-то отредактировать и увидеть результат у себя на компьютере.
- Открыть файл index.html в браузере, и будет ощущение, что вы зашли на сайт, но с локального компьютера. Сайт откроется по протоколу file:// — это так браузер говорит нам, что файл взялся с нашего компьютера, а не из интернета.
- Запустить MAMP и завести на нём локальную копию сайта для экспериментов. Тогда браузер будет думать, что ходит за этим сайтом в интернет. Можно написать какие-нибудь php-скрипты и оживить сайт.
�� Важно понимать, что перед нами именно «слепок» — то, что мы бы увидели, если бы сервер сегодня ответил на наш запрос. Если завтра сервер будет отвечать по-другому, мы этого в своей локальной копии не увидим.
Когда ещё это пригодится
Защитить сайт перед наплывом пользователей. С помощью грабберов можно быстро создать неубиваемую статическую копию сайта и временно подменить ей динамическую версию сайта. Это полумера, но может сработать. А вообще вместо этого есть специальные надстройки, которые делают почти то же самое, но более умно, — поищите слово «кеширование».
Сделать копию своего блога, личного сайта или ещё чего-то важного вам, если вы потеряли к нему доступ, но сайт всё ещё на ходу.
Если вы едете туда, где не будет интернета, а вам нужна информация с сайта (например, путеводитель по чужой стране). Помните, что динамические карты и видеоролики так не сохранятся.
Сделать собственный «веб-архив» — это сервис, который ползает по сайтам и делает их «слепки» для истории. Благодаря этому сервису можно посмотреть, как выглядели ваши любимые сайты много лет назад — например, Яндекс.
Как скачать контент с сайта, не засоряя браузер плагинами.
Порой возникает ситуация, когда нужно скачать музыку/видео/картинку с сайта, а заветной кнопки «Скачать» на странице нет.
Для популярных сайтов, вроде ВК и ютуба, эта проблема остро не стоит, для них имеется куча разных программ, плагинов или сайтов, дающих вам возможность скачать нужный контент. Но как быть с не столь популярными сайтами, для которых найти плагины почти нереально??
Способ есть! И что самое главное, ничего скачивать и устанавливать не надо, все делается стандартными средствами браузера.
Я не мастер словоблудия, поэтому учиться будем на примерах.
(формат поста: сначала описание картинки, потом — сама картинка)
1. Заходим на страницу с видео, кликаем правой кнопкой мыши, в появившемся меню выбираем пункт «Просмотреть код элемента».
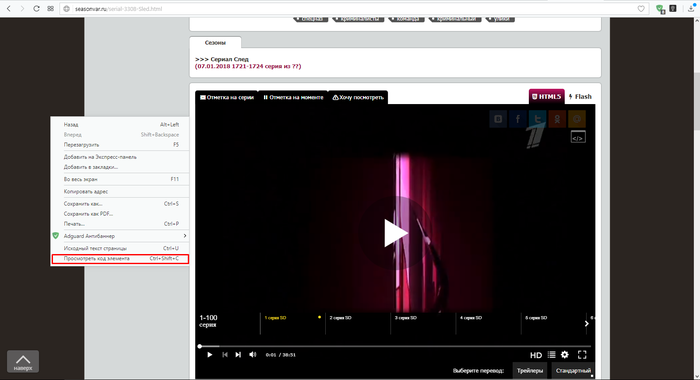
2. В появившемся окне выбираем вкладку «Network».
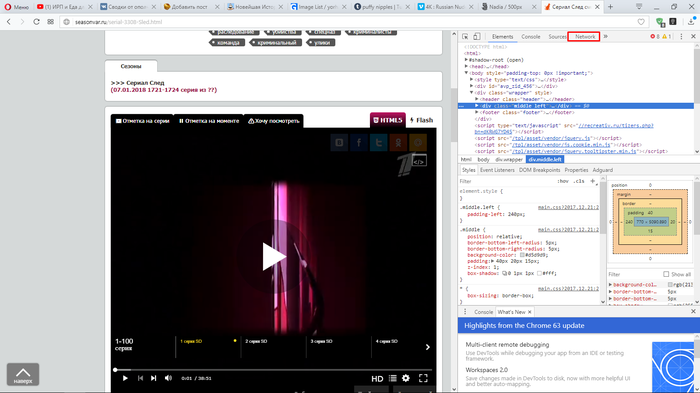
3. Затем выбираем вкладку «Media».
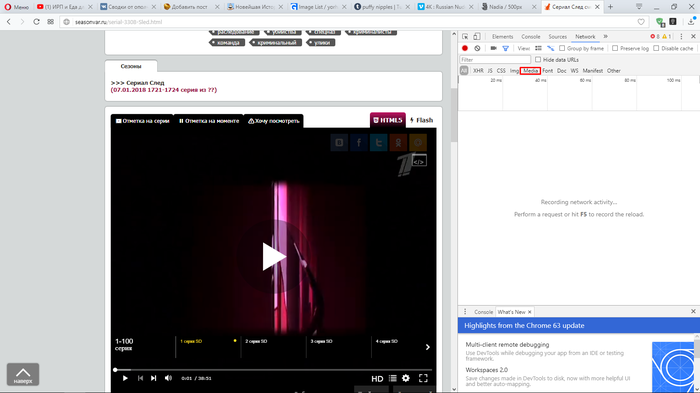
4. Перезагружаем страницу и запускаем видео.
5. Выбираем в таблице нужный нам файл (у меня он один, но бывает и несколько, тогда следует немного подождать, и выбрать файл с наибольшим объемом (объем файла указан в пункте «Size»)) и делаем двойной клик по нему.
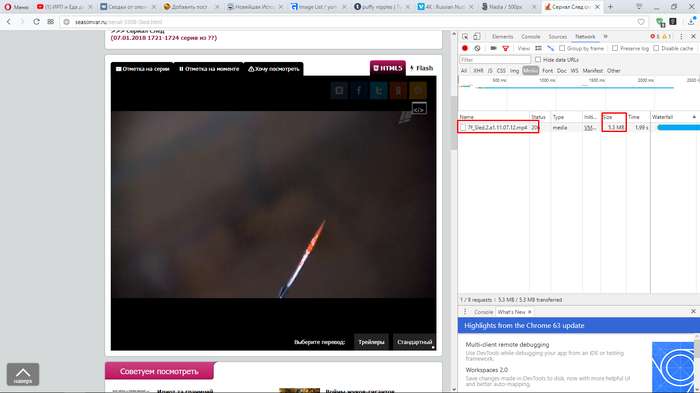
6. Откроется новая вкладка с плеером, нажимаем кнопку «Скачать» и наслаждаемся видом загрузки))
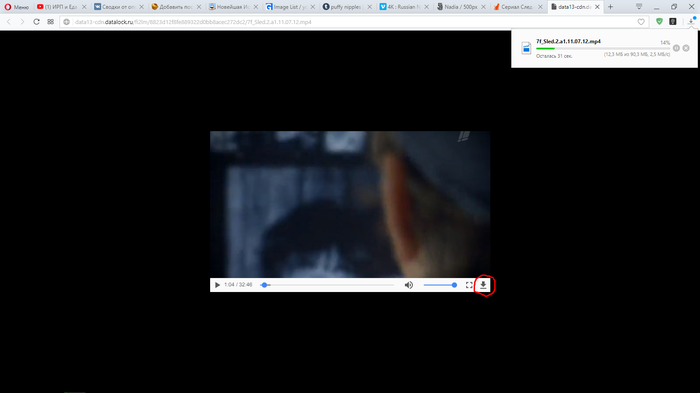
Пример 2. Музыка.
1. Повторяем пункты 1 — 4 из первого примера.
2. Запускаем воспроизведение нужного трека, и делаем двойной клик на файле с наибольшим объемом, затем повторяем пункт 6 из первого примера.
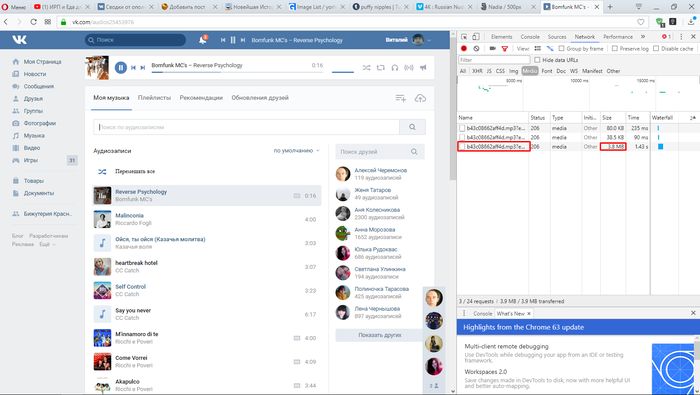
Пример 3. Картинка.
Чтобы не было глупых вопросов, поясню: не на всех сайтах можно сохранить картинку через контекстное меню, на некоторых оно либо урезано, либо заблокировано совсем.
1. Повторяем пункты 1 — 2 из первого примера.
2. Выбираем вкладку «Img».
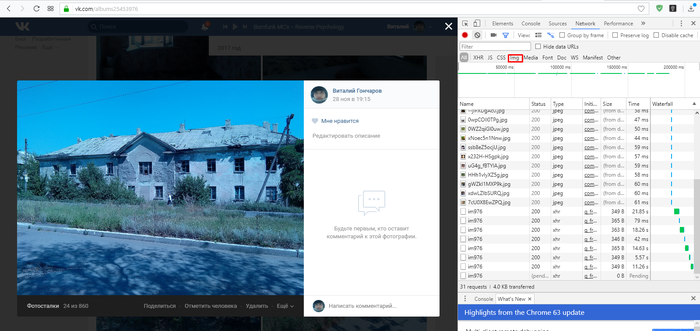
3. Перезагружаем страницу.
4. Ищем нужную картинку в списке (он может быть большим), используя предпросмотр (один клик по файлу) и найдя, делаем двойной клик по ней.
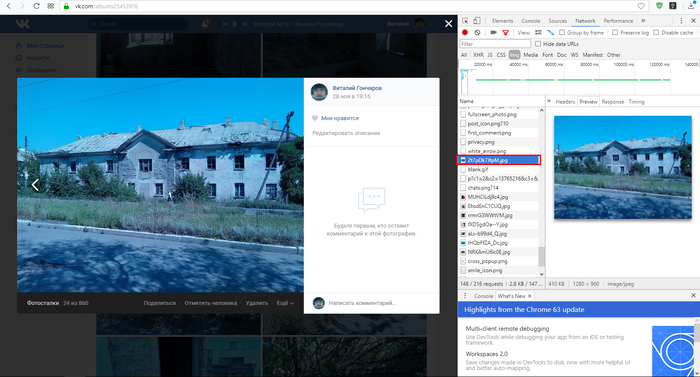
5. В открывшейся вкладке кликаем правой клавишей мыши по картинке, и выбираем в контекстном меню пункт «Сохранить изображение как. «.
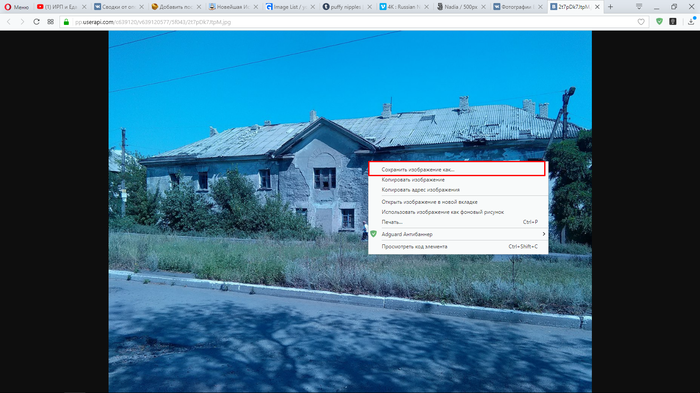
6. Сохраняем картинку.
P. S.: Все действия проводились на Опере v.50, за работоспособность этого способа на других браузерах я не ручаюсь.

6 лет назад
Ну удачи вам с потоковым контентом
раскрыть ветку
6 лет назад
уважаемый мамкин хакирь, специально от таких как вы видосы режут на кусочки и с ютуба ты так не скачаешь
пс: шучу, не специально а для оптимизации
раскрыть ветку
6 лет назад
Для Хрома — Flash Video Downloader
Для Мозилы — FlashGot
раскрыть ветку
6 лет назад
С потоковым видео такое не прокатит, плюс есть всякие защищенные плееры на подобии netu.tv, которые в плеер вставляют кучу всякого мусора, который затрудняет поиск потока.
Так, что НЕ с любого сайта.
6 лет назад
чет с ютобом у меня не прокатило
раскрыть ветку
Похожие посты
1 месяц назад

А так можно было что ли?
Поддержать
4 месяца назад
Девушка демонстрирует способы освободить связанные изолентой или зажимом руки
Мало ли пригодится в жизни.
Взято из сети.
Поддержать
11 месяцев назад
Ещё один вариант
Поддержать
1 год назад
Как купить билет на поезд, если билетов нет совсем. 3 проверенных способа
Бывают случаи, когда вам нужно ехать в другой город: по работе, на свадьбу, юбилей и т.д. Забегались, забыли, билеты не купили. Что делать, если билетов нет от слова Совсем. Да, на вашу дату осталось, пару билетов СВ по цене, как ваша месячная зарплата. Что делать? Вы не можете не ехать.
Сохраните в закладки, чтобы не потерять.
Отказные билеты.
Заходить на сайт РЖД каждые 10 минут. Во-первых есть много нюансов, когда снимается дополнительная бронь и появляются билеты, за 3 суток, за сутки, за 3 часа и т.д. Плюс кто-то может сдать билет.
Некоторые направления настолько популярны, например Минск-Москва, что уже в ноябре люди начинают покупать билеты на Новый год, причем в обе стороны. Тем более 10 дней праздничных дней в России сделают свое дело. Попробуйте найти билеты на 30 декабря, скорее всего их почти не осталось.
Второй способ- можно поделить ваш путь на части. Самый работающий метод.
Сейчас расскажу подробнее. Например, вы едете Москва-Минск. Билетов нет, совсем никаких. Вы смотрите маршрут поезда, который вам нужен. Какие крупные города проезжает поезд.
В нашем случае Вязьму, Смоленск. Начинаете смотреть билеты частями: Москва-Вязьма, Вязьма-Смоленск, Смоленск-Минск и т.д. Да это не очень удобно, старайтесь , чтобы места были в одном вагоне. То есть до Вязьмы вы едете на месте 21, дальше 45. Впринципе ничего страшного) Только у проводников иногда вызывает удивление.
Почему частями должны быть свободные места? Потому что человек, например, купил билет Москва-Вязьма, это всего 3 часа от Москвы, дальше это место до самого Минска будет свободно, а вы в итоге не можете уехать.
Допустим вы нашли билет Вязьма-Минск, теперь ваша задача добраться из Москвы до Вязьмы. Ищите билет в этом же вагоне или хотя бы поезде. Если вообще ничего нет, смотрите билет на другой поезд. Да, это не удобно! Пересаживаться, иногда ночью, на другой поезд! Но речь о ситуациях, когда вам надо быть завтра на свадьбе свидетельницей, и вы не можете сказать подруге:
-Извини, не было билетов, я не приеду!
К тому же до этого ближайшего города, например, Вязьмы, вы можете добраться на электричке, скоростной Ласточке за 2 часа, на автобусе, вас может довезти муж на машине.
Третий способ — смотреть билеты на начало следующего дня.
Допустим впереди 3-4 праздничных дня и вы упорно ищите билеты на пятницу вечер. Ничего нет. Всем надо ехать.
А теперь попробуйте посмотреть на субботу, после 0.00 часов. И там кстати довольно много поездов, на час ночи, на 3.00. Вот как раз на поезда глубокой ночью могут быть билеты, потому что не каждый сможет добраться. Плюс на утро скорее всего будут билеты, да, потом полдня ехать, может немного опоздаете на торжество. Но вы приедете!
Вывод- выход с покупкой билетов есть всегда! Да, способы не очень удобные, но не пешком же вам идти.
Забронировать билет на поезд онлайн:
Сервисы бронирования жилья:
Суточно (квартиры, комнаты, отели и апартаменты),
Инструкция: как скачать файл с GitHub
Закройте IDE. Забудьте про пуши. Отрекитесь от коммитов и репозиториев.

Кадр: сериал «Остановись и гори»

Максим Сафронов
Автор, редактор, IT-журналист. Рассказывает о новых технологиях, цифровых профессиях и полезных инструментах для разработчиков. Любит играть на электрогитаре и программировать на Swift.
Если вы откроете файл в веб-версии GitHub, то заметите, что там нет отдельной кнопки «Скачать». Действительно, удобного способа загружать код напрямую с сайта разработчики не завезли, но есть альтернативные способы — в этой статье как раз о них поговорим. Заодно разберёмся, как скачивать файлы с GitHub на смартфон — пока только на Android-устройства, с айфонами всё сложно.
Способ первый
Скачать проект целиком
Все проекты на GitHub хранятся в репозиториях. Репозиторий — это место, где лежат файлы, библиотеки и фрагменты кода программы. Хорошая новость: если у вас есть доступ к проекту, его можно утащить себе на компьютер и разобрать на отдельные файлы. Вот как это сделать:
Шаг 1. Выберите проект, который хотите скачать. Ваши репозитории хранятся в разделе Your repositories, а проекты из свободного доступа можно найти с помощью окошка Search or jump to.
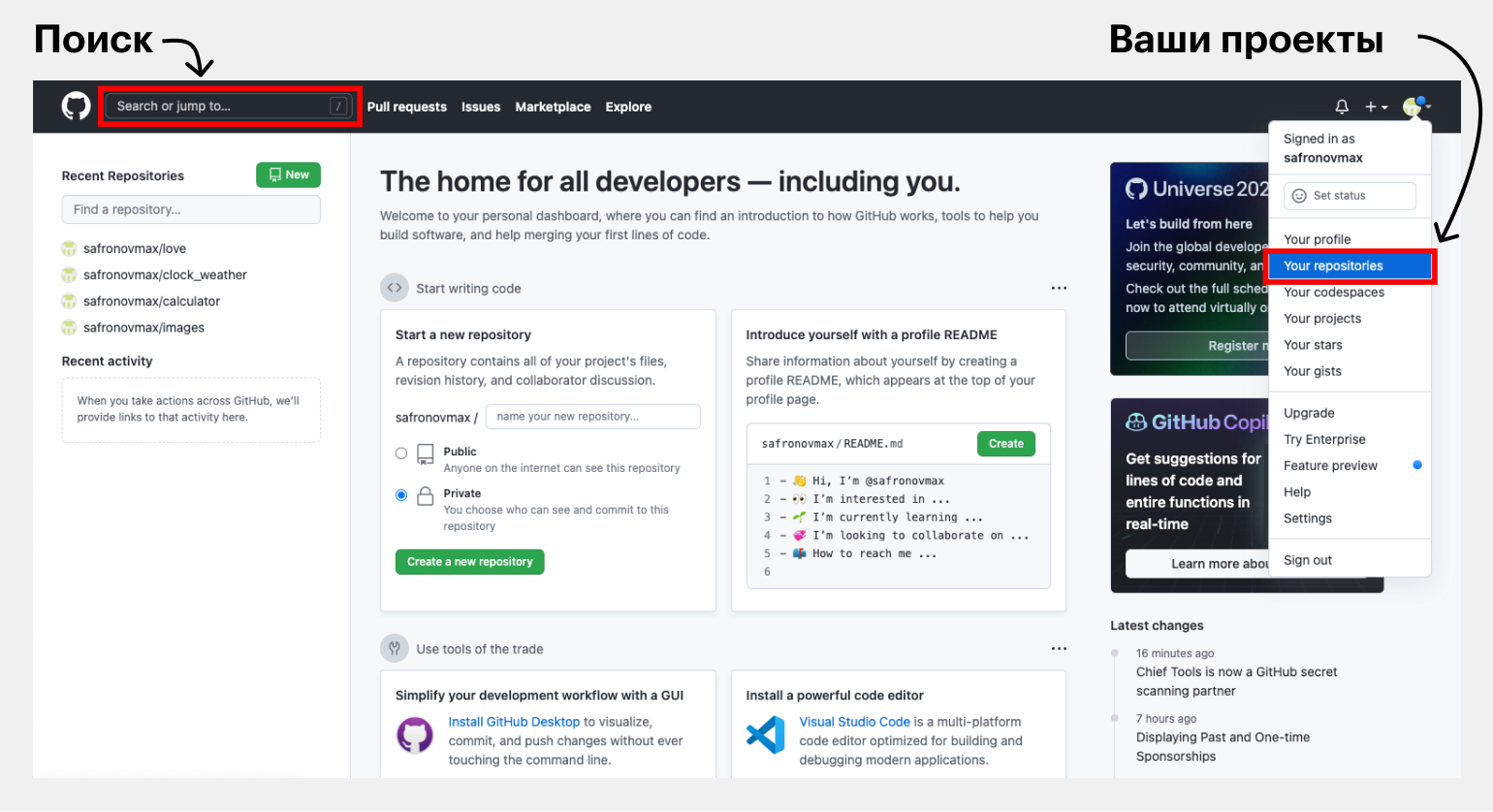
Шаг 2. Откройте выбранный проект. Мы, например, решили забрать себе классический «виндовый» калькулятор, с недавних пор выложенный в открытый доступ в аккаунте Microsoft.
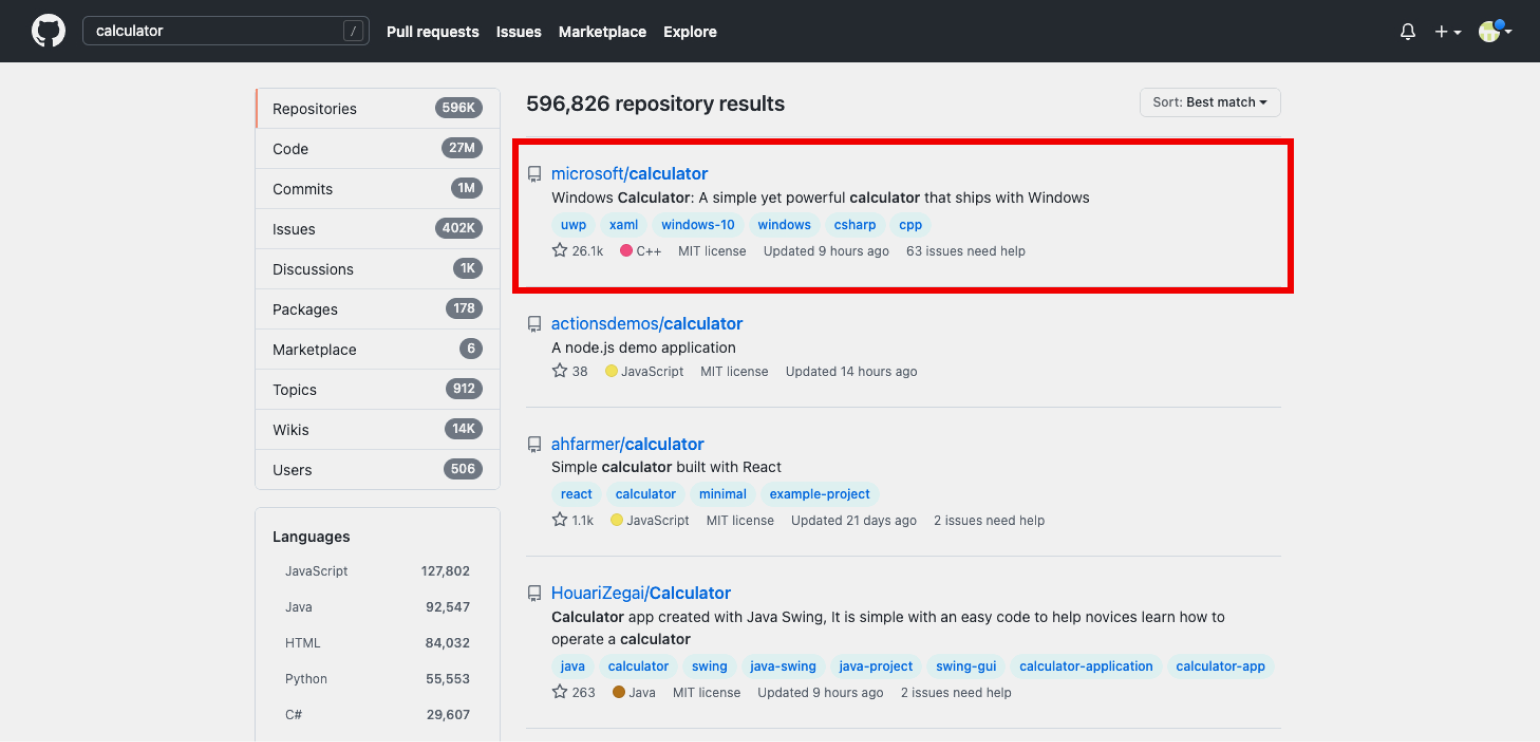
Шаг 3. Нажмите кнопку Code в правом верхнем углу. Выпадет меню, в котором нужно выбрать Download ZIP.
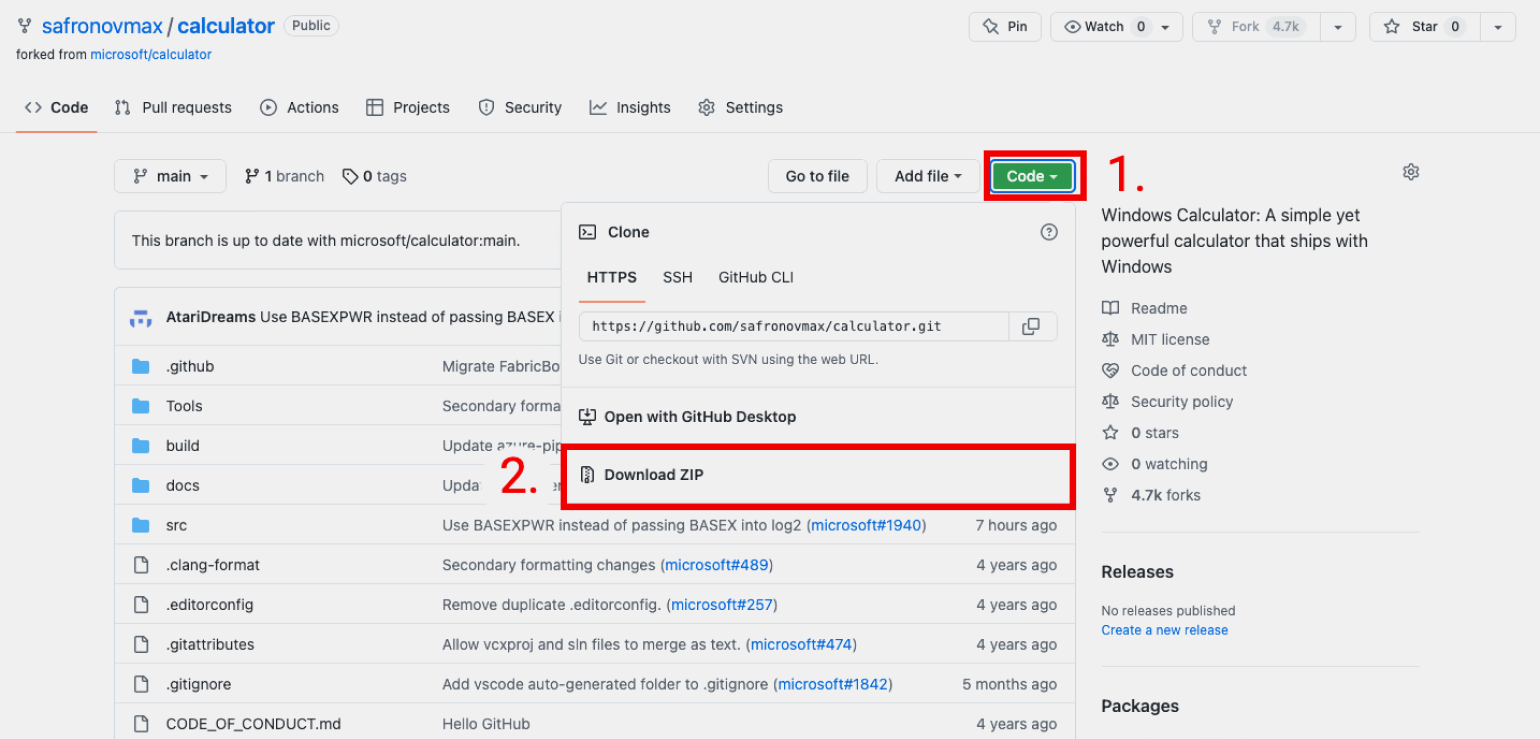
Готово! Теперь у нас на компьютере есть собственная версия проекта. Можно запустить его в Visual Studio, а также в другом редакторе кода или IDE и допилить под свои нужды. Например, перекрасить кнопки в фиолетовый цвет — а почему бы и нет? ��
Способ второй
Скачать файл с GitHub через Raw
Единственный штатный способ скачать отдельный файл в GitHub — это кнопка Raw. Она превращает код файла в обычный текстовый документ без всякой разметки — в таком виде его можно легко загрузить на жёсткий диск. Не слишком удобный, но рабочий способ — давайте его тоже разберём.
Шаг 1. В репозитории проекта откройте файл, который хотите скачать.
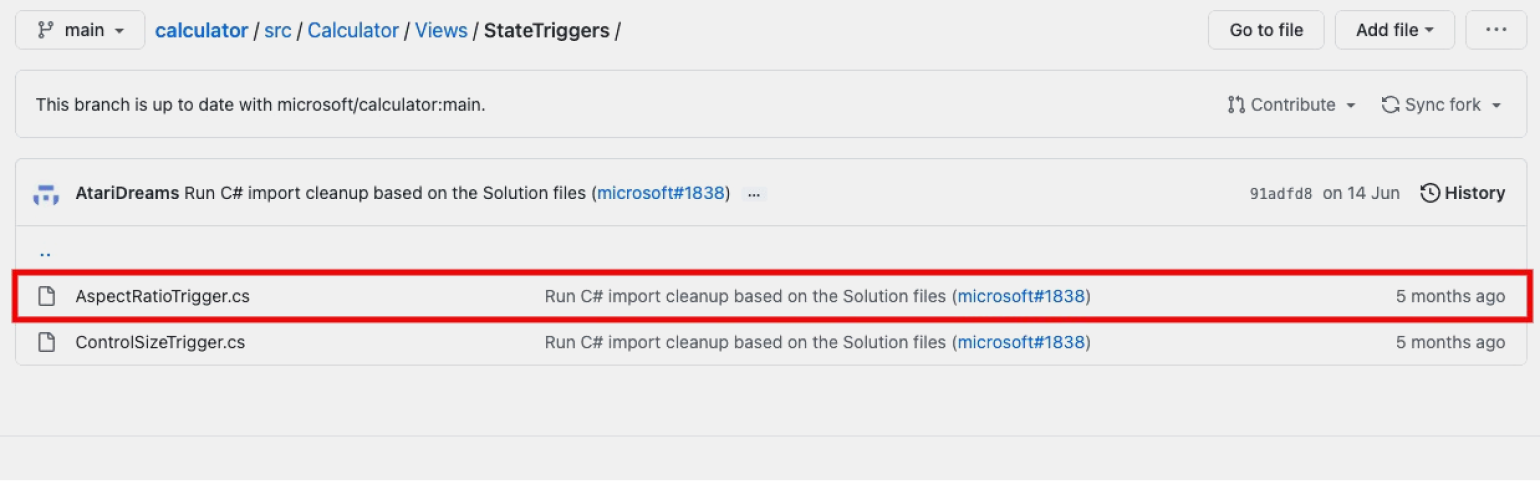
Шаг 2. Когда файл откроется, нажмите кнопку Raw.
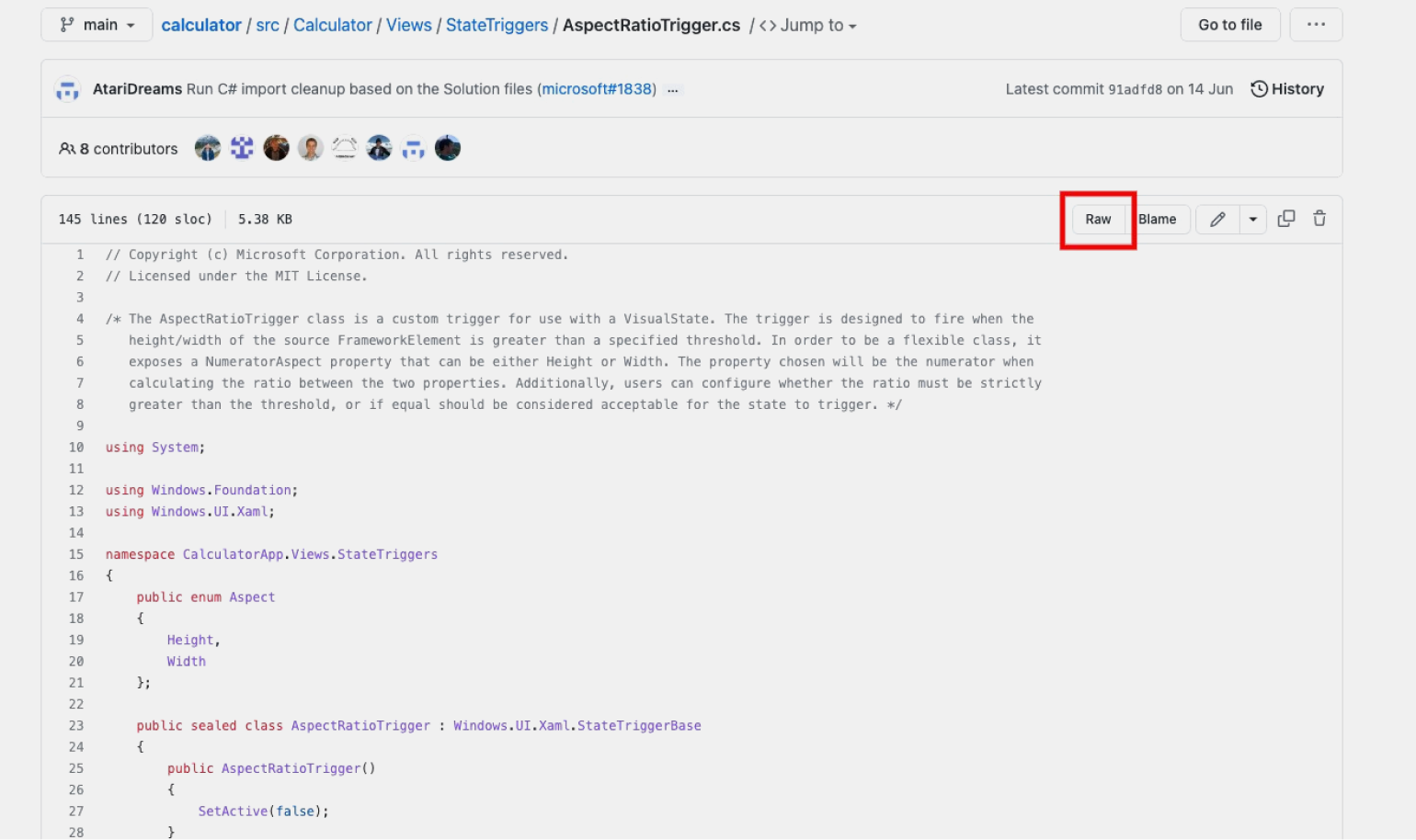
Шаг 3. Перед вами — исходный код файла, открытый в браузере. Чтобы его скачать, нажмите правой кнопкой мыши, а потом выберите «Сохранить как…».
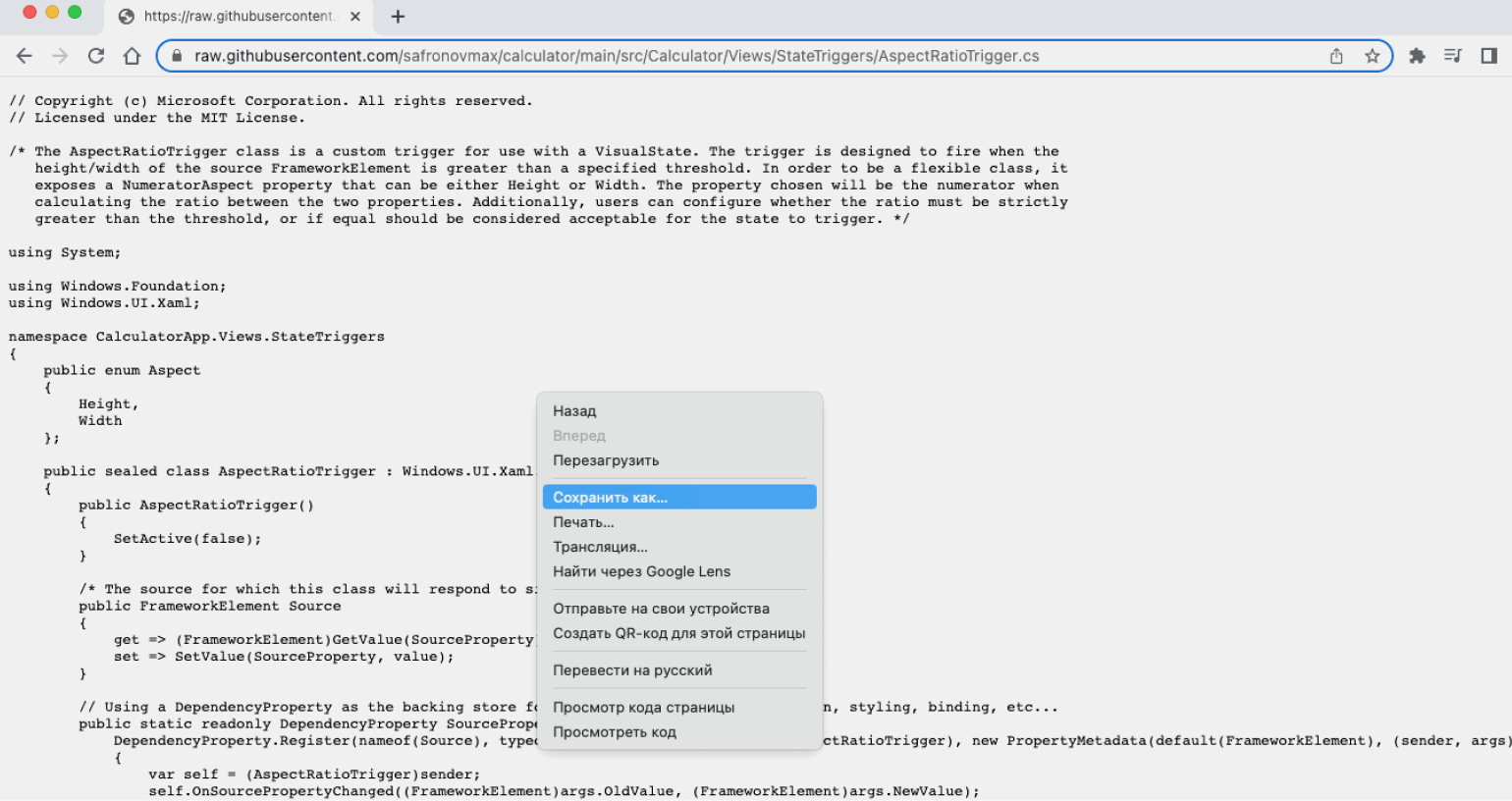
Шаг 4. В открывшемся окне можно задать файлу имя и формат. Если планируете работать с кодом в текстовом редакторе, можно оставить .txt.
Способ третий
Использовать расширение
В интернет-магазинах браузеров полно расширений, которые облегчают загрузку с GitHub. Например, GitZip for GitHub помогает скачивать не только файлы, но и целые папки. Рассказываем, как им пользоваться:
Шаг 1. Скачайте и установите утилиту в магазине расширений вашего браузера — есть версии для Chrome, Microsoft Edge и Mozilla.
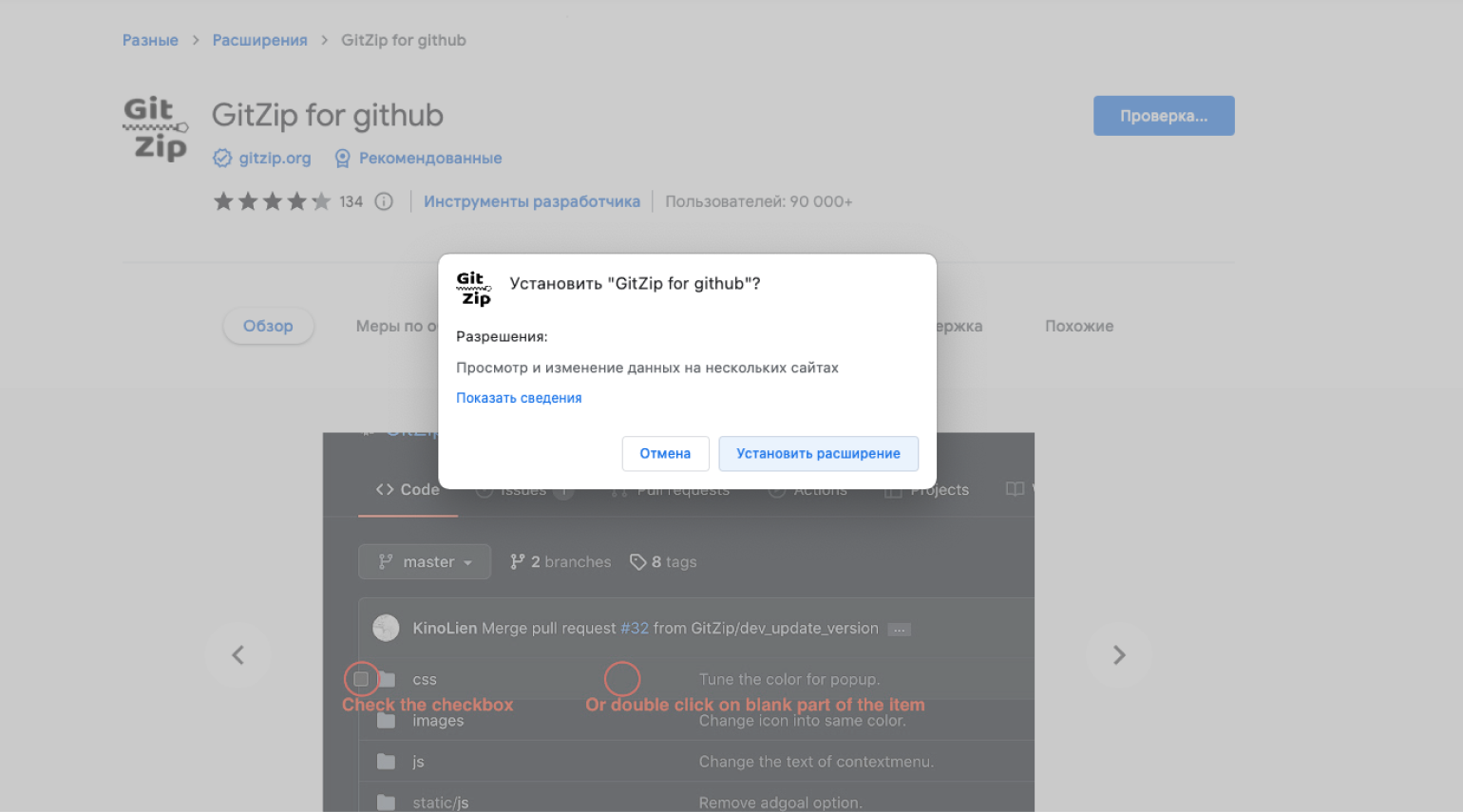
На заметку: если расширение доступно для Chrome, то запустить его можно в любом браузере, работающем на хромовском движке Blink, — например, в Opera, Vivaldi или «Яндекс.Браузере».
Шаг 2. В репозитории проекта напротив каждого файла появятся чекбоксы — отметьте галочками те, которые хотите скачать.
Шаг 3. Нажмите на кнопку загрузки в правом нижнем углу.
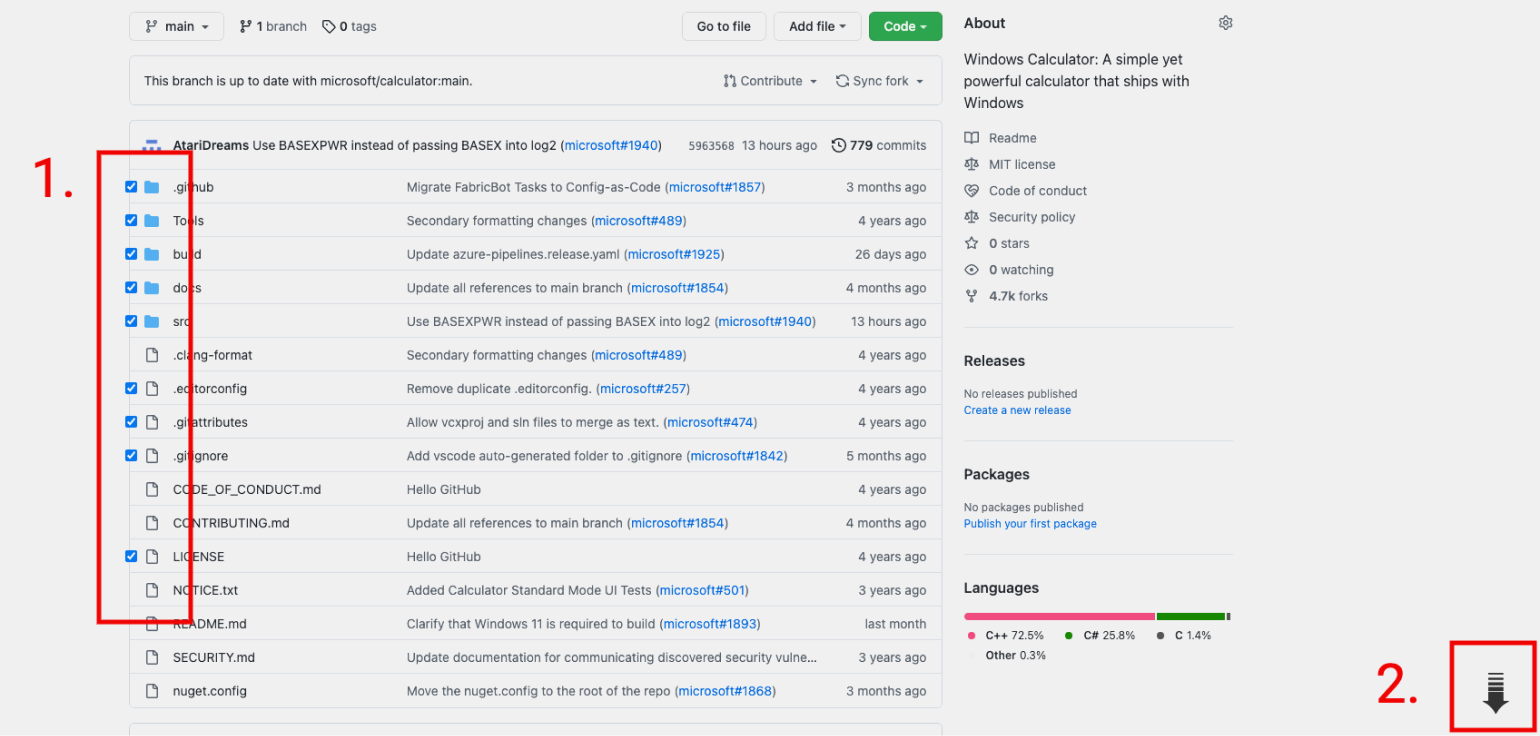
Готово! Можно наслаждаться новыми возможностями до боли знакомого сервиса.
Бонус: как скачивать файлы из GitHub на Android-устройствах
По умолчанию в мобильной версии GitHub нет функции скачивания файлов. Но её можно активировать, если открыть в мобильном браузере версию сайта для ПК. После этого можно будет скачать отдельный файл либо весь проект в виде ZIP-архива.
Если нужен проект целиком:
Шаг 1. Откройте веб-страницу нужного репозитория через Google Chrome.
Шаг 2. В контекстном меню браузера нажмите на кнопку «Версия для ПК».
Шаг 3. После этого страница перезагрузится и откроется обычная десктопная версия сайта. Нажмите зелёную кнопку Code, а потом — Download ZIP.
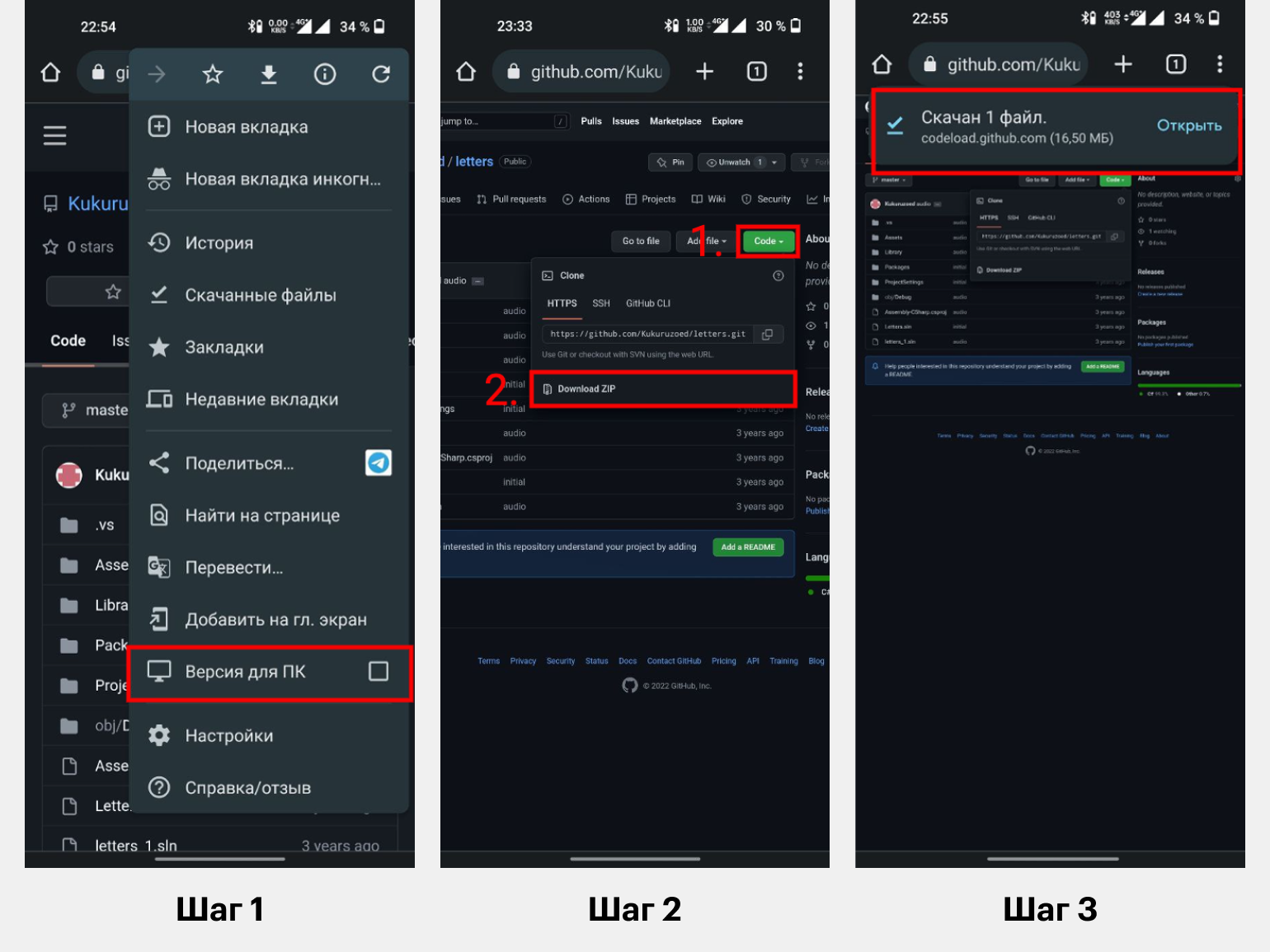
Если нужен отдельный файл:
Шаг 1. Откройте на GitHub страницу файла и активируйте версию для ПК.
Шаг 2. Когда откроется десктопная версия страницы, нажмите кнопку Raw в правом верхнем углу.
Шаг 3. Снова вызовите контекстное меню браузера и нажмите на значок загрузки в самом верху — после этого на смартфон скачается нужный файл в формате .txt.
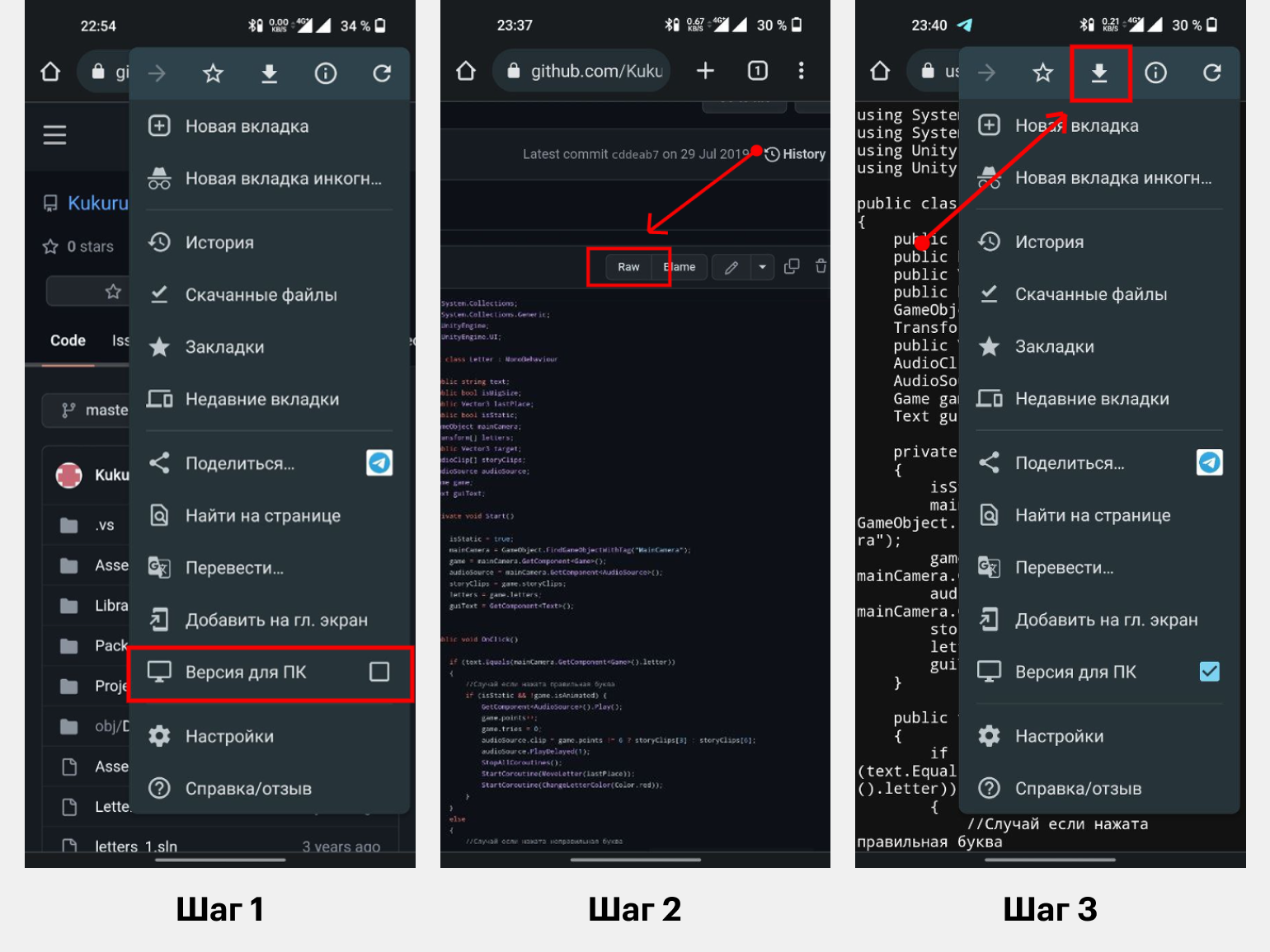
К сожалению, на iOS десктопная версия GitHub не открывается ни в одном браузере, поэтому функции Raw и Download ZIP недоступны. Если у вас есть рабочий способ — напишите нам в редакцию, добавим его в статью.
Что дальше
В этой статье мы обсудили нюансы работы только с веб-версией GitHub. Если хотите полностью перенести проект на свой компьютер и работать с ним локально, почитайте нашу статью про GitHub Desktop. Вы узнаете, как создать репозиторий, синхронизировать его с ПК и обновлять файлы удалённо.
Ещё можно почитать материал про систему контроля версий Git. Объясняем на понятных схемах, как работает технология, которая лежит в основе GitHub и других похожих сервисов. Вы поймёте, как там всё устроено, и сможете блеснуть знаниями на собеседовании.
Больше интересного про код в нашем телеграм-канале. Подписывайтесь!