Удаление или поиск дубликатов (повторяющихся) записей в таблице
Начнем с того, что важно определить, отличаются записи хоть одним полем или нет. Оператор DELETE и вообще SQL не позволяет из двух одинаковых записей удалить только одну – либо все дубликаты, либо ни одного.
Однако, используя специфический для IB номер записи, это можно сделать. Например:
DELETE FROM XXX T1 WHERE EXISTS
(SELECT * FROM XXX T2 WHERE
(T2.column1 = T1.column1 or (T2.column1 is null and T2.column1 is null)) AND
(T2.column2 = T1.column2 or (T2.column2 is null and T2.column2 is null)) AND
(. ) AND
( T2.RDB$DB_KEY > T1.RDB$DB_KEY ))
В этом случае используется RDB$DB_KEY – физический номер записи IB. Можно оставить как запись с самым большим DB_KEY, так и с самым меньшим (> или < в последнем условии WHERE).
Для поиска имеющих какой-либо одинаковый столбец записей обычно используется запрос, похожий на следующий:
SELECT * FROM TABLE T1
WHERE (SELECT COUNT(*)
FROM TABLE T2
WHERE T1.FIELD = T2.FIELD ) > 1
Однако этот запрос не совсем эффективен. Вместо него выгоднее использовать процедуру, которая будет выполняться намного быстрее:
(Ann Harrison)
for select field
from table
group by field
having count (field) > 1
into :fld
do
begin
for select field
from table
where field = :fld
into :fld1
do
begin
suspend;
end
end
Но хранимая процедура не всегда удобна. Также можно использовать уникальный идентификатор записи RDB$DB_KEY:
(Josef Marie M. Alba)
SELECT * FROM TABLE T1
WHERE EXISTS
(SELECT FIELD FROM TABLE T2
WHERE T1.FIELD = T2.FIELD AND
T1.RDB$DB_KEY != T2.RDB$DB_KEY )
Copyright iBase.ru © 2002-2023
Способы удаления дубликатов в SQL Server

При проектировании объектов, в частности таблиц в БД SQL Server необходимо придерживаться определенных правил: рекомендуется использовать правила нормализации БД; таблица должна иметь первичные ключи, кластерные и некластерные индексы; ограничения для обеспечения целостности данных и производительности. Но даже если следовать этим правилам, мы можем столкнуться с проблемой появления дубликатов в строках таблицы. Кроме этого, возможна ситуация получения дубликатов при импорте данных, когда мы загружаем данные as is в промежуточные таблицы, и далее требуется удалить дублирующие записи перед загрузкой в промышленные таблицы.
Рассмотрим различные способы для очистки данных от дублей. Создадим простую таблицу сотрудников и наполним её несколькими записями.
CREATE TABLE Employee ( [id] int identity(1,1), [Фамилия] nvarchar(100), [Имя] nvarchar(100), [Отчество] nvarchar(100), [Дата рождения] date, ) GO Insert into Employee ([Фамилия],[Имя],[Отчество],[Дата рождения]) values (N'Алексеев',N'Алексей',N'Алексеевич','1990-03-01'), (N'Алексеев',N'Алексей',N'Алексеевич','1990-03-01'), (N'Алексеев',N'Алексей',N'Алексеевич','1990-03-01') (N'Иванов',N'Иван',N'Иванович','1985-01-01'), (N'Иванов',N'Иван',N'Иванович','1985-01-01'), (N'Петров',N'Петр',N'Петрович','1988-02-01'),Как мы видим, в таблице присутствуют дублирующие строки, которые необходимо удалить.
- Удаление дубликатов с использованием агрегатных функций
C помощью условия GROUP BY мы группируем данные по определенным столбцам и используем функцию COUNT для подсчета вхождений строк в таблицу.
Например, с помощью следующего запроса, определим записи, которые присутствуют в таблице более 1 раза.
Select [Фамилия], [Имя], [Отчество], [Дата рождения], count(*) as CNT FROM NTA.dbo.Employee GROUP BY [Фамилия], [Имя], [Отчество], [Дата рождения] having count(*) > 1Т.е. сотрудники Алексеев А.А. и Иванов И.И. присутствуют в таблице 3 и 2 раза соответственно.

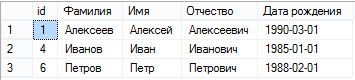
Удалим дублирующие записи, оставив только строки с MIN id сотрудника.
Delete FROM NTA.dbo.Employee Where id not in ( select min(id) as MinRowID FROM NTA.dbo.Employee group by [Фамилия],[Имя],[Отчество],[Дата рождения] )Выведем оставшиеся записи таблицы, и убедимся, что дубликаты отсутствуют.
Отметим, что данный способ удаления дубликатов возможен в случае таблиц, для которых определен первичный ключ.
- Удаление дубликатов используя обобщенные табличные выражения (CTE)
Мы можем использовать связку обобщенных табличных выражений и функции ROW_NUMBER() для удаления дубликатов, например следующим образом:
WITH CTE ([Фамилия], [Имя], [Отчество], [Дата рождения], [Нумерация] ) AS (SELECT [Фамилия], [Имя], [Отчество], [Дата рождения], ROW_NUMBER () OVER (PARTITION BY [Фамилия], [Имя], [Отчество], [Дата рождения] ORDER BY id) AS [Нумерация] FROM NTA.dbo.Employee) DELETE FROM CTE WHERE [Нумерация] > 1В данном запросе мы используем функцию ROW_NUMBER() с конструкцией PARTITION BY в предложении OVER для нумерации записей, и удаляем записи с пронумерованными значениями > 1, соответствующие дубликатам.
- Удаление дубликатов с использованием инструментария SSIS пакетов.
Создадим в SQL Server Data Tools новый пакет integration Services.
Добавим в пакет элемент «OLE DB Source», откроем редактор OLE DB Source, в графе Connection Manager укажем реквизиты экземпляра СУБД и БД, и наименование исходной таблицы с данными, содержащей дубликаты.
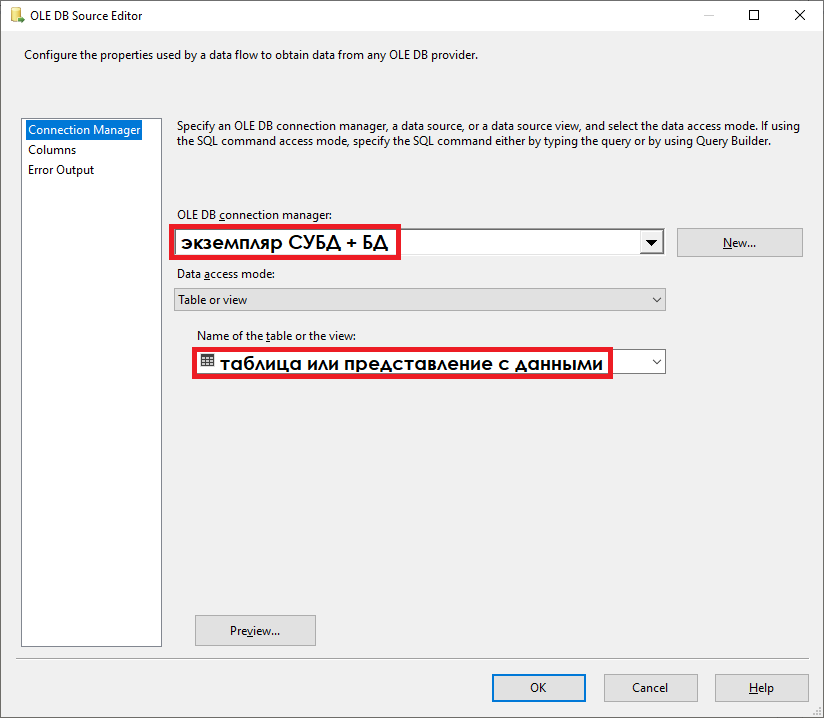
С помощью кнопки Preview убедимся, что в исходной таблице присутствуют дубликаты.
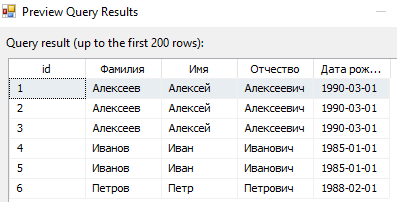
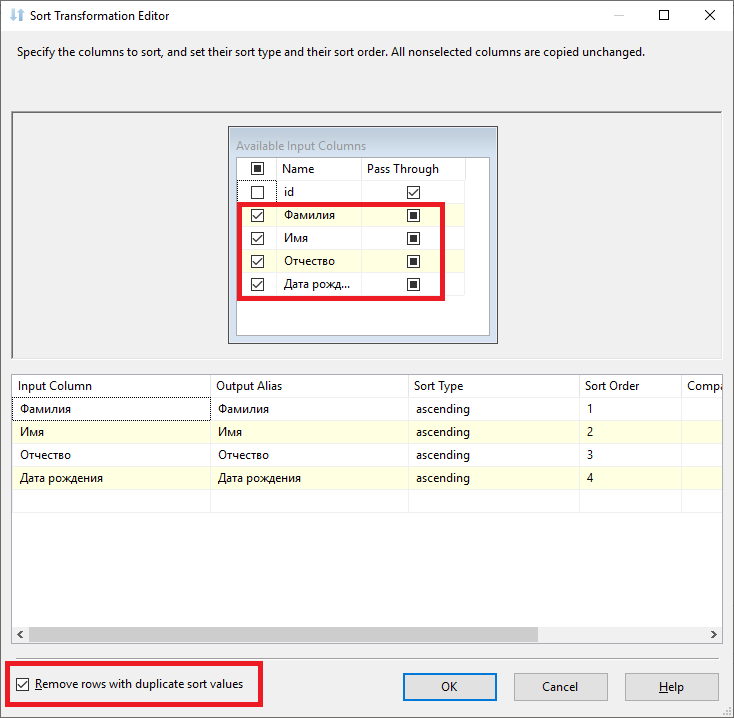
Добавим оператор «Sort», и выделим поля, в которых присутствуют дублирующие данные.
Установим галку «Remove rows with duplicate sort values» для удаления дубликатов.
Добавим элемент «OLE DB Destination», в котором укажем целевую таблицу для записей результата очистки данных.
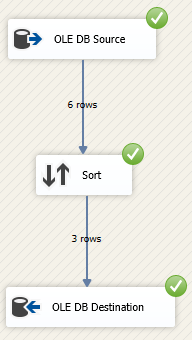
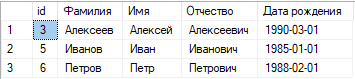
Запустив на исполнение реализованный SSIS пакет, мы видим, что в целевой источник загрузилось 3 строки, проверим, что отсутствуют дубликаты.
Необходимо отметить, что при использовании данного способа потребуется дополнительное место для хранения новой целевой таблицы, однако данный вариант позволяет избежать ошибок и вернуться к исходному варианту, в случае если результат в целевой таблице не будет являться удовлетворительным.
В данной статье мы рассмотрели различные способы удаления дубликатов записей в таблицах БД SQL Server, которые могут быть использованы в работе в зависимости от задачи и объема данных.
При больших объемах дубликатов в данных целесообразно рассмотреть возможность сохранения уникальных значений в промежуточную таблицу, очистку рабочей таблицы, и возврат оставленных уникальных записей.
Способы удаления дубликатов в SQL Server
При проектировании объектов, в частности таблиц в БД SQL Server, необходимо придерживаться определенных правил. Однако, даже если следовать данным правилам существует вероятность появления дубликатов в строках таблиц. Данная статья посвящена различным способам очистки данных от дубликатов.
При проектировании объектов, в частности таблиц в БД SQL Server необходимо придерживаться определенных правил: рекомендуется использовать правила нормализации БД; таблица должна иметь первичные ключи, кластерные и некластерные индексы; ограничения для обеспечения целостности данных и производительности. Но даже если следовать этим правилам, мы можем столкнуться с проблемой появления дубликатов в строках таблицы. Кроме этого, возможна ситуация получения дубликатов при импорте данных, когда мы загружаем данные as is в промежуточные таблицы, и далее требуется удалить дублирующие записи перед загрузкой в промышленные таблицы.
Рассмотрим различные способы для очистки данных от дублей. Создадим простую таблицу сотрудников и наполним её несколькими записями.
CREATE TABLE Employee ( [id] int identity(1,1), [Фамилия] nvarchar(100), [Имя] nvarchar(100), [Отчество] nvarchar(100), [Дата рождения] date, ) GO Insert into Employee ([Фамилия],[Имя],[Отчество],[Дата рождения]) values (N’Алексеев’,N’Алексей’,N’Алексеевич’,’1990-03-01′), (N’Алексеев’,N’Алексей’,N’Алексеевич’,’1990-03-01′), (N’Алексеев’,N’Алексей’,N’Алексеевич’,’1990-03-01′) (N’Иванов’,N’Иван’,N’Иванович’,’1985-01-01′), (N’Иванов’,N’Иван’,N’Иванович’,’1985-01-01′), (N’Петров’,N’Петр’,N’Петрович’,’1988-02-01′),
Как мы видим, в таблице присутствуют дублирующие строки, которые необходимо удалить.
- Удаление дубликатов с использованием агрегатных функций
C помощью условия GROUP BY мы группируем данные по определенным столбцам и используем функцию COUNT для подсчета вхождений строк в таблицу.
Например, с помощью следующего запроса, определим записи, которые присутствуют в таблице более 1 раза.
Select [Фамилия], [Имя], [Отчество], [Дата рождения], count(*) as CNT FROM NTA.dbo.Employee GROUP BY [Фамилия], [Имя], [Отчество], [Дата рождения] having count(*) > 1
Т.е. сотрудники Алексеев А.А. и Иванов И.И. присутствуют в таблице 3 и 2 раза соответственно.
Удалим дублирующие записи, оставив только строки с MIN id сотрудника.
Delete FROM NTA.dbo.Employee Where id not in ( select min(id) as MinRowID FROM NTA.dbo.Employee group by [Фамилия],[Имя],[Отчество],[Дата рождения] )
Выведем оставшиеся записи таблицы, и убедимся, что дубликаты отсутствуют.
Отметим, что данный способ удаления дубликатов возможен в случае таблиц, для которых определен первичный ключ.
- Удаление дубликатов используя обобщенные табличные выражения (CTE)
Мы можем использовать связку обобщенных табличных выражений и функции ROW_number() для удаления дубликатов, например следующим образом:
WITH CTE ([Фамилия], [Имя], [Отчество], [Дата рождения], [Нумерация] ) AS (SELECT [Фамилия], [Имя], [Отчество], [Дата рождения], ROW_NUMBER () OVER (PARTITION BY [Фамилия], [Имя], [Отчество], [Дата рождения] ORDER BY id) AS [Нумерация] FROM NTA.dbo.Employee) DELETE FROM CTE WHERE [Нумерация] > 1
В данном запросе мы используем функцию ROW_number() с конструкцией partition BY в предложении OVER для нумерации записей, и удаляем записи с пронумерованными значениями > 1, соответствующие дубликатам.
- Удаление дубликатов с использованием инструментария SSIS пакетов.
Создадим в SQL Server Data Tools новый пакет integration Services.
Добавим в пакет элемент «OLE DB Source», откроем редактор OLE DB Source, в графе Connection Manager укажем реквизиты экземпляра СУБД и БД, и наименование исходной таблицы с данными, содержащей дубликаты.
С помощью кнопки Preview убедимся, что в исходной таблице присутствуют дубликаты.
Добавим оператор «Sort», и выделим поля, в которых присутствуют дублирующие данные.
Установим галку «Remove rows with duplicate sort values» для удаления дубликатов.
Добавим элемент «OLE DB Destination», в котором укажем целевую таблицу для записей результата очистки данных.
Запустив на исполнение реализованный SSIS пакет, мы видим, что в целевой источник загрузилось 3 строки, проверим, что отсутствуют дубликаты.
Необходимо отметить, что при использовании данного способа потребуется дополнительное место для хранения новой целевой таблицы, однако данный вариант позволяет избежать ошибок и вернуться к исходному варианту, в случае если результат в целевой таблице не будет являться удовлетворительным.
В данной статье мы рассмотрели различные способы удаления дубликатов записей в таблицах БД SQL Server, которые могут быть использованы в работе в зависимости от задачи и объема данных.
При больших объемах дубликатов в данных целесообразно рассмотреть возможность сохранения уникальных значений в промежуточную таблицу, очистку рабочей таблицы, и возврат оставленных уникальных записей.
Удаление повторяющихся строк из SQL Server с помощью сценария
В этой статье приведен сценарий, который можно использовать для удаления повторяющихся строк из таблицы в Microsoft SQL Server.
Оригинальная версия продукта: SQL Server
Оригинальный номер базы знаний: 70956
Сводка
Существует два распространенных метода, которые можно использовать для удаления повторяющихся записей из таблицы SQL Server. В демонстрационных целях начните с создания образца таблицы и данных:
create table original_table (key_value int ) insert into original_table values (1) insert into original_table values (1) insert into original_table values (1) insert into original_table values (2) insert into original_table values (2) insert into original_table values (2) insert into original_table values (2) Затем попробуйте следующие методы, чтобы удалить повторяющиеся строки из таблицы.
Способ 1
Запустите следующий сценарий:
SELECT DISTINCT * INTO duplicate_table FROM original_table GROUP BY key_value HAVING COUNT(key_value) > 1 DELETE original_table WHERE key_value IN (SELECT key_value FROM duplicate_table) INSERT original_table SELECT * FROM duplicate_table DROP TABLE duplicate_table Этот сценарий выполняет следующие действия в указанном порядке:
- Перемещает один экземпляр любой повторяющейся строки в исходной таблице в дублирующую таблицу.
- Удаляет все строки из исходной таблицы, которые также находятся в дублирующей таблице.
- Перемещает строки в дублирующей таблице обратно в исходную таблицу.
- Удаляет дублирующую таблицу.
Этот метод прост в использовании. Однако для временного создания дублирующей таблицы в базе данных требуется достаточно места. Этот метод также влечет за собой дополнительные затраты, так как данные перемещаются.
Кроме того, если таблица содержит столбец IDENTITY, при восстановлении данных в исходной таблице необходимо использовать SET IDENTITY_INSERT ON.
Способ 2
Функция ROW_NUMBER, добавленная в Microsoft SQL Server 2005, значительно упрощает эту операцию:
DELETE T FROM ( SELECT * , DupRank = ROW_NUMBER() OVER ( PARTITION BY key_value ORDER BY (SELECT NULL) ) FROM original_table ) AS T WHERE DupRank > 1 Этот сценарий выполняет следующие действия в указанном порядке:
- Использует ROW_NUMBER функцию для разделения данных на основе key_value , в роли которого может выступать один или несколько столбцов, разделенных запятыми.
- Удаляет все записи, которые получили значение DupRank , превышающее 1. Это указывает на то, что записи являются дубликатами.
Из-за выражения (SELECT NULL) сценарий не сортирует разделенные данные на основе каких-либо условий. Если ваша логика удаления дубликатов требует выбора того, какие записи удалить, а какие оставить, основываясь на порядке сортировки других столбцов, можно использовать для этого выражение ORDER BY.
Дополнительная информация
Метод 2 является простым и эффективным по следующим причинам:
- Для этого не требуется временно копировать повторяющиеся записи в другую таблицу.
- При этом не требуется объединения исходной таблицы с самой собой (например, с помощью подзапроса, который возвращает все повторяющиеся записи с помощью комбинации GROUP BY и HAVING).
- Для достижения оптимальной производительности в таблице должен быть соответствующий индекс, который использует key_value в качестве ключа индекса и содержит любые столбцы сортировки, которые могли использоваться в выражении ORDER BY.
Однако этот метод не работает в устаревших версиях SQL Server, которые не поддерживают функцию ROW_NUMBER. В этом случае следует использовать метод 1 или аналогичный метод.
Обратная связь
Были ли сведения на этой странице полезными?