Построение гистограмм в Python
В этой статье описывается построение графиков данных с помощью пакета Python pandas’.hist(). База данных SQL — это источник, используемый для визуализации интервалов данных гистограммы, имеющих последовательные, не перекрывающиеся значения.
Предварительные условия
- SQL Server для Windows или для Linux
- Управляемый экземпляр SQL Azure
- SQL Server Management Studio для восстановления образца базы данных в Управляемый экземпляр SQL Azure.
- Azure Data Studio. Сведения об установке см. в разделе Azure Data Studio.
- Восстановление образца базы данных DW для получения демонстрационных данных, используемых в этой статье.
Проверка восстановленной базы данных
Чтобы убедиться, что восстановленная база данных существует, выполните запрос к таблице Person.CountryRegion.
USE AdventureWorksDW; SELECT * FROM Person.CountryRegion; Установка пакетов Python
Установите следующие пакеты Python.
- pyodbc
- pandas
- sqlalchemy
- matplotlib
Чтобы установить эти пакеты, выполните приведенные ниже действия.
- В записной книжке Azure Data Studio выберите Управление пакетами.
- В области Управление пакетами выберите вкладку Добавить новые.
- Для каждого из следующих пакетов введите имя пакета, нажмите Поиск, а затем — Установить.
Построение гистограммы
Распределенные данные, отображаемые в гистограмме, основаны на SQL-запросе. AdventureWorksDW2022 Гистограмма визуализирует данные и частоту значений данных.
Измените переменные строки подключения: «сервер», «база данных», «имя пользователя» и «пароль», чтобы подключиться к базе данных SQL Server.
Чтобы создать записную книжку:
- В Azure Data Studio выберите пункт Файл и Новая записная книжка.
- В записной книжке выберите ядро Python3 и нажмите + Код.
- Вставьте код в записную книжку и нажмите Запустить все.
import pyodbc import pandas as pd import matplotlib import sqlalchemy from sqlalchemy import create_engine matplotlib.use('TkAgg', force=True) from matplotlib import pyplot as plt # Some other example server values are # server = 'localhost\sqlexpress' # for a named instance # server = 'myserver,port' # to specify an alternate port server = 'servername' database = 'AdventureWorksDW2022' username = 'yourusername' password = 'databasename' url = 'mssql+pyodbc://:@:/?driver=SQL+Server'.format(user=username, passwd=password, host=server, port=port, db=database) engine = create_engine(url) sql = "SELECT DATEDIFF(year, c.BirthDate, GETDATE()) AS Age FROM [dbo].[FactInternetSales] s INNER JOIN dbo.DimCustomer c ON s.CustomerKey = c.CustomerKey" df = pd.read_sql(sql, engine) df.hist(bins=50) plt.show() На экране отображается распределение возрастов клиентов в FactInternetSales таблице.
Как создать гистограмму из Pandas DataFrame
Вы можете использовать следующий базовый синтаксис для создания гистограммы из кадра данных pandas:
df.hist (column='col_name') В следующих примерах показано, как использовать этот синтаксис на практике.
Пример 1. Построение одной гистограммы
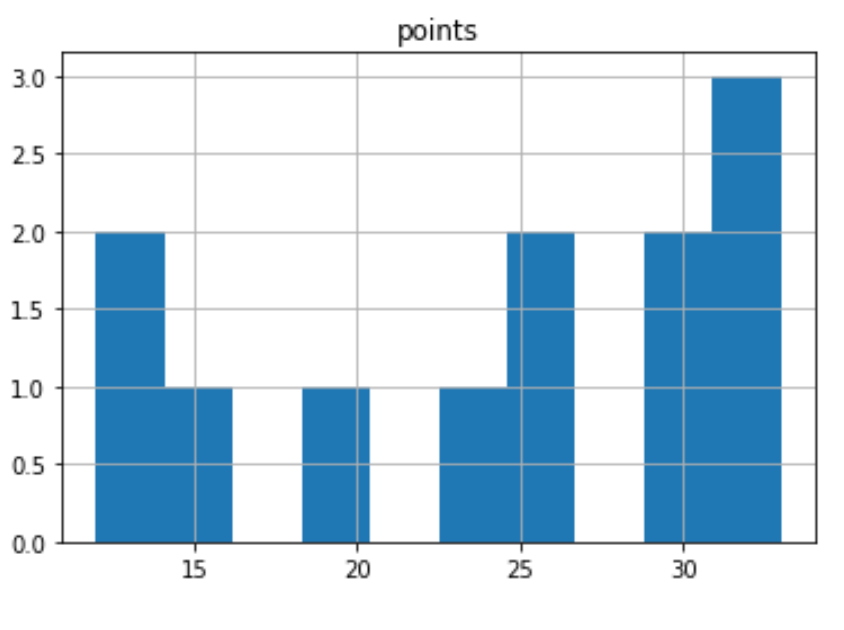
В следующем коде показано, как создать одну гистограмму для определенного столбца в кадре данных pandas:
import pandas as pd #create DataFrame df = pd.DataFrame() #view first five rows of DataFrame df.head () points assists rebounds 0 25 5 11 1 12 7 8 2 15 7 10 3 14 9 6 4 19 12 6 #create histogram for 'points' column df.hist (column='points') 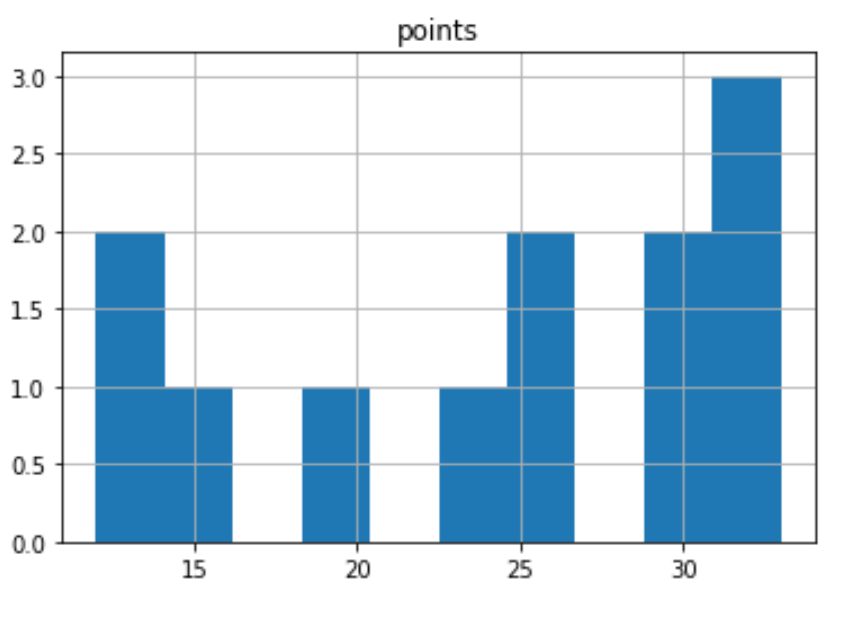
Мы также можем настроить гистограмму с определенными цветами, стилями, метками и количеством ячеек:
#create custom histogram for 'points' column df.hist (column='points', bins= 5 , grid= False , rwidth= .9 , color='purple') 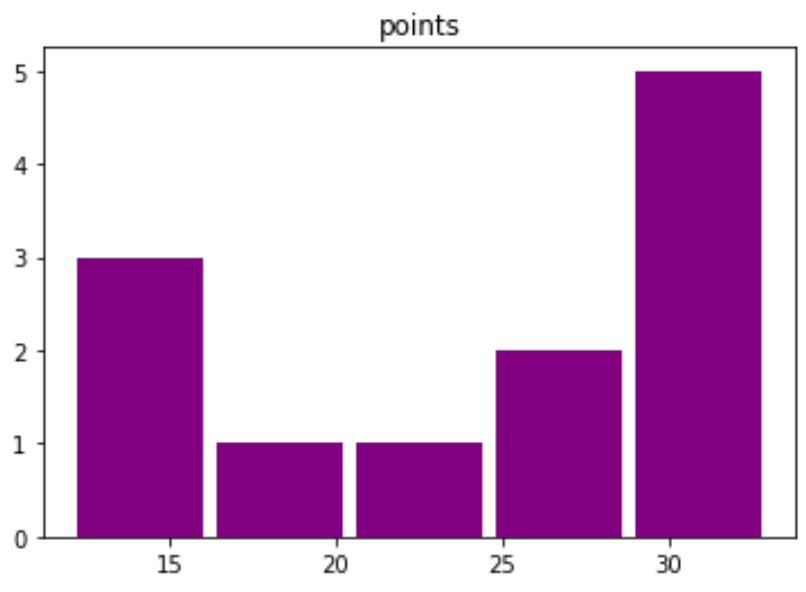
По оси X отображаются очки, набранные каждым игроком, а по оси Y — частота количества игроков, набравших такое количество очков.
Пример 2: построение нескольких гистограмм
В следующем коде показано, как построить несколько гистограмм из кадра данных pandas:
import pandas as pd #create DataFrame df = pd.DataFrame() #view first five rows df.head () team points 0 A 25 1 A 12 2 A 15 3 A 14 4 A 19 #create histogram for each team df.hist (column='points', by='team', bins= 3 , grid= False , rwidth= .9 , color='purple', sharex= True ) 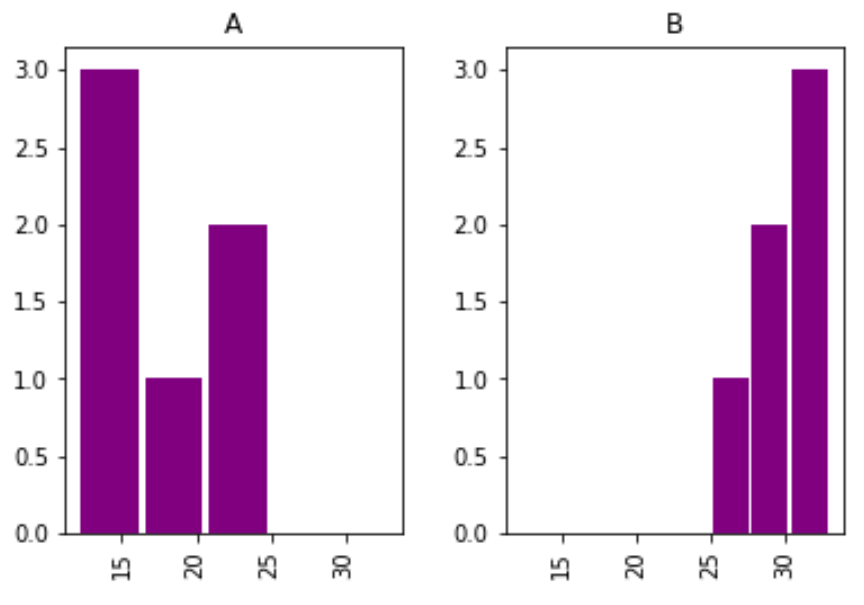
Обратите внимание, что аргумент sharex указывает, что две гистограммы должны иметь одну и ту же ось X.
Это упрощает сравнение распределения значений между двумя гистограммами.
Дополнительные ресурсы
В следующих руководствах объясняется, как создавать другие распространенные графики в Python:
Как построить гистограмму в python



Скачай курс
в приложении
Перейти в приложение
Открыть мобильную версию сайта
© 2013 — 2023. Stepik
Наши условия использования и конфиденциальности
![]()
Public user contributions licensed under cc-wiki license with attribution required
Рисуем гистограммы, столбчатые и круговые диаграммы
На этом занятии мы продолжим знакомство с разными типами двумерных графиков и увидим, как можно строить столбчатые и круговые диаграммы.
Гистограмма и столбчатые диаграммы
Иногда данные требуется сгруппировать по определенным диапазонам и подсчитать сколько значений попадает в тот или иной интервал. Для выполнения такой задачи хорошо подходят столбчатые диаграммы и довольно известный их вид – это гистограмма распределения случайной величины.
Давайте сгенерируем вектор из 500 случайных величин и выведем их в виде гистограммы, используя функцию hist():
import numpy as np import matplotlib.pyplot as plt fig = plt.figure(figsize=(6, 4)) ax = fig.add_subplot() y = np.random.normal(0, 2, 500) ax.hist(y) ax.grid() plt.show()
На выходе получим следующее изображение распределения нормальной СВ:
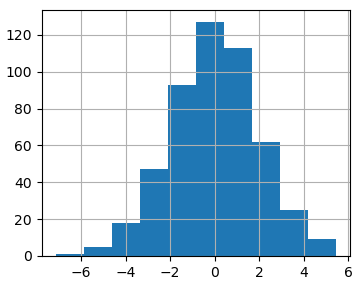
Фактически, мы здесь имеем набор столбиков, высота которых определяется числом СВ, попавших в тот или иной диапазон. Причем, по умолчанию функция hist() разбивает весь интервал на равных 10 диапазонов. Если требуется изменить это число, то мы можем его указать вторым параметром:
ax.hist(y, 50)
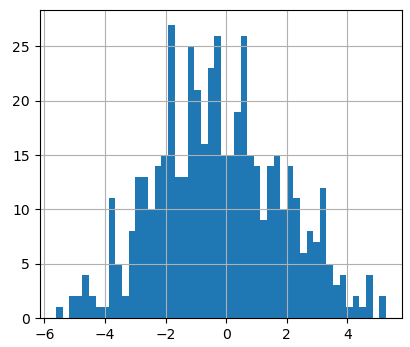
Прежний интервал теперь разбит на 50 диапазонов, столбиков стало больше и они выглядят тоньше.
Функции bar() и barh()
Похожий график можно сформировать и с помощью функции bar. Ей на вход, в самом простом варианте, нужно передать список отметок для столбцов x и значения высот каждого столбца y:
x = [f'H' for i in range(10)] y = np.random.randint(1, 5, len(x)) ax.bar(x, y)
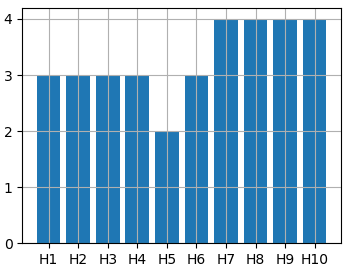
Или, можно отобразить то же распределение нормальной СВ с помощью такой столбчатой диаграммы. Сначала сформируем сами величины и разобьем весь интервал на 10 равных диапазонов:
y = np.random.normal(0, 2, 500) x = np.linspace(np.min(y), np.max(y), 10)
Затем, подсчитаем, сколько величин попало в соответствующий диапазон и выведем список bars с помощью функции bar():
bars = [len(y[np.bitwise_and(y >= x[i], y x[i+1])]) for i in range(len(x)-1)] ax.bar(range(len(x)-1), bars)
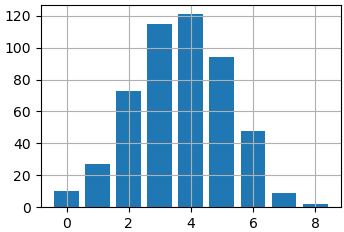
Как видите, у нас получилось изображение аналогичное гистограмме. Только пришлось предварительно подготовить данные, что не очень удобно. Поэтому, когда нужно вывести распределение величин по диапазонам, то проще использовать функцию hist().
Если нам нужно отображать столбики относительно оси ординат, то для этого существует функция barh(), которая работает аналогично функции bar():
ax.barh(range(len(x)-1), bars)
В итоге, график будет выглядеть, следующим образом:
Функции bar() и barh() содержат ряд полезных параметров: