Как обойти reCAPTCHA от Google. Самые простые методы и их реализация
Все мы понимаем и осознаем , для чего придумана р екапча. Но согласитесь , иногда она реально достает, поэтому рано или поздно почти перед каждым в стает вопрос, как обойти р екапч у . Как оказалось, обход р екапч и не так уж и сложен. Обойти возможно даже капчу от такой компании , как Google, при их — то возможностях…
Как обойти reCAPTCHA ?
- можно использовать ее особенные и слабоватые места;
- можно применить новейшие технологии обхода рекапч и .
- «взламывать» непосредственно «ручками», то есть изучается , как реализована конкретная капча ; изучаются способы , как обойти рекапч у, и реализуется самостоятельно;
- можно применять специализированные программы, чтобы осуществить «обход» рекапч и , то есть за вас уже «подумали» и создали ботов, которые способны массово и автоматизировано атаковать по несколько похожих сайтов, созданных на одинаковой платформе и использующих одинаковую капчу; таким образом подбираются «ключи» ко всем схожим сайтам и появляется возможность обойти рекапч у на них;
- как это н и странно, но путем использования «труда» реальных людей тоже можно обойти рекапч у .
Самые распространенные варианты, как обойти reCAPTCHA
- взлом защитника при использовании ошибок разработчиков при его создании;
- использование новейших технологий для преодоления и решения рекапч и .
Самые распространенные вариации обхода reCAPTCHA из-за недоработок программистов:
- Обойти рекапч у , используя фиксированный набор задач. Когда-то самописная реализаци я капчи на своем сайте был а очень популярным занятием. Различные вариации «лепились» повсеместно как опытными, так и малоопытными разработчиками. И получалось так, что редко кто задумывался о большой базе задач, вопросов или изображений, которые нужно было решать внутри капчи. И все , что было нужно , — определить «эту» базу, которая использовалась капчей. Дела лось это «ручным» трудом с использованием сторонних пользователей (об этом мы уже говорили выше ). Потом на такую базу составлялся скрипт-бот с использованием правильных решений , и все . Дальше уже з апускался бот , и можно было легко атаковать сайты, использующие именно это капчу. Применение таких методов защиты своего сайта практически сведено к нулю, но все же изредка , — встречаются «умельцы», которые пишут себе такие, простенькие для обхода, капчи.
- Создание сессий, чтобы совершить обход рекапч и . Бывает такое, что само исполнение капчи выполняет сохранение верного ответа внутри сессии. А она сама не исполняется вновь после вводимого ответа пользователем. В этом случае любые «желающие» имеют возможность отследить идентификатор сессии и разузнать истинное значение капчи. Опять же, собирая такие значения, можно вычислить алгоритм, как работает шифрование рекапч и и , соответственно , найти возможность его об хода . На основе полученных данных разрабатывается бот, который потом может использоваться для атак на сайты с подобной капчей.
- Обход рекапч и из-за информации, содержащейся непосредственно в коде. Это случай качественной реализации защиты, но с «ложкой дегтя» из-за невнимательности самого разработчика. Этот недочет и имеет применение. То есть в некотором исполнении капчи при переадресации ее значения на сервера, она дополняется информацией: IP пользователя, ID сессии или просто уникальной последовательностью разнообразных знаков. В данном случае решением для прохождения защиты считается полное совпадение значения капчи от юзеров с ее истинным значением, созданным и записанным внутри самой сессии. Но при этом учитываются еще дополнительные данные (ID, IP), чтобы совпадало не только значение капчи, но и идентификация сессии или компьютера , на котором была впервые показана эта капча. Подобная защита от ботов реально достойна. Однако встречается ее некачественное исполнение, когда эти дополнительные значения можно легко «вытащить» непосредственно из HTML — кода страницы. Таким образом, можно легко настроить своего бота, чтобы для обхода рекапч и он считывал дополнительные значения и отправлял на сервер весь набор значений для прохождения капчи.
- Обход рекапч и , не изменяя IP. Часто реализация защиты происходит без фиксирования попыток на количество возможных решений и без фиксирования ограничения по времени. В этом случае поможет бот, который просто будет очень быстро перебирать возможные правильные решения в поисках истинного. terasos stiklinimas ir sulankstomos durys При этом можно использовать скрипт-робот, который будет не только перебирать, а еще и обучаться и накапливать опыт.
- Обход рекапч и при использовании proxy. Это один из самых актуальных вариантов , как обойти рекапч у . Как вы знаете , так сложилось, что современная «безопасность» имеет возможность ограничить количество вводов капчи по времени или вообще блокировать определенный IP — адре с . Тут и приходят на помощь уже всем известные proxy-сервера. Ведь с их возможностями и при должной настройке можно легко «зашифровать» своего бота или свой комп, чтобы он полностью «проходил» контроль безопасности. А если все же на сайте происходит вывод капчи, то при своевременной смене IP и при правильном тайм — ауте можно научить своего бота искать истинное выполнение защитника столько времени, сколько на это понадоби тся . Такой способ, к примеру, получается использовать на сайте ВКонтакте, где капча выводи тся при определенном количестве однообразных действий с одного IP.
- Эмуляторы работы для обхода рекапч и . Бывает определенный вид защиты, когда для ее преодоления нужно выполнить какое-то действие — нажать на кнопочку, перенести ползунок и т.д. Тут как раз и может помочь имитирование подобных действий. Все , что нужно для этого сделать , — это найти координаты расположения относительно других элементов нужного элемента для управления им при помощи бота.
Новейшие технологии, используемые для обхода reCAPTCHA
- OCR — обход рекапч и . Этот принцип подразумевает использова ние возможност ей современных скриптов распознавать текст или изображение на картинке. То есть ваш бот, используя подобные скрипты, самостоятельно будет распознавать , что нужно ввести в поле рекапчи или на какие изображения нужно будет кликнуть для успешного прохождения защиты. В сети такие скрипты найти н ет рудно. Это обучаемые боты, они со временем собирают свою «базу» решенных задач и делают все очень быстро. Однако в целом такой вариант не всегда выдает 100%-ое решение, потому что часто текст на капче настолько искажен, что его не каждый человек разберет, а роботы тем более.
- Обход рекапч и при помощи нейронных сетей. Если первый метод используется уже давно и многие современные разработчики капчи к нему подготовились, то к использованию нейронных сетей для обхода защиты многие еще не готовы еще . Не сложно догадаться, что раз современный искусственный интеллект легко распознает фотографии (кто изображен, пол, марку одежды, дислокацию), то проблем с капчей у него не будет. На данный момент официально была создана программа для обхода капчи компанией Vicarious, которая показала потрясающий результат с 90%-ым показателем правильного прохождения защиты. В массы это т продукт не пошел, он был только демонстрационным. Однако применение ИИ в обходе безопасности было замечено уже многократно. А это значит, что есть люди, которым под силу «обуздать» ИИ при создании ботов, чтобы обойти рекапч у на сайтах. При должном поиске таких умельцев можно найти в сети.
- Обход рекапч и общедоступными сервисами. Многим покажется удивительным, но обход рекапч и от Google можно осуществить при помощи другой разработки Гугла — Google Speech Recognition. Данный сервис — это гордость Google в сфере распознавания картинок и голоса. Так как он дает возможность использовать API, то его интеграция в собственную программу для обхода рекапч и не будет трудной. В финале вы получаете бота, который за счет Google обходит безопасность , предоставляемую Гуглом.
Как обойти reCAPTCHA , используя других людей
Этот способ трудно отнести к какому-либо из способов, путей или направлений. Поэтому имеет смысл он нем рассказать отдельно.
Это один из самых древних способов обойти защиту, но , как ни странно, он единственный дает 100%-ый результат и вообще не зависит от сложности капчи.
Все , кто хоть раз сталкивался с вопросом, как заработать в И нтернете, находил такой вид заработка, как «Заработок на вводе капчи». Простые действия, вводишь символы, изображенные на картинке , в специальное поле и зарабатываешь ден еж ку. Но никто не задавался вопросом, а для чего это нужно делать и кто и за что платит?
А суть очень простая. Имеется специальный сервис, куда приходят люди заработать на вводе капчи. Но в этот же сервис могут прийти те, кому нужно это самое решение капчи. Одни предоставляют капчи и платят, другие решают их и зарабатывают.
Для облегчения самого процесса ввода и предоставления капчи данные сервисы используют API. И получается, что прохождение самой капчи происходит в режиме реального времени. «Заработчики» вводят капчу на странице сервиса, а по факту она сразу вводится на сторонних ресурсах.
Такой способ ввода капчи необязательно используют на отдельных сервисах. Часто на посещаемых ресурсах вас просят ввести капчу, чтобы доказать , что вы не робот, и после этого вы получ ае те доступ к какому-то контенту. Однако в ы вроде бы вводите на одном сайт е , а на самом деле благодаря API ваше действие фиксируется совершенно на другом ресурсе.
Как обойти reCAPTCHA — выводы
Согласитесь, что в целом идея с вводом капчи для ограждения своих ресурсов от ботов — неплохая. Но так как технологические разработки не стоят на месте , они работают во всех направлениях. С овершенствуется защита от вредоносных программ, но в т о ж е время с овершенствуются и методы, как их обходить, и в частности рекапч у .
Если подумать, то от ПО для автоматического обхода капчи еще возможно как-то уберечься, если подходить к этому вопросу серьезно, но вот от ввода капчи руками никуда не уйдешь. И поэтому , пока существуют сервисы, где можно заработать деньги за ввод капчи, будет существовать и возможность попадания на ваш сайт нежеланных гостей.
Плюс искусственный интеллект только начинает набирать обороты. И как он будет применяться, чтобы осуществить обход рекапч и , можно только догадываться.
Вот и получается, что рекапча — это вроде и защита сайта, но в т о ж е время и ее можно и обойти, если знать как.
Мы будем очень благодарны
если под понравившемся материалом Вы нажмёте одну из кнопок социальных сетей и поделитесь с друзьями.
Как обойти капчу Гугл

Итак задача: обойти капчу, желательно с первого раза.
Воспользуемся возможностями сверточных нейросетей, а именно vgg16.
Джентельменский набор, который используется:
- python 3.6.4
- tensorflow 2.0.0, keras 2.2.1
- opencv 4.1.2
Беглый анализ капч подобного вида показывает, что капча попадается в двух базовых вариантах:
— на 9 картинок (приведена в начале поста) и

Также, статистика по капчам говорит о том, что капчи попадаются как минимум в 20-ти категориях с говорящими названиями: автобусы, гидранты и т.п.
Та же статистика говорит, что можно сэкономить силы и не обрабатывать все 20-ть и более категорий, а остановиться на наиболее часто встречающихся:

Поэтому, нейросеть была обучена только на усеченном количестве категорий, и будет работать с категориями капч, которые наиболее вероятны, остальные будет пропускать.
Общий алгоритм работы будет выглядеть так:
- зашли на сайт с капчей, нажали «Я не робот»;
- сделали скрин капчи с экрана, если она совпадает с определенными категориями объектов;
- разрезали капчу на части;
- скормили каждый кусок капчи нейросети;
- понажимали на картинки, где объект распознан нейросетью;
- обработали ошибки, и возможно, прошлись по 2-му, 3-му кругу капчи.
Зашли на сайт с капчей, нажали «Я не робот»
Здесь воспользуемся фреймворком selenium в python.
import webbrowser,time,os,pyautogui from selenium import webdriver from selenium.webdriver.common.keys import Keys import random import os browser = webdriver.Firefox() browser.implicitly_wait(5) browser.get ('https://captcha.guru/ru/feedback/') time.sleep(5) iframe = browser.find_elements_by_tag_name('iframe')[0] browser.switch_to.frame(iframe) act = browser.find_element_by_css_selector('.recaptcha-checkbox-border') act.click() В коде видно, что капча появляется в отдельном так называемом фрейме. Это необходимо учитывать при переключениях между основным контентом и фреймами капчи.
После выполнения кода результат будет примерно следующий:
картинка

- получить категорию объекта капчи (здесь «мосты»);
- сохранить картинку в нужных пропорциях, если она в нужной категории объектов;
- разрезать картинку на 9 частей.
Сделали скрин капчи с экрана, если она совпадает с определенными категориями объектов
t=random.uniform(1, 4) #пауза между скачиваниями случайна browser.switch_to.default_content() iframe = browser.find_elements_by_tag_name('iframe')[3] browser.switch_to.frame(iframe) time.sleep(3) act = browser.find_element_by_xpath('/html/body/div/div/div[2]/div[1]/div[1]/div/strong') print(act.text) Здесь время t для случайной паузы, чтобы гугл, не слишком сразу определил нас как робота. Данную t мы применим позднее.
Этот код выведет категорию объекта, изображенного на капче (здесь «мосты»).
Задаем категории, с которыми будем работать, не пропуская:
a=['велосипеды','пешеходные переходы','гидрантами','автомобили','автобус'] Остальные категории отсекаются, так как они встречаются значительно реже, либо в капче 16-ть картинок вместо 9-ти.
Сделали скрин капчи с экрана, если она совпадает с определенными категориями объектов
Рассмотрим следующий фрагмент:
if act.text not in a: #обновили картинку с капчи act = browser.find_element_by_xpath('//*[@id="recaptcha-reload-button"]') act.click() time.sleep(t) browser.switch_to.default_content() iframe = browser.find_elements_by_tag_name('iframe')[3] #узнаем категорию капчи:автобусы,гидранты. browser.switch_to.frame(iframe) time.sleep(2) act = browser.find_element_by_xpath('/html/body/div/div/div[2]/div[1]/div[1]/div/strong') print(act.text) if act.text in a: #сохраняем картинку os.chdir('C:\\1\\') im=pyautogui.screenshot(imageFilename=str(0)+'.jpg',region=(509,411,495,495)) #нарезаем картинку img = Image.open('0.jpg') area1=(0,0,163,163) #спереди,сверху,справа,снизу) img1 = img.crop(area1) area2=(163,0,326,163) img2 = img.crop(area2) area3=(326,0,489,163) img3 = img.crop(area3) area4=(0,163,163,326) img4 = img.crop(area4) area5=(163,163,326,326) img5 = img.crop(area5) area6=(326,163,489,326) img6 = img.crop(area6) area7=(0,326,163,489) img7 = img.crop(area7) area8=(163,326,326,489) img8 = img.crop(area8) area9=(326,326,489,489) img9 = img.crop(area9) img1.save("1"+".png") img2.save("2"+".png") img3.save("3"+".png") img4.save("4"+".png") img5.save("5"+".png") img6.save("6"+".png") img7.save("7"+".png") img8.save("8"+".png") img9.save("9"+".png") Здесь вначале происходит проверка категории объекта. Если объект из категории «велосипеды»,«пешеходные переходы»,«гидранты»,«автомобили» либо «автобус», то программа работает далее. В противном случае, обновляет картинку капчи.
Далее картинка сохраняется по пути C:\1\vgg-net\0.jpg (в windows).
И нарезается с сохранением 9-ти файлов .png в этой же директории.
Скормили каждый кусок капчи нейросети
Понадобится предобученная модель нейросети, в которую для анализа будут поступать нарезанные картинки.
from keras.models import load_model import argparse import pickle import cv2 def prescript(file): # функция нейросети ap = argparse.ArgumentParser() ap.add_argument("-i", "--image",type=str, default=file,help="path to input image we are going to classify") ap.add_argument("-m", "--model",type=str,default="simple_nn.model",help="path to trained Keras model") ap.add_argument("-l", "--label-bin",type=str,default="simple_nn_lb.pickle",help="path to label binarizer") ap.add_argument("-w", "--width", type=int, default=32, help="target spatial dimension width") ap.add_argument("-e", "--height", type=int, default=32, help="target spatial dimension height") ap.add_argument("-f", "--flatten", type=int, default=1, help="whether or not we should flatten the image") args = vars(ap.parse_args()) image = cv2.imread(file) output = image.copy() image = cv2.resize(image, (args["width"], args["height"])) image = image.astype("float") / 255.0 if args["flatten"] > 0: image = image.flatten() image = image.reshape((1, image.shape[0])) else: image = image.reshape((1, image.shape[0], image.shape[1], image.shape[2])) model = load_model(args["model"]) lb = pickle.loads(open(args["label_bin"], "rb").read()) preds = model.predict(image) i = preds.argmax(axis=1)[0] label = lb.classes_[i] text = "<>: %".format(label, preds[0][i] * 100) print(text[0]) # 1-предмет есть на картинке, 0 - предмета нет global result result = text[0] Нейросеть помещена в функцию, которая отдает либо 1 (‘объект есть на картинке’) либо 0 (‘нет объекта’).
Еще одна функция, с помощью которой будем кликать по картинкам, если нейросеть вернула ‘1’ (наличие объекта):
def clicks(x,y): if result=='1': # если предмет есть на картинке, нажимаем на картинку act = browser.find_element_by_xpath('/html/body/div/div/div[2]/div[2]/div/table/tbody/tr['+str(x)+']/td['+str(y)+']') act.click() Ну и собственно, функция, которая будет вызывать 9-ть раз (картинок 9 штук) функцию нейросети и функцию «нажимания на картинки»:
def predict(): prescript("1"+".png") clicks(1,1) prescript("2"+".png") clicks(1,2) prescript("3"+".png") clicks(1,3) prescript("4"+".png") clicks(2,1) prescript("5"+".png") clicks(2,2) prescript("6"+".png") clicks(2,3) prescript("7"+".png") clicks(3,1) prescript("8"+".png") clicks(3,2) prescript("9"+".png") clicks(3,3) act = browser.find_element_by_css_selector('#recaptcha-verify-button') act.click() time.sleep(1) predict() Обработали ошибки, и возможно, прошлись по 2-му, 3-му кругу капчи
Иногда, после даже после нажатий на «правильные» картинки капчи, предлагается заново ее пройти с фразами: «Попробуйте еще раз», «Вы слишком стары для этого» и т.п.
Поэтому добавим код для учета ситуаций:
try: act = browser.find_element_by_css_selector('.rc-imageselect-error-dynamic-more') #Посмотрите также новые изображения. captcha() # заново сохраняем картинки predict() # заново распознаем картинки except: try: act = browser.find_element_by_css_selector('.rc-imageselect-incorrect-response')#Повторите попытку. captcha() # заново сохраняем картинки predict() # заново распознаем картинки except: pass О минусах реализации:
- работает не со всеми категориями картинок (это сделано намеренно, чтобы облегчить размер модели);
- ошибается (все-таки обучающий набор был не размера imagenet, а google неохотно отдавал экземпляры для обучения);
- работает неспеша, так как последовательно обрабатывается каждая из 9-ти картинок;
- не работает с 16-сегментными картинками.
Программы для скачивания (программа и модель) — скачать.
Сервис для обхода капчи
Анти капча сервис для автоматического распознавания капчи онлайн
Ваши капчи решаются с высокой точностью. Начать работу очень просто:
- Зарегистрируйтесь
- Используйте наше API
- Отправляйте изображения
- Получайте ответ на изображения
Это быстро и просто! ruCaptcha – это высокая точность распознавания и низкие цены.
Обход reCAPTCHA
- ruCaptcha — лучший сервис по обходу капч Google. Оплата происходит только за решенные капчи. Нагрузка на сервер на влияет на цену.
- Сервис анти капчи позволяет решать все типы капч: reCAPTCHA v2, v2 callback, v2 invisible, v3 and Enterprise.
- Как обойти reCAPTCHA? Используйте API для обхода капч. Примеры кода.
- ruCaptcha позволяет распознавать капчи Google на любых сайтах.
- reCAPTCHA Enterprise bypass
- reCAPTCHA V2 bypass
- reCAPTCHA V2 Callback bypass
- reCAPTCHA V2 Invisible bypass
- reCAPTCHA V3 bypass
Selenium
Автоматизация обхода капчи:
- Сервис решения капчи в Selenium
- Пример: Как решить reCAPTCHA в Selenium
Puppeteer
Автоматизация решения капчи:
- Сервис обхода капчи в Puppeteer
- Пример: Как обойти reCAPTCHA с помощью расширения
Поддерживаемые API-клиенты:
- Обход капчи на Python
- Обход капчи на PHP
- Обход капчи на Ruby
- Авто-решение и прохождение капчи на Go
- Авто-распознавание капчи на C#
- Авто-решение капчи на Java
Лёгкий переход на ruCaptcha с сервисов DBC, DeCaptcher, Antigate (Anti-captcha)
Наш сервис работает с:
Поддерживаемые капчи
- Простая капча
- Текстовая капча
- Click CAPTCHA
- Rotate CAPTCHA
- reCAPTCHA V2
- reCAPTCHA V2 Callback
- reCAPTCHA V2 Invisible
- reCAPTCHA V3
- reCAPTCHA Enterprise
- KeyCAPTCHA
- GeeTest CAPTCHA
- hCaptcha
- Arkose Labs captcha (FunCaptcha)
- Capy Puzzle CAPTCHA
- Lemin CAPTCHA
- Cloudflare Turnstile
- Audio CAPTCHA
- Amazon CAPTCHA
- MTCaptcha
- DataDome CAPTCHA
- CyberSiARA CAPTCHA
- Cutcaptcha
- Friendly CAPTCHA
- VK CAPTCHA
Процесс решения обычной капчи заключается в следующем: мы забираем изображение капчи со страницы ее размещения и передаем в сервис ruCaptcha, где ее решает работник, после чего нам возвращается ответ, который необходимо ввести в соответствующее поле для решения капчи
Процесс решения текстовой капчи заключается в следующем: мы забираем текстовый вопрос капчи со страницы ее размещения и передаем в сервис ruCaptcha, где ее решает работник, после чего нам возвращается ответ, который необходимо ввести в соответствующее поле для решения капчи
Процесс решения заключается в следующем: мы забираем изображение капчи со страницы ее размещения и инструкцию, по каким картинкам необходимо кликать и передаем в сервис ruCaptcha, где ее решает работник, после чего нам возвращается ответ в виде набора координат точек на изображении, по которым необходимо кликнуть для решения капчи
Процесс решения Rotate Captcha заключается в следующем: мы забираем изображение капчи со страницы ее размещения и передаем в сервис ruCaptcha, где ее решает работник, после чего нам возвращается ответ в виде значения угла поворота изображения, на который необходимо повернуть изображение для решения капчи
Процесс решения reCAPTCHA V2 заключается в следующем: мы забираем параметры капчи, необходимые для ее решения в виде параметра data-sitekey и адреса страницы размещения капчи и передаем их в сервис ruCaptcha, где ее решает работник, после чего нам возвращается ответ в виде токена, который необходимо ввести в соответствующее поле для решения капчи
Процесс решения reCAPTCHA V2 Callback не отличается от аналогичного процесса решения reCAPTCHA V2: мы забираем параметры капчи, необходимые для ее решения в виде параметра data-sitekey и адреса страницы размещения капчи и передаем их в сервис ruCaptcha, где ее решает работник, после чего нам возвращается ответ в виде токена, который необходимо ввести в соответствующее поле для решения капчи. Иногда вы не найдете кнопки, отправляющей форму. Вместо нее может использоваться callback-функция. Эта функция выполняется, когда капча распознана. Обычно callback-функция определена в параметре data-callback или как параметр callback у функции grecaptcha.render
Процесс решения невидимой капчи reCAPTCHA V2 Invisible аналогичен распознаванию reCAPTCHA V2 и заключается в следующем: мы забираем параметры капчи, необходимые для ее решения в виде параметра data-sitekey и адреса страницы размещения капчи и передаем их в сервис ruCaptcha, где ее решает работник, после чего нам возвращается ответ в виде токена, который необходимо ввести в соответствующее поле для решения капчи
Процесс решения reCAPTCHA V3 следующий: мы забираем параметры капчи, необходимые для ее решения в виде параметра data-sitekey, параметра action и адреса страницы размещения капчи и передаем их в сервис ruCaptcha, где ее решает работник с соответствующим рейтингом «человечности”, после чего нам возвращается ответ в виде токена, который необходимо ввести в соответствующее поле для решения капчи. Во многом новый вид капчи похож на reCAPTCHA V2, т.е. основной принцип остался тем же — пользователь получает от API ruCaptcha токен, который отправляется в POST-запросе к сайту, а сайт верифицирует токен через API reCAPTCHA
Процесс решения reCAPTCHA Enterprise заключается в следующем: определяем тип reCAPTCHA, он может быть V2 или V3, после чего мы забираем параметры капчи, необходимые для ее решения в виде параметра data-sitekey и адреса страницы размещения капчи и передаем их в сервис ruCaptcha, где ее решает работник, после чего нам возвращается ответ в виде токена, который необходимо ввести в соответствующее поле для решения капчи
Процесс решения KeyCaptcha заключается в следующем: мы забираем набор необходимых параметров со страницы ее размещения и передаем в сервис ruCaptcha, где ее решает работник, после чего нам возвращается ответ в виде набора уже других параметров, который необходимо передать в соответствующие поля для решения капчи
Процесс решения GeeTest Captcha заключается в следующем: мы забираем набор необходимых параметров со страницы ее размещения и передаем в сервис ruCaptcha, где ее решает работник, после чего нам возвращается ответ в виде набора уже других параметров, который необходимо передать в соответствующие поля для решения капчи
Процесс решения заключается в следующем: мы забираем параметры капчи, необходимые для ее решения в виде параметра data-sitekey и адреса страницы размещения капчи ruCaptcha и передаем их в сервис ruCaptcha, где ее решает работник, после чего нам возвращается ответ в виде токена, который необходимо ввести в соответствующее поле для решения капчи
Процесс решения FunCaptcha Arkose Labs заключается в следующем: мы забираем набор необходимых параметров со страницы ее размещения и передаем в сервис ruCaptcha, где ее решает работник, после чего нам возвращается ответ в виде набора уже других параметров, который необходимо передать в соответствующие поля для решения капчи
Процесс решения Capy Puzzle Captcha заключается в следующем: мы забираем набор необходимых параметров со страницы ее размещения и передаем в сервис ruCaptcha, где ее решает работник, после чего нам возвращается ответ в виде набора уже других параметров, который необходимо передать в соответствующие поля для решения капчи
Процесс обхода Lemin заключается в следующем: пользователь передает параметры капчи, необходимые для ее решения в сервис ruCaptcha, где решает работник, после чего нам возвращается ответ в виде токена, который необходимо ввести в соответствующее поле для решения капчи.
Процесс решения капчи Cloudflare Turnsitle заключается в следующем: пользователь передает параметры капчи, необходимые для ее решения: «data-sitekey» и адрес страницы размещения капчи в сервис ruCaptcha, где ее решает работник, после чего нам возвращается ответ в виде токена, который необходимо ввести в соответствующее поле для решения капчи.
Процесс обхода аудио капчи полностью автоматизирован: в сервис распознавания нужно передать аудиофайл, который обрабатывается нейронной сетью, обученной распознаванию голоса. Результат распознавания возвращается в виде текста. Полученный текст можно использовать для обхода аудио капчи или перевода аудио в текст.
Процедура решения капчи Amazon AWS следующая: нужно передать набор необходимых параметров с целевой страницы и отправить в сервис, где работники сервиса решают капчу. Затем ответ возвращается в виде набора дополнительных параметров, которые необходимо ввести в поля для решения.
Процедура решения MTCaptcha следующая: нужно передать набор необходимых параметров с целевой страницы и отправить в сервис, где работники сервиса решают капчу. Затем ответ возвращается в виде токена, который необходимо ввести в соответствующее поле для решения капчи.
Процедура решения DataDome CAPTCHA следующая: нужно передать набор необходимых параметров с целевой страницы и отправить в сервис, где работники сервиса решают капчу. Затем ответ возвращается в виде токена, который необходимо ввести в соответствующее поле для решения капчи.
Процедура решения капчи CyberSiARA следующая: нужно передать набор необходимых параметров с целевой страницы и отправить в сервис, где работники сервиса решают капчу. Затем ответ возвращается в виде токена, который необходимо ввести в соответствующее поле для решения капчи.
Процесс обхода Cutcaptcha следующий: вы отправляете в сервис необходимые параметры со страницы, где она размещена, сервис передает запрос на решение работнику. Затем ответ отправляется вам обратно в виде параметров, которые необходимо ввести в соответствующие поля для решения.
Процесс обхода Friendly Captcha следующий: вы отправляете в сервис необходимые параметры со страницы, где она размещена, сервис передает запрос на решение работнику. Затем ответ отправляется вам обратно в виде параметров, которые необходимо ввести в соответствующие поля для решения.
Процесс решения капчи VK следующий: мы импортируем изображение капчи со страницы размещения и отправляем в ruCaptcha, после чего капчу решает работник, и нам возвращается ответ, который необходимо ввести в соответствующее поле для решения капчи.
Разметка данных
Платформа маркировки и аннотации данных для AI/ML компаний, которым требуется обучение моделей:
- Сервис для bounding box разметки изображения
- Примеры запросов к API
Обход капч с помощью Headless Chrome
Вот уже лет десять мы видим капчи по всему интернету. Все эти волнистые линии, слова или числа, мешающие нам при попытке залогиниться, зарегистрироваться или написать где-нибудь комментарий.
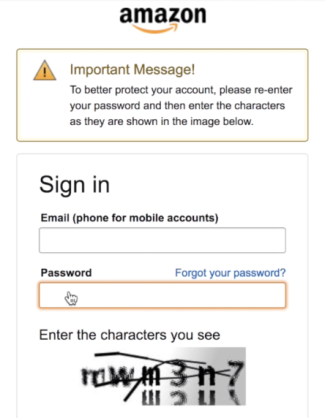
Amazon’s CAPTCHA fallback
КАПЧА (от CAPTCHA англ. – полностью автоматизированный и общедоступный тест Тьюринга для различения компьютеров и людей) задумана как врата, которые пропускают людей и отсеивают роботов (программ). Волнистые линии и слова сейчас уже не так распространены –их заменила вторая версия реКАПЧИ от Google. Эта капча выдает вам зеленую галочку, если ваш «коэффициент человечности» оценивается как достаточно высокий.
Если же вы не дотянули до заданного порога «человечности», то реКАПЧА прибегает к использованию подобной паззлу картинки, которая на удивление эффективна скорее в том, чтобы еще сильнее действовать на нервы, по сравнению с расшифровкой пары слов.

При том, что людей КАПЧИ раздражают, их можно было бы и потерпеть, если бы они хотя бы выполняли свою работу, однако, зачастую гораздо проще автоматизировать их распознавание, чем постоянно доказывать, что вы человек.
Как работает 2Captcha
2Captcha решает много разных типов капчи. Для взаимодействия с 2Captcha используются два адреса: на in.php присылается задача и в ответ Вы получаете captcha_id, на res.php вы по captcha_id получаете ответ, когда он будет готов.
2Captcha решает капчи в нескольких различных стилях с помощью двух, по большей части одних и тех же, конечных точек обработки запросов. Первый запрос передает данные, необходимые для решения капчи, и возвращает ID запроса. В случае капчи на основе изображения, данные будут изображением самой капчи, закодированным в 64base.
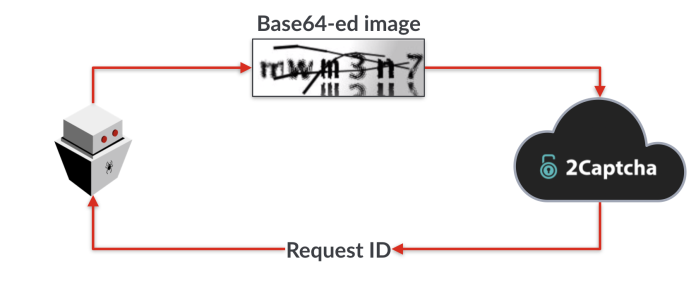
После получения ID запроса, вам нужно будет повторно отправлять его на сервер 2капчи, пока решение не будет готово.
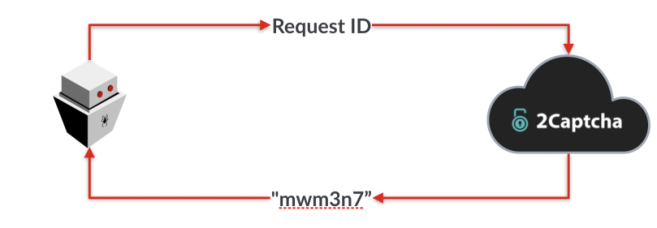
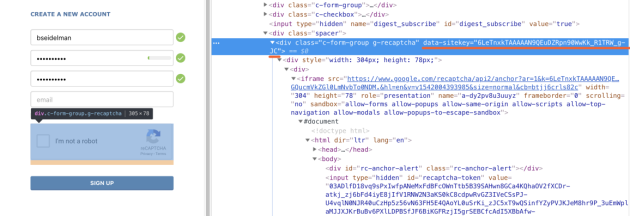
С Recaptcha V2 история немного другая. Вы по-прежнему имеете дело с двухступенчатым процессом, что и представленный выше, но отправляете другие данные. Теперь вам нужно отправлять публичный ключ рекапчи (reCAPTCHA sitekey), который можно найти среди атрибутов элемента-контейнера капчи, независимо от того, был ли загружен
Получаемый ответ – это токен, который нужно отправить вместе с формой и ввести в скрытое текстовое поле с идентификатором g-recaptcha-response. Скриншот ниже показывает, где оно находится, и я специально отключил CSS-свойство display: none, чтобы показать его на странице. Имея возможность редактировать это поле, вам будет проще вручную протестировать ответ 2Captcha, чтобы сократить количество переменных при тестовой интеграции.
Для капч, основанных на изображениях, результат доступен почти мгновенно. Для реКАПЧ версии 2 может потребоваться от 15 до 30 секунд.
Автоматизация через Puppeteer
Прежде чем беспокоиться о капче, нужно разобраться со всем прочим, но прежде чем мы сможем это сделать, нужно определиться с нашими инструментами. 3 причины, по которым в данном посте мы будем использовать Google’s Chrome:
- В нем все очень легко автоматизируется через Puppeteer API.
- На нем можно работать как в headless-режиме, так и с графическим интерфейсом, что очень удобно и практично.
- Это самый распространенный в мире браузер, поэтому все имеющиеся на сайтах приемы анти-автоматизации имеют меньший шанс срабатывания (например, блокировка Selenium или PhantomJS)
Использование Puppeteer
Необязательно устанавливать хром, если не хочется, в Puppeteer есть все необходимое, в том числе Chromium. Но можете использовать и локально установленный Chrome, решать вам.
$ npm install puppeteerУбедитесь, что все настроено, устроив предварительный тест. Для этого упражнения мы будем автоматизировать страницу регистрации Reddit, просто потому что это была первая страница с рекапчей, которая мне попалась.
const puppeteer = require('puppeteer'); const chromeOptions = < headless:false, defaultViewport: null>; (async function main() < const browser = await puppeteer.launch(chromeOptions); const page = await browser.newPage(); await page.goto('https://old.reddit.com/login'); >)()В этом коде мы указываем два свойства конфигурации при запуске: headless: false, чтобы видеть то, что мы делаем, и defaultViewport: null, чтобы учесть неприятный визуальный глитч, при котором область просмотра не заполняет окно. Ни тот, ни другой не важны для работы браузера в headless-режиме, просто с ними удобней видеть и, что самое важное, делать скриншоты. Например, такой:
Это было просто! Теперь мы готовы перейти к следующему шагу – автоматизировать регистрацию так, будто капчи никогда и не было. Вот где возможность включать/ выключать headless-режим будет полезна, ведь мы можем управлять браузером от лица человека, когда нужно. Сначала следует понять, как получить доступ к элементам на странице, которые нужно поменять. Запустите браузер и просмотрите открытую страницу через инструменты разработчика Google Chrome (горячая клавиша – F12). Далее, найдите текстовые поля, которые нужно будет изменить. (горячие клавиши: ⌘+Shift+C на Mac и Ctrl+Shift+C на Windows) В случае с Reddit, нам нужно получить прямой доступ к полю ввода логина, двум полям ввода пароля и кнопке. Электронная почта необязательна, так что можем ее проигнорировать. Печать в текстовых полях через API библиотеки Puppeteer почти до смешного проста: вы просто передаете селектор, который идентифицирует элемент, и желаемую строку с помощью метода .type().
await page.type('#user_reg', 'some_username'); await page.type('#passwd_reg', 'SuperStrongP@ssw0rd'); await page.type('#passwd2_reg', 'SuperStrongP@ssw0rd');Производить операции с кнопкой так же удобно, разве что у кнопки на странице Reddit нет связанного с ней идентификатора, так что нам нужен более сложный селектор. Если вы не знакомы с селекторами CSS, то для краткого ознакомления посмотрите Mozilla Developer Network.
await page.click('#register-form button[type=submit]');Вот и всё! Протестируйте скрипт, чтобы удостовериться, что отправка логина работает. Из-за КАПЧИ, конечно, ничего не получится, но зато мы можем протестировать работу хуков.
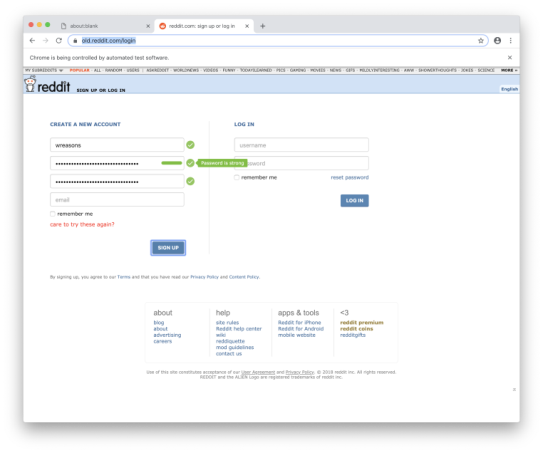
Подождите-ка! Мы ведь даже не видим капчу, и консоль JavaScript жалуется на ошибки. Что здесь происходит? Во время автоматизации веб-страниц, помимо капч, есть множество других препятствий, которые могут встать у вас на пути. И одна из них – настолько высокая скорость выполнения операций, что страница ломается. Когда браузеры автоматизированы, они работают во много-много раз быстрее, чем на то способен обычный человек, и зачастую это приводит к выполнению кода в таком порядке, в каком разработчики его не тестировали (это называется состоянием гонки или неопределённость параллелизма).
Страница Reddit страдает от состояния гонки, тогда как Google выводит реКАПЧУ после фокусировки на втором поле ввода пароля. То есть наш скрипт выполняется c такой скоростью, что смена фокуса происходит до того, как готов скрипт реКАПЧИ. Есть много решений этой проблемы, но самое простое – добавить минимальную задержку, необходимую, чтобы миновать это состояние гонки. Мы могли бы добавить хуки и обработчики событий, чтобы убедиться, что мы действуем только после того, как рекапча загрузилась, но, похоже, самих разработчиков Reddit состояние гонки устраивает, так что нам нет необходимости умничать. Есть много способов организовать задержку, но в опциях Puppeteer, связанных с запуском браузера, есть параметр «slowMo», который глобально задерживает все действия на заданное значение. Это очень грубый подход, так как замедляются вообще все действия Puppeteer, но начать с этого можно.
const chromeOptions = < headless:false, defaultViewport: null, slowMo:10, >;После добавления этой опции мы видим, что капча снова работает. Ради забавного эксперимента, можно попробовать пройти капчу прямо сейчас и посмотреть что будет. Поскольку мы используем вариант Chromium с настройками по умолчанию, который запускается библиотекой Puppeteer, и мы управляем им через средства автоматизации, то реКАПЧА будет изо всех сил пытаться доказать, что мы не человек. Вам, вероятно, придется пройти несколько уровней проверки, даже если вы разберетесь со всеми картинками. Когда я тестировал это, мне пришлось пройти через 10 различных повторений, прежде чем я получил зеленую галочку.
К счастью, все это можно сделать намного легче.
Настройка 2Captcha
2Captcha требует API ключ, который выдается при регистрации. Вам также потребуется какое-то количество средств, потому что, не всё в жизни бесплатно. И просто ради смеха, конечно же, вам понадобиться пройти КАПЧУ.
`http://2captcha.com/res.php?key=$&action=get&id=$`;2Captcha’s API работает через двухступенчатый процесс, где вы отправляете данные КАПЧИ и получаете результат после возврата ID запроса. Поскольку мы имеем дело с reCaptcha v2, нам нужно будет отправить публичный ключ Reddit, о котором говорилось ранее. Нам также нужно убедиться, что мы выбрали метод userrecaptcha и отправляем URL страницы, на которой расположена реКАПЧА.
const formData = < method: 'userrecaptcha', key: apiKey, // your 2Captcha API Key googlekey: '6LeTnxkTAAAAAN9QEuDZRpn90WwKk_R1TRW_g-JC', pageurl: 'https://old.reddit.com/login', json: 1 >; const response = await request.post('http://2captcha.com/in.php', ); const requestId = JSON.parse(response).request;После того как вы сделали этот запрос и получили обратно идентификатор запроса, вам нужно запросить URL «res.php», используя ваши ключ API и идентификатор запроса, чтобы получить ответ.
Если ваша капча не готова, вы получите ответ «CAPTCHA_NOT_READY», что указывает на то, что нужно попробовать ещё раз через секунду или две. Когда капча готова, ответом будут данные, соответствующие выбранному методу отправки. Для капчи, основанной на изображении – это будет решение. Для reCaptcha V2 – данные, которые нужно отправить в полях формы.
Для reCaptcha V2 время нахождения решения может различаться – минимум 15 секунд, максимум – 45. Ниже показан пример механизма опроса, но в этот раз простого запроса по URL, который может быть интегрирован в ваше приложение так, как вам будет удобно.
async function pollForRequestResults( key, id, retries = 30, interval = 1500, delay = 15000 ) < await timeout(delay); return poll(< taskFn: requestCaptchaResults(key, id), interval, retries >); > function requestCaptchaResults(apiKey, requestId) < const url = `http://2captcha.com/res.php?key=$&action=get&id=$&json=1`; return async function() < return new Promise(async function(resolve, reject)< const rawResponse = await request.get(url); const resp = JSON.parse(rawResponse); if (resp.status === 0) return reject(resp.request); resolve(resp.request); >); > > const timeout = millis => new Promise(resolve => setTimeout(resolve, millis))Как только у вас есть данные ответа, вам нужно вставить результат в скрытое текстовое поле g-recaptcha-response в форме регистрации Reddit. Это не так просто, как использование метода .type() библиотеки Puppeteer, так как элемент невидим и не может получить фокус ввода. Можно сделать его видимым и затем использовать .type(), или же использовать JavaScript, чтобы внедрить значение на страницу. Для добавления JavaScript на страницу, при использовании Puppeteer, у нас есть метод .evaluate(), который принимает либо функцию, либо строку (при передаче функции она просто преобразуется в строку с помощью метода .toString()), и запускает ее в контексте страницы.
const response = await pollForRequestResults(apiKey, requestId); const js = `document.getElementById("g-recaptcha-response").innerHTML="$";` await page.evaluate(js);После внедрения этого значения у нас все готово для завершения регистрации. Это действительно так просто.
Полный скрипт доступен ниже, если вам захочется поэкспериментировать с Puppeteer и/или 2Captcha.
Что вы теперь можете сделать?
Этот пост был написан ради двух вещей:
1. Показать вам, насколько капчи нехорошая вещь
2. Показать вам, что капчам нет необходимости блокировать вас
Капчи существуют, как правило, чтобы блокировать нехороших субъектов, манипулирующих контентом в мошеннических или вредоносных целях в ходе спланированных атак, которые выливаются в многомиллионные запросы. Есть много легитимных причин, по которым вам может потребоваться программно управлять сайтом, и если капчи не останавливают плохих парней, то вас-то уж точно они останавливать не должны.