Основы памяти в Java: Куча и Стек
Узнайте, как устроена память в Java: разбор работы Java-стека и кучи, особенностей управления памятью и роли сборщика мусора в данном процессе.
2 авг. 2023 · 7 минуты на чтение
Мы всё активнее применяем современные языки программирования, обеспечивающие нам возможность писать минимум кода для решения проблем. Возьмём за пример Java: он был разработан с целью максимального упрощения жизни программистов. Вам не приходится заботиться о памяти — ваши мысли целиком направлены на решение бизнес-задач. Однако это облегчение имеет свою цену.
В прошлой статье, мы обсудили общее устройство памяти в компьютере. А в этой статье мы сосредоточимся на том, как язык Java работает с памятью. Это включает в себя обзор стека и кучи в контексте Java, а также их отличия от общего представления. Мы также немного обсудим роль сборщика мусора в управлении памятью.
В данной статье не разбирается JMM. Углубиться в эту тему вы можете ознакомившись с дополнительными материалами в конце статьи.
Спонсор поста
Устройство памяти в программировании
Переходим к анализу ключевых концепций программирования, связанных с управлением памятью. Сначала обсудим стек и кучу — два фундаментальных механизма, лежащих в основе управления памятью. Затем рассмотрим их взаимодействие и особенности работы в процессе выполнения функций и методов.
Стек и куча представляют собой области памяти, используемые программами для хранения данных во время выполнения, но они используются по-разному и для разных целей.
Стек (Stack)
Стек — это область памяти, где функции хранят свои переменные и информацию для выполнения. Представьте стек как физическую стопку подносов в ресторане: вы можете добавить поднос сверху (push) или взять верхний поднос (pop). Аналогично, когда функция вызывается, ее локальные переменные и информация о вызове кладутся на стек сверху, и забираются сверху (уничтожаются), когда функция завершает работу.
Стек обеспечивает быстрый доступ к данным и автоматическое управление памятью, но имеет ограниченный размер. Если ваша программа использует больше стековой памяти, чем доступно, программа может завершиться с ошибкой переполнения стека.
Куча (Heap)
Куча — это область памяти, где данные могут быть размещены динамически во время выполнения программы. В отличие от стека, где данные удаляются автоматически после выхода из функции, данные в куче остаются, пока их явно не удалить.
Это делает кучу идеальным местом для хранения данных, которые должны пережить вызов функции, или для работы с большими объемами данных. Однако работа с кучей требует аккуратного управления: если вы не удаляете объекты, когда они больше не нужны, может произойти утечка памяти, что в конечном итоге может привести к исчерпанию доступной памяти.
Для удобства визуализируем стек и кучу. Серые объекты потеряли свою ссылку из стека, их необходимо удалить, чтобы освободить память для новых объектов.
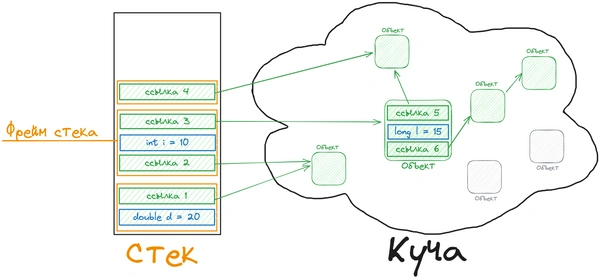
Объект может содержать методы, и эти методы могут содержать локальные переменные. Эти локальные переменные также хранятся в стеке потоков, даже если объект, которому принадлежит метод, хранится в куче.
Стек
Когда функция вызывается, для нее выделяется блок памяти на вершине стека. Этот блок памяти, известный как «фрейм стека», содержит пространство для всех локальных переменных функции, а также информацию, такую как возвращаемый адрес: адрес в коде, к которому следует вернуться после завершения функции.
Когда функция вызывает другую функцию, для новой функции выделяется свой фрейм стека, и она становится текущей активной функцией. Когда функция завершает свою работу, ее фрейм стека удаляется, и управление возвращается обратно в вызывающую функцию.
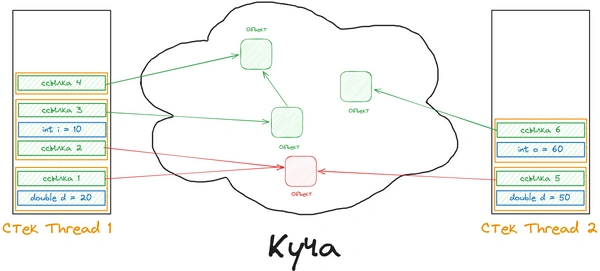
Синхронизация в Java служит для контроля доступа нескольких потоков к общим ресурсам. Синхронизация может быть реализована с использованием ключевого слова synchronized или специальных классов, таких как ReentrantLock или Semaphore .
Сборщик мусора в Java работает в многопоточной среде и способен обрабатывать объекты из всех потоков. Однако следует быть внимательным с долгоживущими объектами и ресурсами, которые могут заблокировать сборщик мусора.
Заключение
В контексте программирования, стек и куча играют различные, но важные роли. Стек служит для хранения информации о функциях и их вызовах, в то время как куча используется для динамического выделения памяти.
В случае с Java, управление памятью становится еще более интересным благодаря сборщику мусора, который автоматически освобождает неиспользуемую память, и разделению памяти на Heap Space и Stack Space. Эти особенности делают язык Java удобным для работы, но также требуют осознанного использования памяти для предотвращения проблем с производительностью.
В заключение, управление памятью — это сложная, но неотъемлемая часть работы с компьютерами и программным обеспечением. Понимание основ и принципов управления памятью может помочь разработчикам создавать более эффективные и надежные приложения.
Дополнительные материалы
- Habr: Глубокое погружение в Java Memory Model
- Habr: Откуда растут ноги у Java Memory Model
Введение в Java Process Memory Model
Каждое Java приложение, после запуска, создаёт десятки, сотни, тысячи объектов в памяти компьютера на котором оно запущено. Память, при этом, ресурс не бесконечный, и поэтому необходимо использовать его эффективно. Виртуальная Машина Java (Java Virtual Machine, далее JVM) умеет грамотно распоряжаться памятью и помогает нам, разработчикам, управляя ею автоматически.
О том, как именно JVM работает с памятью во время работы Java приложения мы поговорим в этой статье.
Зачем вообще разработчику знать о памяти Java процесса?
Java — это язык программирования с автоматическим управлением памятью.
Очень хороший вопрос. Действительно, Java — язык с автоматическим управлением памятью. Разработчику вообще можно ничего не знать о том, как JVM работает с ней. Но — можно ли с уверенностью сказать, что разработчик не влияет на работу его приложения с памятью? Нет, конечно же — нет.
Хотя JVM и выделяет память под созданные разработчиком объекты, прибирает ресурсы после их использования, далеко не так редко, как хотелось бы, возникают проблемы с утечкой памяти или её нехваткой. Проблемы такого рода не могут быть обработаны средствами JVM и требуют вмешательства человека.
Память Java процесса
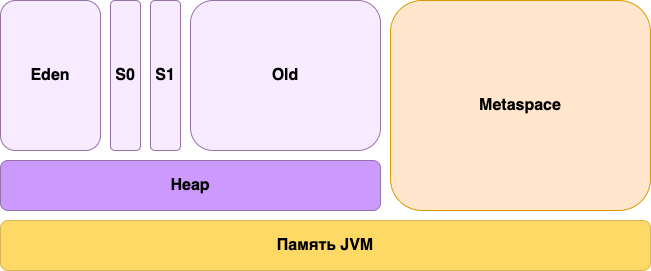
Память, выделяемая Java процессу, представляет из себя набор из двух областей:

- PermGen (до Java 8) / Metaspace (заменил PermGen, начиная с Java 8)
- Heap или Куча
Каждая из областей имеет собственное предназначение.
Metaspace
Metaspace — это область памяти в которой хранится статическая инфорация Java приложения, такая как метаданные загруженных классов. По умолчанию, metaspace увеличивается автоматически и не имеет явного ограничения. Без установленного ограничения размер metaspace неявно ограничен объёмом системной памяти хоста.
Управление Metaspace
Управлять metaspace областью можно с помощью следующих флагов JVM:
- -XX:MetaspaceSize — минимальный объём памяти для области
- -XX:MaxMetaspaceSize — максимальный объём памяти для области
- -XX:MinMetaspaceFreeRatio — минимально зарезервированный размер памяти после очистки GC (в процентах)
- -XX:MaxMetaspaceFreeRatio — максимально зарезервированный размер памяти после очистки GC (в процентах)
Heap
Heap — это область памяти в которой хранятся инстансы объектов. Каждый раз, когда разработчик создаёт инстанс какого-либо класса с помощью операции new (пример: new Object() ), память под объект выделяется именно в heap’е.
Строковый пул, так же, начиная с Java 7 располагается в heap’е.
Heap, в свою очередь, содержит несколько подобластей, каждая из которых выполняет свою определённую роль. Поговорим о них подробнее. Следующие подобласти относятся к heap’у:

- Eden
- Survival (S0 & S1)
- Old Gen
Eden
Это сегмент heap области в который свежесозданные объекты попадают в первую очередь. Каждый раз, когда в Java приложении выполняется инструкция new , память, выделяемая под новый инстанс, выделяется именно в Eden сегменте.
Для этого правила есть исключения — если размер памяти, необходимый для хранения инстанса достаточно большой, то JVM может выделить память под него сразу в Old Gen сегменте.
Надолго свежесозданные объекты в Eden сегменте не задержатся. После первого же запуска процесса сборки мусора, они либо будут удалены из памяти, либо будут перенесены в Survival сегменты heap’а.
S0 и S1 — Survival
Survival сегмент области heap’а используется JVM для хранения объектов, которые пережили один и более проходов сборщика мусора.
Survival сегмент представлен в JVM двумя сегментами — S0 и S1. Они служат неким «перевалочным пунктом» для объектов на пути к Old Gen сегменту. В S0 и S1 сегментах объекты могут провести какое-то время до тех пор, пока они не будут удалены из памяти или переведены в Old Gen сегмент.
Если быть точным, то в JVM есть настройка, позволяющая указать количество запусков сборки мусора, которое объект должен пережить, для того, чтобы попасть в Old Gen сегмент. По умолчанию, это количество равно 15.
Почему Survival область представлена двумя сегментами S0 и S1? Всё дело в том, что для ускорения очистки памяти и исправления её фрагментации, в ходе процесса сборки мусора два этих сегмента дефрагминтируются и меняются местами.
Old Gen
Old Gen сегмент heap’а используется для хранения объектов, которые пережили установленное количество запусков сборки мусора.
Полная схема памяти Java процесса выглядит следующим образом:
Управление Heap
Управлять heap областью можно с помощью следующих флагов JVM:
- -Xms — минимальный объём памяти всей области
- -Xmx — максимальный объём памяти всей области
- -XX:NewSize — минимальный объём памяти Eden сегмента
- -XX:MaxNewSize — максималный объём памяти Eden сегмента
- -XX:SurvivorRatio — соотношение между объёмами памяти Eden и Survival сегментов
Зачем использовать разные области и сегменты памяти? Потому что это позволяет организовать процесс сборки мусора наиболее оптимальным образом для каждого из сегментов, с учётом специфики каждого.
Где это может пригодиться?
Прежде всего грамотный разработчик знает особенности платформы с которой он работает. Поэтому знание того, как Java приложение работает с памятью позволяет не только козырять на собеседованиях, но и даёт возможность взглянуть на работу Вашего приложения с нового ракурса.
Если Вы заметили, что Вашего приложение неотзывчиво в некоторых сценариях или в целом, то первое на что стоит обратить внимание, так это на то, как Ваше приложение распоряжается отведённой ему памятью. Сделать это можно, например, с помощью VisualVM — бесплатной утилиты для мониторинга JVM приложений.
Заключение
В этой статье мы рассмотрели как выглядит память Java процесса, какие стадии проходит Java объект за время своей жизни. Так же мы узнали о флагах, которые позволяют контролировать работу JVM с памятью.
Работа JVM с памятью непосредственно связана с такой сложной темой как сборка мусора. И сегодня Вы сделали первый шаг на пути к пониманию потаённой стороны Java.
Список материалов
Дополнительные источники информации о коммуникациях, могут быть найдены в следующих источниках:
- «Презентация Troubleshooting Memory Issues in Java Applications» — краткое пояснение имеющихся областей памяти JVM.
- «Гайд по флагам JVM» — список полезных флагов JVM с пояснением.
- «HotSpot Virtual Machine Garbage Collection Tuning Guide» — официальный документ от Oracle о настройке сборщиков мусора. В нём можно найти описания областей памяти и их сегментов.
- https://fullstackguy.ru/blog/2022/05/24/jvm-process-memory-model/ — оригинал этой статьи на сайте моего образовательного проекта
Управление памятью Java
Это глубокое погружение в управление памятью Java позволит расширить ваши знания о том, как работает куча, ссылочные типы и сборка мусора.
Вероятно, вы могли подумать, что если вы программируете на Java, то вам незачем знать о том, как работает память. В Java есть автоматическое управление памятью, красивый и тихий сборщик мусора, который работает в фоновом режиме для очистки неиспользуемых объектов и освобождения некоторой памяти.
Поэтому вам, как программисту на Java, не нужно беспокоиться о таких проблемах, как уничтожение объектов, поскольку они больше не используются. Однако, даже если в Java этот процесс выполняется автоматически, он ничего не гарантирует. Не зная, как устроен сборщик мусора и память Java, вы можете создать объекты, которые не подходят для сбора мусора, даже если вы их больше не используете.
Поэтому важно знать, как на самом деле работает память в Java, поскольку это дает вам преимущество в написании высокопроизводительных и оптимизированных приложений, которые никогда не будут аварийно завершены с ошибкой OutOfMemoryError . С другой стороны, когда вы окажетесь в плохой ситуации, вы сможете быстро найти утечку памяти.
Для начала давайте посмотрим, как обычно организована память в Java:

Обычно память делится на две большие части: стек и куча. Имейте в виду, что размер типов памяти на этом рисунке не пропорционален реальному размеру памяти. Куча — это огромный объем памяти по сравнению со стеком.
Стек (Stack)
Стековая память отвечает за хранение ссылок на объекты кучи и за хранение типов значений (также известных в Java как примитивные типы), которые содержат само значение, а не ссылку на объект из кучи.
Кроме того, переменные в стеке имеют определенную видимость, также называемую областью видимости. Используются только объекты из активной области. Например, предполагая, что у нас нет никаких глобальных переменных (полей) области видимости, а только локальные переменные, если компилятор выполняет тело метода, он может получить доступ только к объектам из стека, которые находятся внутри тела метода. Он не может получить доступ к другим локальным переменным, так как они не входят в область видимости. Когда метод завершается и возвращается, верхняя часть стека выталкивается, и активная область видимости изменяется.
Возможно, вы заметили, что на картинке выше отображено несколько стеков памяти. Это связано с тем, что стековая память в Java выделяется для каждого потока. Следовательно, каждый раз, когда поток создается и запускается, он имеет свою собственную стековую память и не может получить доступ к стековой памяти другого потока.
Куча (Heap)
Эта часть памяти хранит в памяти фактические объекты, на которые ссылаются переменные из стека. Например, давайте проанализируем, что происходит в следующей строке кода:
StringBuilder builder = new StringBuilder();Ключевое слово new несет ответственность за обеспечение того, достаточно ли свободного места на куче, создавая объект типа StringBuilder в памяти и обращаясь к нему через «builder» ссылки, которая попадает в стек.
Для каждого запущенного процесса JVM существует только одна область памяти в куче. Следовательно, это общая часть памяти независимо от того, сколько потоков выполняется. На самом деле структура кучи немного отличается от того, что показано на картинке выше. Сама куча разделена на несколько частей, что облегчает процесс сборки мусора.
Максимальные размеры стека и кучи не определены заранее — это зависит от работающей JVM машины. Позже в этой статье мы рассмотрим некоторые конфигурации JVM, которые позволят нам явно указать их размер для запускаемого приложения.
Типы ссылок
Если вы внимательно посмотрите на изображение структуры памяти, вы, вероятно, заметите, что стрелки, представляющие ссылки на объекты из кучи, на самом деле относятся к разным типам. Это потому, что в языке программирования Java используются разные типы ссылок: сильные, слабые, мягкие и фантомные ссылки. Разница между типами ссылок заключается в том, что объекты в куче, на которые они ссылаются, имеют право на сборку мусора по различным критериям. Рассмотрим подробнее каждую из них.
1. Сильная ссылка
Это самые популярные ссылочные типы, к которым мы все привыкли. В приведенном выше примере со StringBuilder мы фактически храним сильную ссылку на объект из кучи. Объект в куче не удаляется сборщиком мусора, пока на него указывает сильная ссылка или если он явно доступен через цепочку сильных ссылок.
2. Слабая ссылка
Попросту говоря, слабая ссылка на объект из кучи, скорее всего, не сохранится после следующего процесса сборки мусора. Слабая ссылка создается следующим образом:
WeakReference reference = new WeakReference<>(new StringBuilder());Хорошим вариантом использования слабых ссылок являются сценарии кеширования. Представьте, что вы извлекаете некоторые данные и хотите, чтобы они также были сохранены в памяти — те же данные могут быть запрошены снова. С другой стороны, вы не уверены, когда и будут ли эти данные запрашиваться снова. Таким образом, вы можете сохранить слабую ссылку на него, и в случае запуска сборщика мусора, возможно, он уничтожит ваш объект в куче. Следовательно, через некоторое время, если вы захотите получить объект, на который вы ссылаетесь, вы можете внезапно получить null значение. Хорошей реализацией сценариев кеширования является коллекция WeakHashMap . Если мы откроем WeakHashMap класс в Java API, мы увидим, что его записи фактически расширяют WeakReference класс и используют его поле ref в качестве ключа отображения ( Map) :
/** * The entries in this hash table extend WeakReference, using its main ref * field as the key. */ private static class Entry extends WeakReference implements Map.Entry < V value;После сбора мусора ключа из WeakHashMap вся запись удаляется из карты.
3. Мягкая ссылка
Эти типы ссылок используются для более чувствительных к памяти сценариев, поскольку они будут собираться сборщиком мусора только тогда, когда вашему приложению не хватает памяти. Следовательно, пока нет критической необходимости в освобождении некоторого места, сборщик мусора не будет касаться легко доступных объектов. Java гарантирует, что все объекты, на которые имеются мягкие ссылки, будут очищены до того, как будет выдано исключение OutOfMemoryError . В документации Javadocs говорится, что «все мягкие ссылки на мягко достижимые объекты гарантированно очищены до того, как виртуальная машина выдаст OutOfMemoryError».
Подобно слабым ссылкам, мягкая ссылка создается следующим образом:
SoftReference reference = new SoftReference<>(new StringBuilder());4. Фантомная ссылка
Используется для планирования посмертных действий по очистке, поскольку мы точно знаем, что объекты больше не живы. Используется только с очередью ссылок, поскольку .get() метод таких ссылок всегда будет возвращаться null . Эти типы ссылок считаются предпочтительными для финализаторов.
Ссылки на String
Ссылки на тип String в Java обрабатываются немного по- другому. Строки неизменяемы, что означает, что каждый раз, когда вы делаете что-то со строкой, в куче фактически создается другой объект. Для строк Java управляет пулом строк в памяти. Это означает, что Java сохраняет и повторно использует строки, когда это возможно. В основном это верно для строковых литералов. Например:
String localPrefix = "297"; //1 String prefix = "297"; //2 if (prefix == localPrefix) < System.out.println("Strings are equal" ); >else < System.out.println("Strings are different"); >Строка localPrefix = «297» ; // 1При запуске этот код распечатывает следующее:
Strings are equal
Следовательно, оказывается, что две ссылки типа String на одинаковые строковые литералы фактически указывают на одни и те же объекты в куче. Однако это не действует для вычисляемых строк. Предположим, что у нас есть следующее изменение в строке // 1 приведенного выше кода.
String localPrefix = new Integer(297).toString(); //1Strings are different
В этом случае мы фактически видим, что у нас есть два разных объекта в куче. Если учесть, что вычисляемая строка будет использоваться довольно часто, мы можем заставить JVM добавить ее в пул строк, добавив .intern() метод в конец вычисляемой строки:
String localPrefix = new Integer(297).toString().intern(); //1При добавлении вышеуказанного изменения создается следующий результат:
Процесс сборки мусора
Как обсуждалось ранее, в зависимости от типа ссылки, которую переменная из стека содержит на объект из кучи, в определенный момент времени этот объект становится подходящим для сборщика мусора.
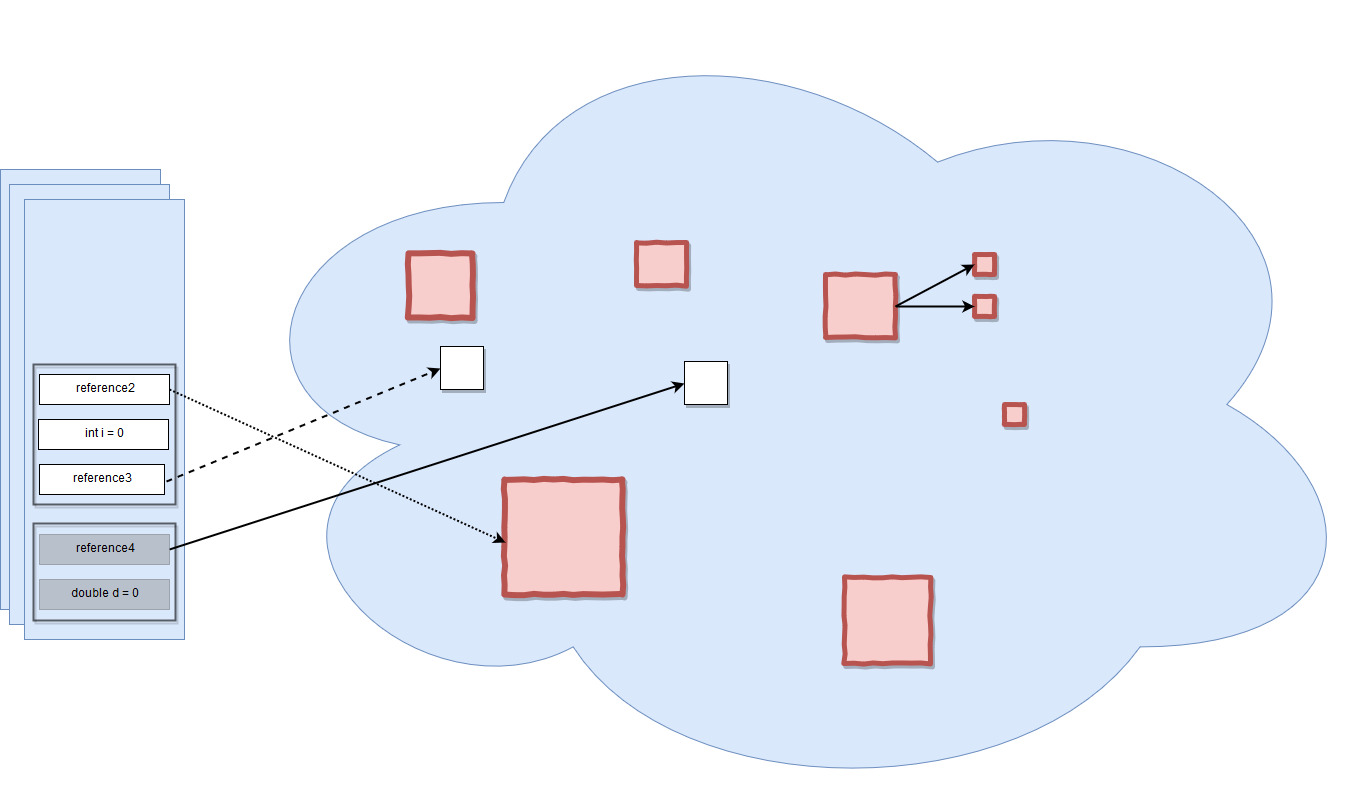
Например, все объекты, отмеченные красным цветом, могут быть собраны сборщиком мусора. Вы можете заметить, что в куче есть объект, который имеет строгие ссылки на другие объекты, которые также находятся в куче (например, это может быть список, который имеет ссылки на его элементы, или объект, имеющий два поля типа, на которые есть ссылки). Однако, поскольку ссылка из стека потеряна, к ней больше нельзя получить доступ, так что это тоже мусор.
Чтобы углубиться в детали, давайте сначала упомянем несколько вещей:
- Этот процесс запускается автоматически Java, и Java решает, запускать или нет этот процесс.
- На самом деле это дорогостоящий процесс. При запуске сборщика мусора все потоки в вашем приложении приостанавливаются (в зависимости от типа GC, который будет обсуждаться позже).
- На самом деле это более сложный процесс, чем просто сбор мусора и освобождение памяти.
Несмотря на то, что Java решает, когда запускать сборщик мусора, вы можете явно вызвать System.gc() и ожидать, что сборщик мусора будет запускаться при выполнении этой строки кода, верно?
Это ошибочное предположение.
Вы только как бы просите Java запустить сборщик мусора, но, опять же, Java решать, делать это или нет. В любом случае явно вызывать System.gc() не рекомендуется.
Поскольку это довольно сложный процесс и может повлиять на вашу производительность, он реализован разумно. Для этого используется так называемый процесс «Mark and Sweep». Java анализирует переменные из стека и «отмечает» все объекты, которые необходимо поддерживать в рабочем состоянии. Затем все неиспользуемые объекты очищаются.
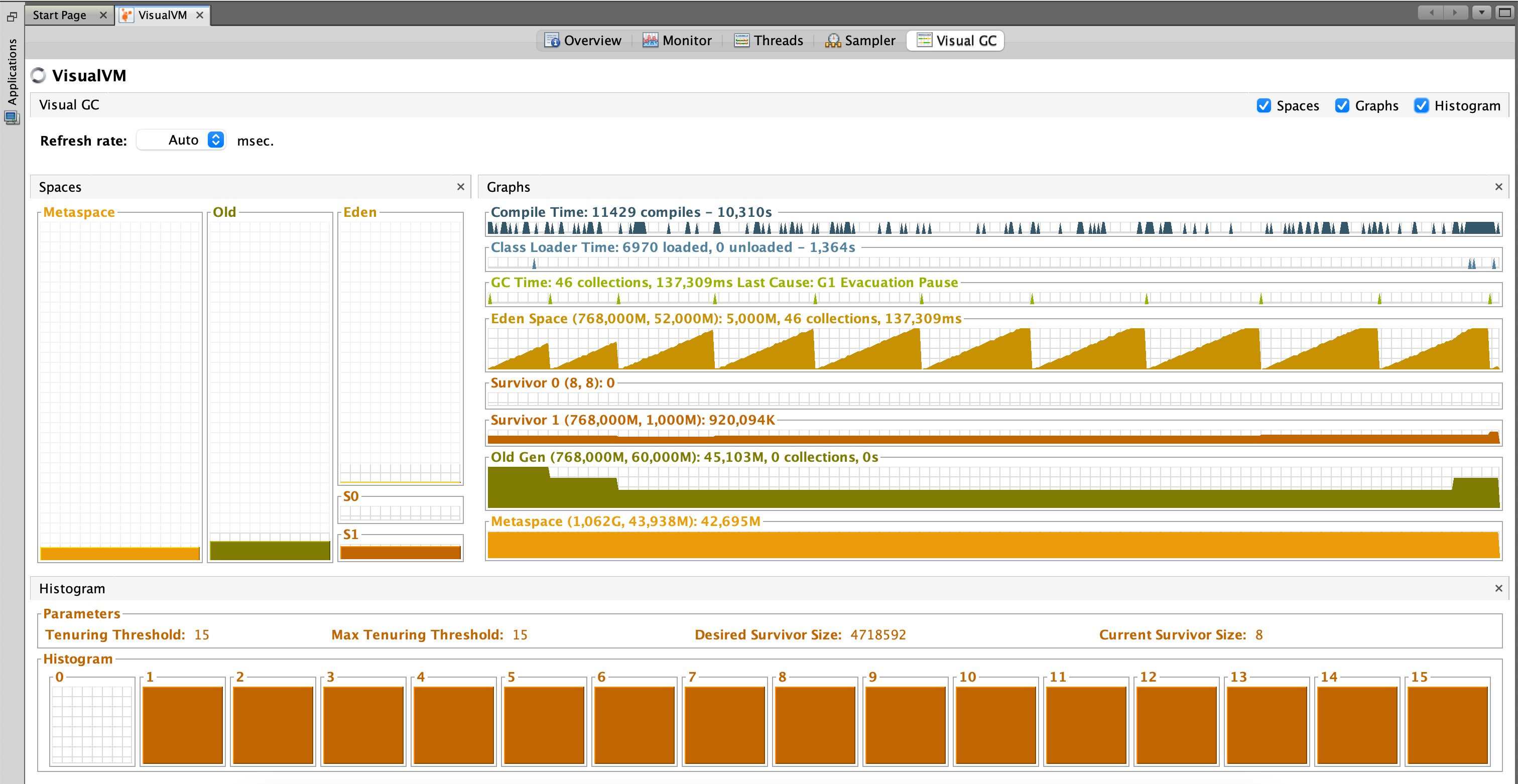
Так что на самом деле Java не собирает мусор. Фактически, чем больше мусора и чем меньше объектов помечены как живые, тем быстрее идет процесс. Чтобы сделать это еще более оптимизированным, память кучи на самом деле состоит из нескольких частей. Мы можем визуализировать использование памяти и другие полезные вещи с помощью JVisualVM, инструмента, поставляемого с Java JDK. Единственное, что вам нужно сделать, это установить плагин с именем Visual GC, который позволяет увидеть, как на самом деле структурирована память. Давайте немного увеличим масштаб и разберем общую картину:

Когда объект создается, он размещается в пространстве Eden (1). Поскольку пространство Eden не такое уж большое, оно заполняется довольно быстро. Сборщик мусора работает в пространстве Eden и помечает объекты как живые.
Если объект выживает в процессе сборки мусора, он перемещается в так называемое пространство выжившего S0(2). Во второй раз, когда сборщик мусора запускается в пространстве Eden, он перемещает все уцелевшие объекты в пространство S1(3). Кроме того, все, что в настоящее время находится на S0(2), перемещается в пространство S1(3).
Если объект выживает в течение X раундов сборки мусора (X зависит от реализации JVM, в моем случае это 8), скорее всего, он выживет вечно и перемещается в пространство Old(4).
Принимая все сказанное выше, если вы посмотрите на график сборщика мусора (6), каждый раз, когда он запускается, вы можете увидеть, что объекты переключаются на пространство выживших и что пространство Эдема увеличивалось. И так далее. Старое поколение также может быть обработано сборщиком мусора, но, поскольку это большая часть памяти по сравнению с пространством Eden, это происходит не так часто. Метапространство (5) используется для хранения метаданных о ваших загруженных классах в JVM.
Представленное изображение на самом деле является приложением Java 8. До Java 8 структура памяти была немного другой. Метапространство на самом деле называется PermGen область. Например, в Java 6 это пространство также хранит память для пула строк. Поэтому, если в вашем приложении Java 6 слишком много строк, оно может аварийно завершить работу.
Типы сборщиков мусора
Фактически, JVM имеет три типа сборщиков мусора, и программист может выбрать, какой из них следует использовать. По умолчанию Java выбирает используемый тип сборщика мусора в зависимости от базового оборудования.
1. Serial GC (Последовательный сборщик мусора) - однониточный коллектор. В основном относится к небольшим приложениям с небольшим использованием данных. Можно включить, указав параметр командной строки: -XX:+UseSerialGC.
2. Parallel GC (Параллельный сборщик мусора) - даже по названию, разница между последовательным и параллельным будет заключаться в том, что параллельный сборщик мусора использует несколько потоков для выполнения процесса сбора мусора. Этот тип GC также известен как сборщик производительности. Его можно включить, явно указав параметр: -XX:+UseParallelGC.
3. Mostly concurrent GC (В основном параллельный сборщик мусора). Если вы помните, ранее в этой статье упоминалось, что процесс сбора мусора на самом деле довольно дорогостоящий, и когда он выполняется, все потоки приостанавливаются. Однако у нас есть в основном параллельный тип GC, который утверждает, что он работает одновременно с приложением. Однако есть причина, по которой он «в основном» параллелен. Он не работает на 100% одновременно с приложением. Есть период времени, на который цепочки приостанавливаются. Тем не менее, пауза делается как можно короче для достижения наилучшей производительности сборщика мусора. На самом деле существует 2 типа в основном параллельных сборщиков мусора:
3.1 Garbage First - высокая производительность с разумным временем паузы приложения. Включено с опцией: -XX:+UseG1GC.
3.2 Concurrent Mark Sweep (Параллельное сканирование отметок) - время паузы приложения сведено к минимуму. Он может быть использован с помощью опции: -XX:+UseConcMarkSweepGC . Начиная с JDK 9, этот тип GC объявлен устаревшим.
Примечание переводчика. Информация про сборщики мусора для различных версий Java приведена в переводе:
Систематизированный список всех функций Java и JVM в Java 8-15
Советы и приемы
- Чтобы минимизировать объем памяти, максимально ограничьте область видимости переменных. Помните, что каждый раз, когда выскакивает верхняя область видимости из стека, ссылки из этой области теряются, и это может сделать объекты пригодными для сбора мусора.
- Явно устанавливайте в null устаревшие ссылки. Это сделает объекты, на которые ссылаются, подходящими для сбора мусора.
- Избегайте финализаторов (finalizer). Они замедляют процесс и ничего не гарантируют. Фантомные ссылки предпочтительны для работы по очистке памяти.
- Не используйте сильные ссылки там, где можно применить слабые или мягкие ссылки. Наиболее распространенные ошибки памяти - это сценарии кэширования, когда данные хранятся в памяти, даже если они могут не понадобиться.
- JVisualVM также имеет функцию создания дампа кучи в определенный момент, чтобы вы могли анализировать для каждого класса, сколько памяти он занимает.
- Настройте JVM в соответствии с требованиями вашего приложения. Явно укажите размер кучи для JVM при запуске приложения. Процесс выделения памяти также является дорогостоящим, поэтому выделите разумный начальный и максимальный объем памяти для кучи. Если вы знаете его, то не имеет смысла начинать с небольшого начального размера кучи с самого начала, JVM расширит это пространство памяти. Указание параметров памяти выполняется с помощью следующих параметров:
- Начальный размер кучи -Xms512m - установите начальный размер кучи на 512 мегабайт.
- Максимальный размер кучи -Xmx1024m - установите максимальный размер кучи 1024 мегабайта.
- Размер стека потоков -Xss1m - установите размер стека потоков равным 1 мегабайту.
- Размер поколения -Xmn256m - установите размер поколения 256 мегабайт.
Заключение
Знание того, как организована память, дает вам преимущество в написании хорошего и оптимизированного кода с точки зрения ресурсов памяти. Преимущество заключается в том, что вы можете настроить свою работающую JVM, предоставив различные конфигурации, наиболее подходящие для запуска вашего приложения. Выявление и устранение утечек памяти - это очень просто, если использовать правильные инструменты.
- memory management
- memory leaks
- garbage collection
- reference type
На какие области делится память JVM?
Следует помнить, что это внутренние особенности HotSpot (и её opensource-версии OpenJDK). В других виртуальных машинах (например в Android) всё может быть абсолютно по-другому. Области-поколения кучи вообще зависят от используемого алгоритма сборки мусора, и могут отличаться в рамках одной и той же реализации виртуальной машины. Как было сказано в предыдущих постах, некоторые сборщики не пользуются понятием поколений совсем.
Stack – место под примитивы и ссылки на объекты (но не сами объекты). Хранит локальные переменные и возвращаемые значения функций. Здесь же хранятся ссылки на объекты пока те конструируются. Все данные в стеке – GC roots. Освобождается сразу на выходе из функции. Принадлежит потоку, размер по-умолчанию указывается параметром виртуальной машины -Xss , но при создании потока программно можно указать отличное значение. Подробнее.
PermGen – В этой области хранятся загруженные классы (экземпляры класса Class ). Здесь же с Java 7 хранится пул строк. Изначально размера -XX:PermSize , растет динамически до -XX:MaxPermSize . Не считается частью кучи.
Metaspace – с Java 8 заменяет permanent generation. Отличие в том, что по умолчанию metaspace ограничен только размерами доступной на машине памяти, но так же как PermGen может быть ограничен, параметром -XX:MaxMetaspaceSize .
Heap – куча, вся managed-память, в которой хранятся все пользовательские объекты. Все следующие разделы – части кучи. Параметры -Xms , -Xmn и -Xmx устанавливают начальный, минимальный и максимальный размеры хипа соответственно.
Eden, New Generation, Old Generation и другие – специфичные для сборщика мусора части кучи, поколения. Могут быть разные, но общий подход сохраняется: долго живущий объект постепенно двигается во всё более старое поколение; сборка мусора в разных поколениях происходит раздельно; чем поколение старше, тем сборка в нём реже, но и дороже. Подробнее.Хотя устройство памяти – это детали реализации виртуальной машины, для Java-разработчика знания о них несут практическую пользу. Эти знания необходимы для передачи правильных значений параметров JVM, что в свою очередь спасает от просадок производительности GC и остановок с OutOfMemoryError .