Рубрика «Ликбез» — Как правильно искать информацию в интернете?

С каждым годом увеличиваются объемы информации во всемирной паутине, в соцсетях. И поисковые системы (например, Яндекс и Google) также постоянно совершенствуют алгоритмы своей работы для удобства поиска необходимых материалов.
Чтобы сэкономить время и быстро найти нужные сведения предлагаем воспользоваться нашими рекомендациями:
пишите запрос четко, кратко, только по ключевым словам, опускайте лишнее, к примеру, не надо писать «что делать, если сломался телефон», можно просто «сломался телефон»;
меняйте формулировку запроса, используйте синонимы, если в результатах выдачи нет необходимой информации;
задействуйте несколько поисковиков, результаты выдачи отличаются, так как в этих сервисах по-разному индексируются страницы сайтов;
просматривайте 1‒2 страницы, а не только первые строки из списка результатов;
применяйте «расширенный поиск», «инструменты», они помогают отфильтровать поисковую выдачу по времени публикации, региону и т.д.
используйте функцию «поиск по странице». Зайдите на нужный сайт и с помощью горячих клавиш Ctrl+F или F3 вызовите «окно», где вы вводите ключевое слово и быстро находите требуемые сведения;
ищите данные с помощью языка запросов ‒ операторов, например:
если нужно найти цитату, используйте кавычки « »;
если помните только часть фразы, то поставьте знак звездочки «*»;
если какое-то слово обязательно должно быть на искомой странице поставьте знак плюс «➕»;
если нужно исключить из поиска определенные слова, то ставим знак минус «➖»;
если нужно зафиксировать форму слова, используйте восклицательный знак «!».
Есть также и другие поисковые операторы для уточнения запроса.
Свежие записи
- 17 января в МАУ «ИРСИ» состоялось первое занятие третьего потока потока «Школы городского садовода» 18.01.2024
- Рубрика «Ликбез» – Как развить умственную выносливость? 15.01.2024
- Рубрика «Из жизни русского языка» – Где-то там, когда-либо, как-нибудь … 12.01.2024
- 15 января состоится занятие (первое в 2024 году) в рамках проекта – победителя «Школа ответственного собаковода» 12.01.2024
- 9 января в МАУ «ИРСИ» состоялось четвертое занятие второго потока «Школы городского садовода». 10.01.2024
Как правильно искать в поисковиках Яндекс и Гугл
Сегодня речь пойдет об операторах, которыми люди пользуются, чтобы облегчить поиски, уточнить, найти информацию. Это специальные символы, с помощью которых можно допустить в выдачу новости только за последний год, запросить данные в формате PDF. Пользуясь ими, можно значительно упростить себе жизнь, сократить время, потраченное впустую. Профессионально ими пользуются интернет-маркетологи, специалисты и вебмастера. Список насчитывает сотни команд, которые сложно запомнить. Мы выделили только 48, которые действительно полезны не только в программировании, но и в обычной жизни.
Общие
Они распознаются обоими поисковиками – и Яндекс, и Google. Отличие заключается лишь в том, что первая строго выполняет поставленную перед ней задачу, а вторая может выдавать и другие итоги, если считает их более целесообразными. «Плюс» «+» вводится в строке, чтобы указать на слово, которое должно быть в выдаче. Обычно его ставят перед предлогом, т.к. поисковик его не учитывает. С другой стороны, можно указать на конкретно интересующий пользователя параметр. 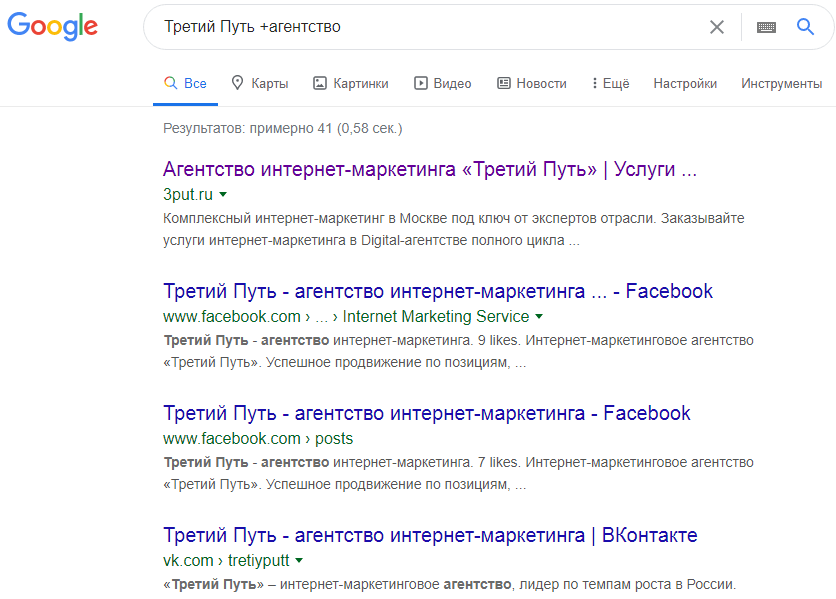 Здесь мы показываем, что нас интересует не философская теория, а конкретное агентство. «Минус» «-» играет противоположную роль. Он исключает обороты, что делает выдачу более чистой. Например, это удобно при поиске информации о фильме. Чтобы боты не предлагали вам его смотреть или скачивать, простой задайте им соответствующую команду.
Здесь мы показываем, что нас интересует не философская теория, а конкретное агентство. «Минус» «-» играет противоположную роль. Он исключает обороты, что делает выдачу более чистой. Например, это удобно при поиске информации о фильме. Чтобы боты не предлагали вам его смотреть или скачивать, простой задайте им соответствующую команду. 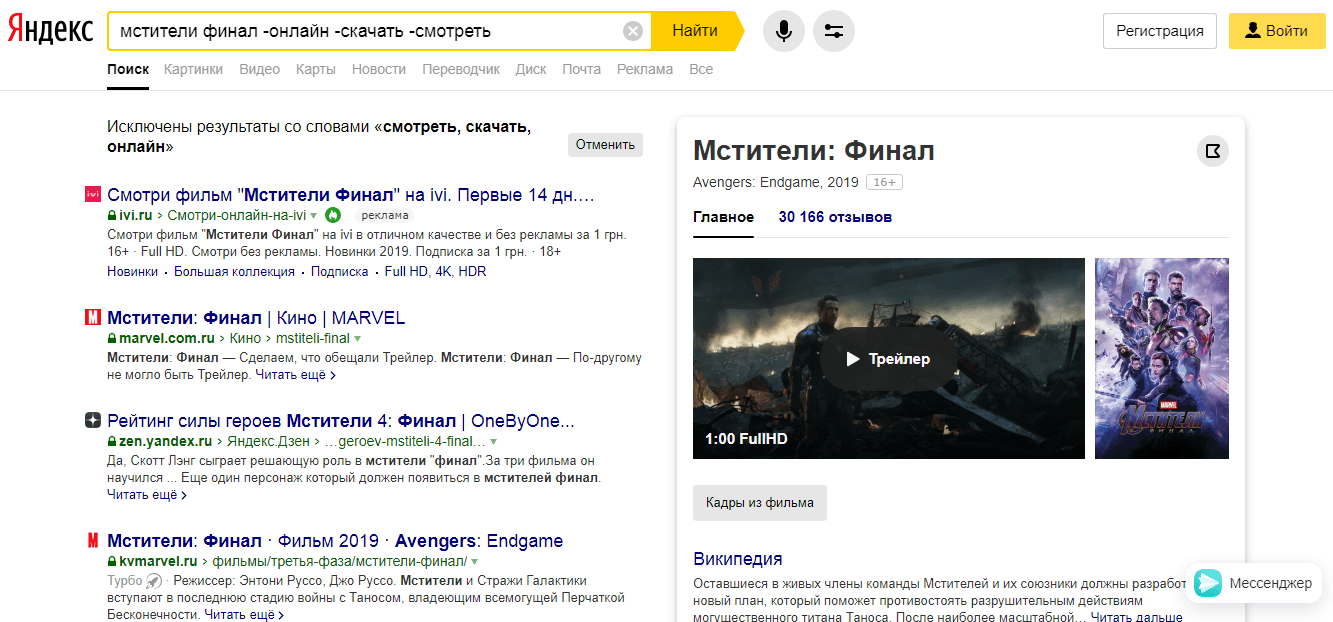 «Кавычки» Они указывают на вхождение всего изречения, которое находится внутри них.
«Кавычки» Они указывают на вхождение всего изречения, которое находится внутри них. 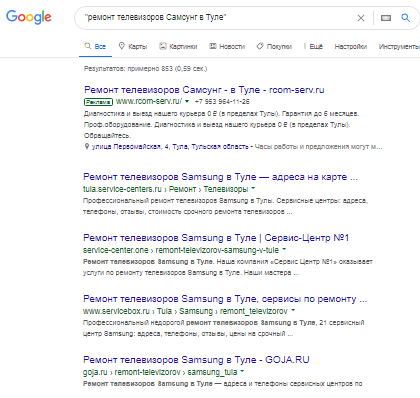 «Звездочка» Способна заменить сразу несколько слов. Она может стоять самостоятельно или в сочетании с кавычками, дает возможность найти цитату или название, если вы не помните их точно и полностью.
«Звездочка» Способна заменить сразу несколько слов. Она может стоять самостоятельно или в сочетании с кавычками, дает возможность найти цитату или название, если вы не помните их точно и полностью. 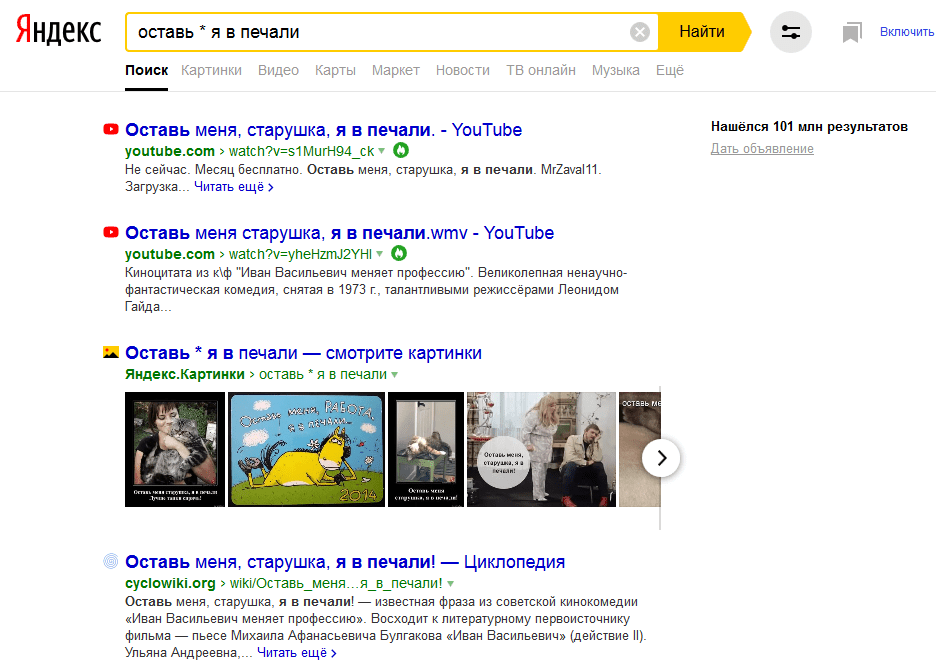 «Вертикальный делитель» Спецсимвол «|» – аналог «или». Поэтому вам выдадут сразу оба результата.
«Вертикальный делитель» Спецсимвол «|» – аналог «или». Поэтому вам выдадут сразу оба результата. 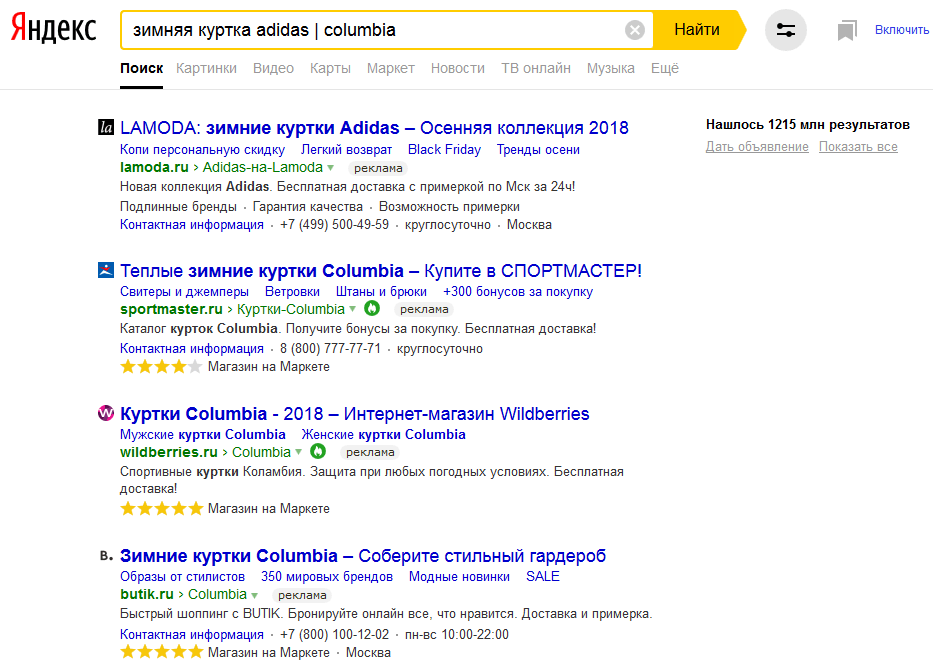 «Тильда» «~» в Яндексе обозначает, что требуется разделить слова на разные предложения. На практике он работает так же, как и «-».
«Тильда» «~» в Яндексе обозначает, что требуется разделить слова на разные предложения. На практике он работает так же, как и «-». 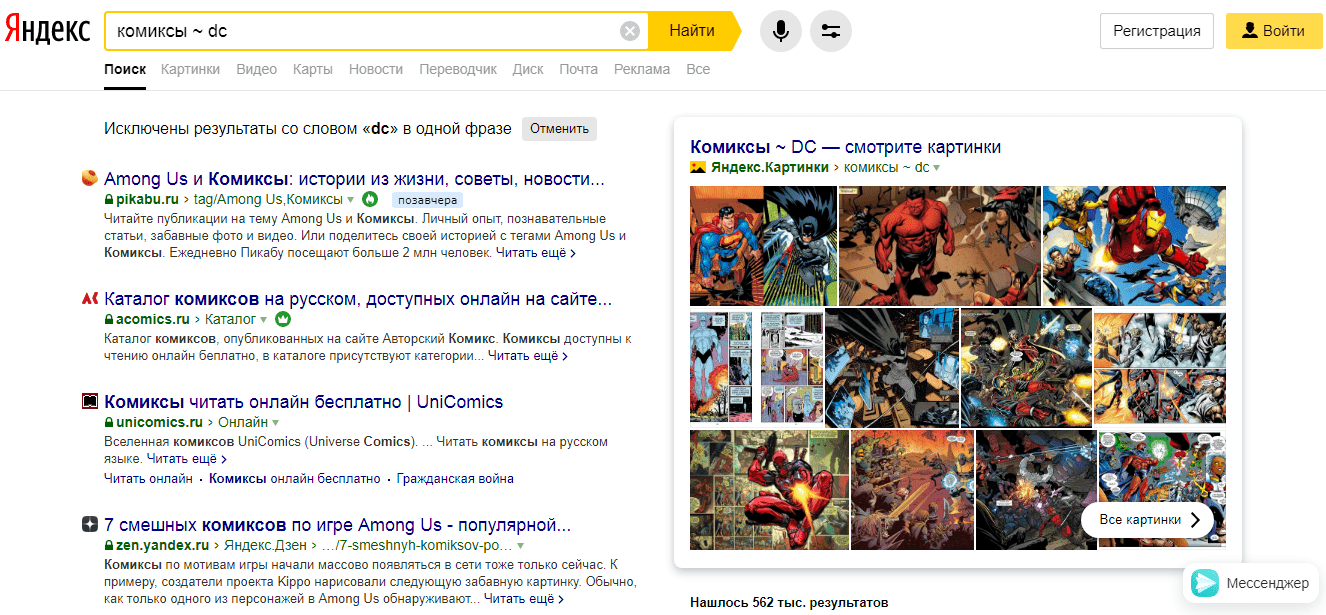 В Гугл ситуация немного другая, здесь эти символы не взаимозаменяемы. Тильда выделяет синонимы, которые можно включить в выдачу. Для примера приведена «еда», синонимы к которой интересуют пользователя, а сам термин – нет.
В Гугл ситуация немного другая, здесь эти символы не взаимозаменяемы. Тильда выделяет синонимы, которые можно включить в выдачу. Для примера приведена «еда», синонимы к которой интересуют пользователя, а сам термин – нет. 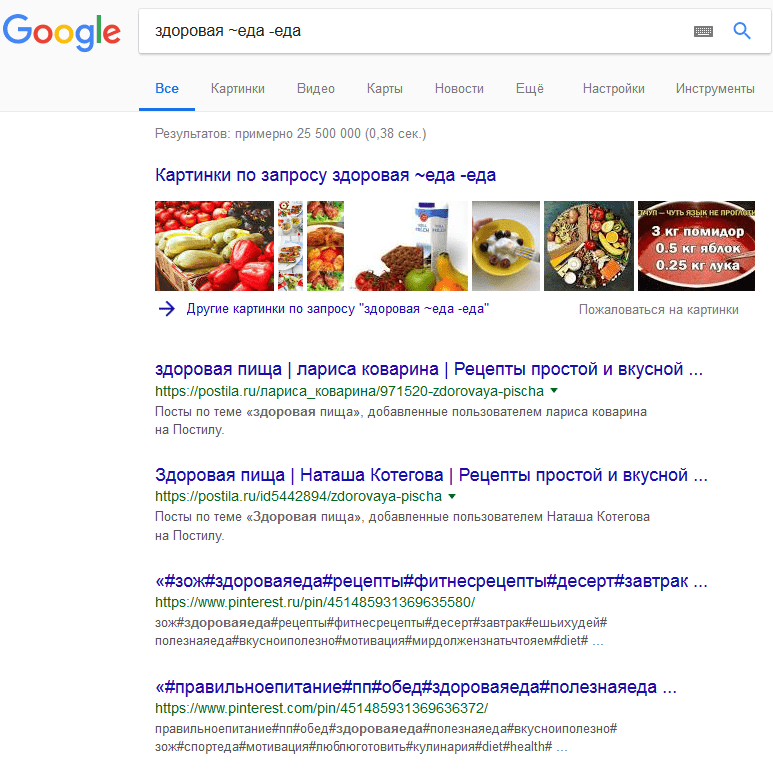
Операторы Яндекса
Все они условно разделены на три группы – документные, недокументированные, логические.
Документные
Они подходят для расширенного розыска, это уточняющие спецсимволы, популярные среди сеошников. Они указывают на конкретный тип документа, адрес и пр. В большинстве своем они и так включены в поисковик, но для уверенности можете вводить их отдельно. «title» Выбирает странички, в тайтле которых есть заданное выражение. Для фразы ставятся скобки, а для одного названия специального обозначения не требуется. Чтобы вы сразу могли видеть, в каком контексте употреблено это словосочетание, оно выделяется жирным синим цветом. 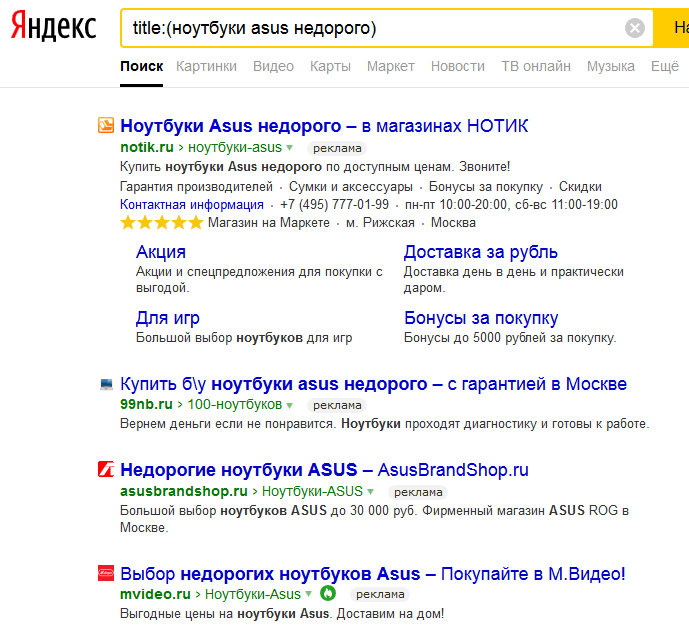 «mime» Выделяет искомый формат файла. Например, PDF.
«mime» Выделяет искомый формат файла. Например, PDF. 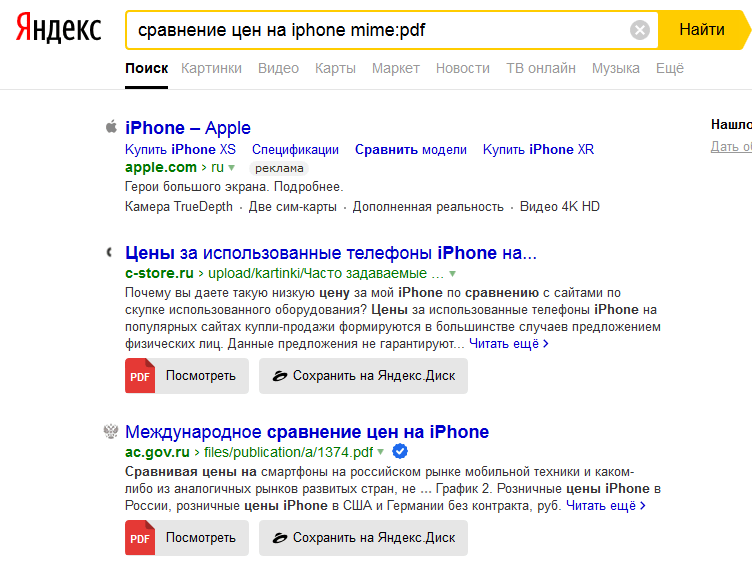 «host» Показывает, на каком хостинге мониторить документы.
«host» Показывает, на каком хостинге мониторить документы. 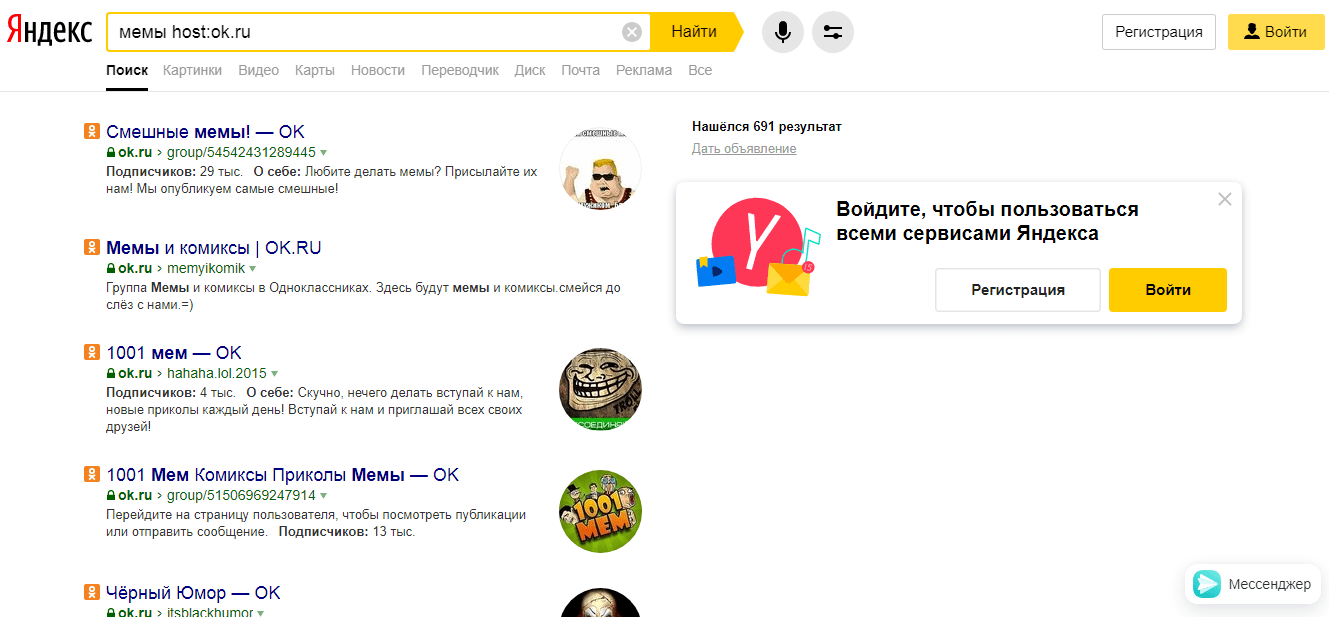 «domain» Он позволяет искать только на определенном домене.
«domain» Он позволяет искать только на определенном домене. 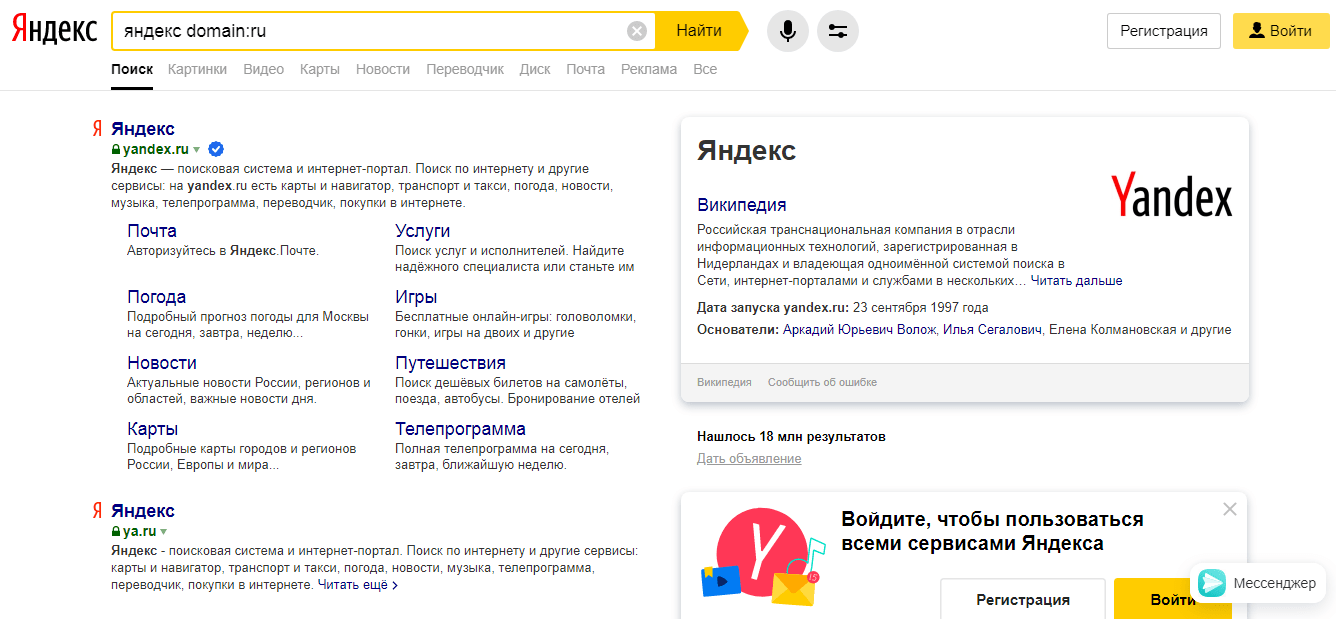 «site» Ограничивает поисковых ботов одним сайтом, но позволяет разыскивать словосочетание на всех страницах.
«site» Ограничивает поисковых ботов одним сайтом, но позволяет разыскивать словосочетание на всех страницах. 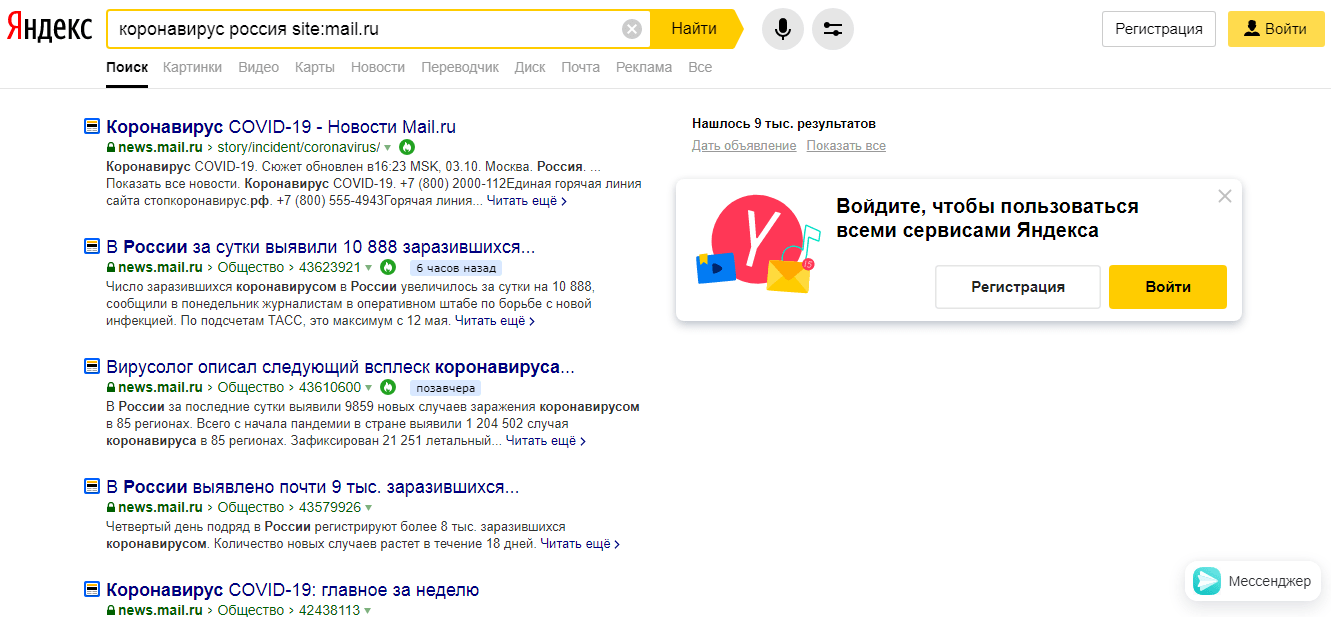 «date» Можно указать период публикации. Здесь звездочка служит в качестве замены любого числа ноября. Указывается дата в обратном порядке.
«date» Можно указать период публикации. Здесь звездочка служит в качестве замены любого числа ноября. Указывается дата в обратном порядке. 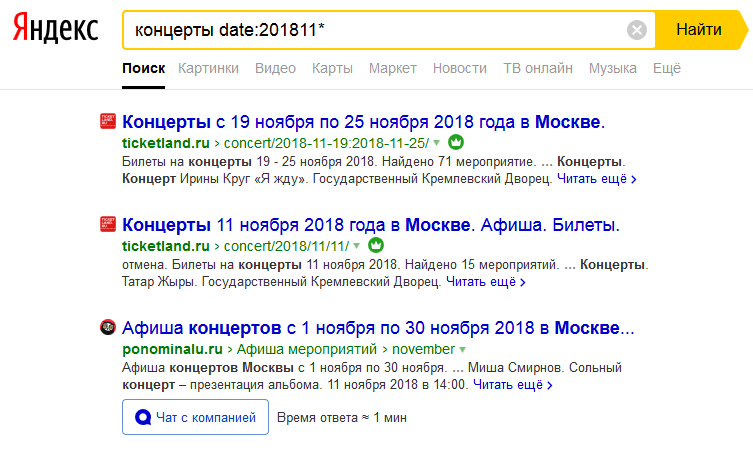 «lang» Отбирает порталы только с заданным вами языком, независимо от языка, на котором написана реплика.
«lang» Отбирает порталы только с заданным вами языком, независимо от языка, на котором написана реплика. 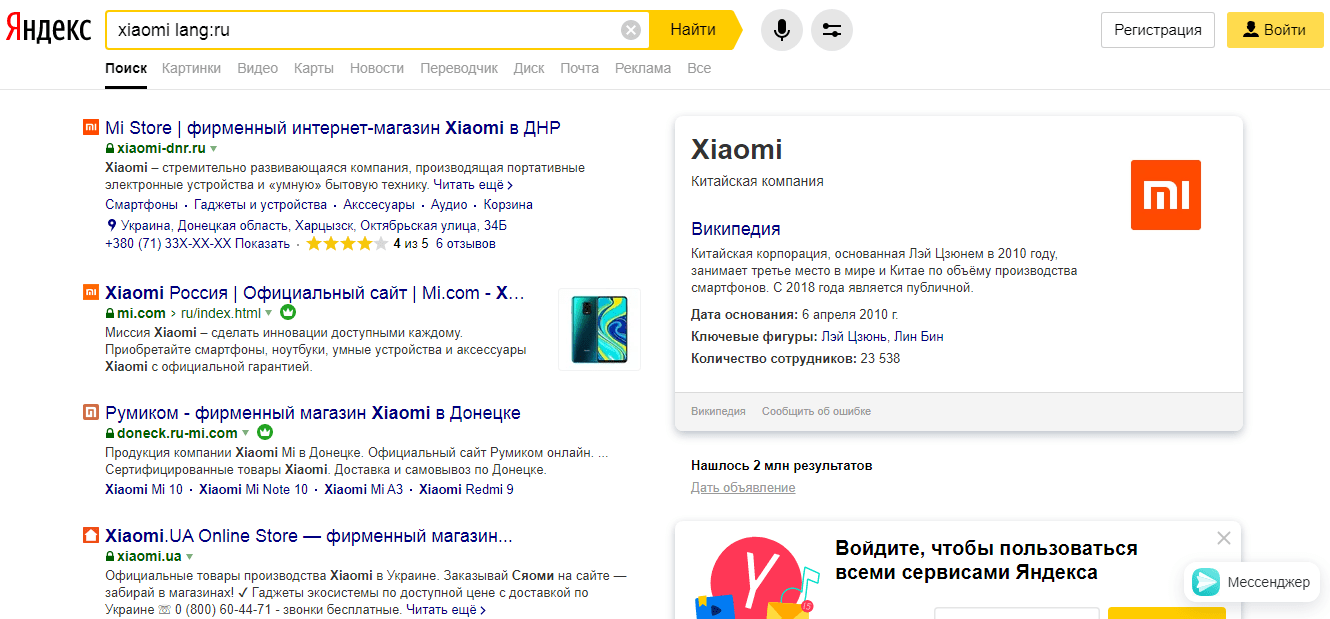 «url» Этот оператор полезен при контроле индексации. Например, задаем url:fb.ru/hi-tech .
«url» Этот оператор полезен при контроле индексации. Например, задаем url:fb.ru/hi-tech . 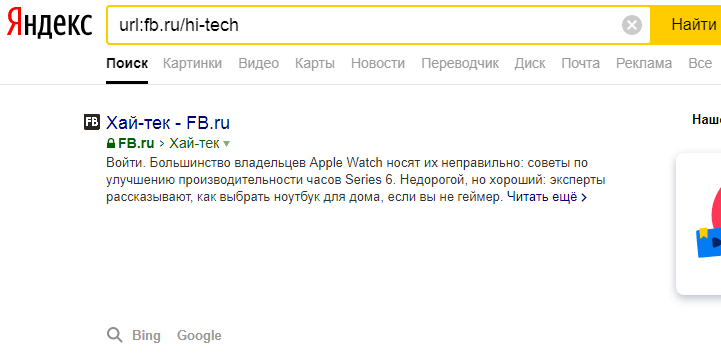 «inurl» Используя тот же hi-tech, можно отделить сайты, на которых он содержится.
«inurl» Используя тот же hi-tech, можно отделить сайты, на которых он содержится. 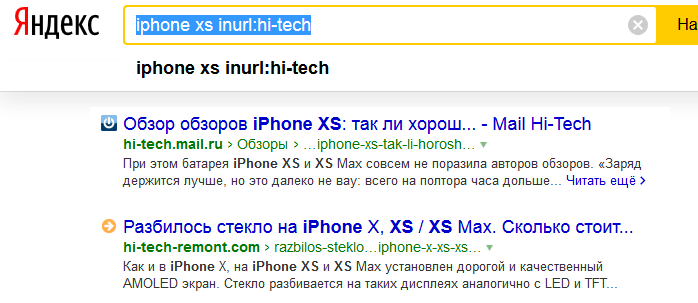
Недокументированные
«intext» Здесь будут новости про сисадминистрирование, программирование и т.д., если ввести «IT intext:новости». 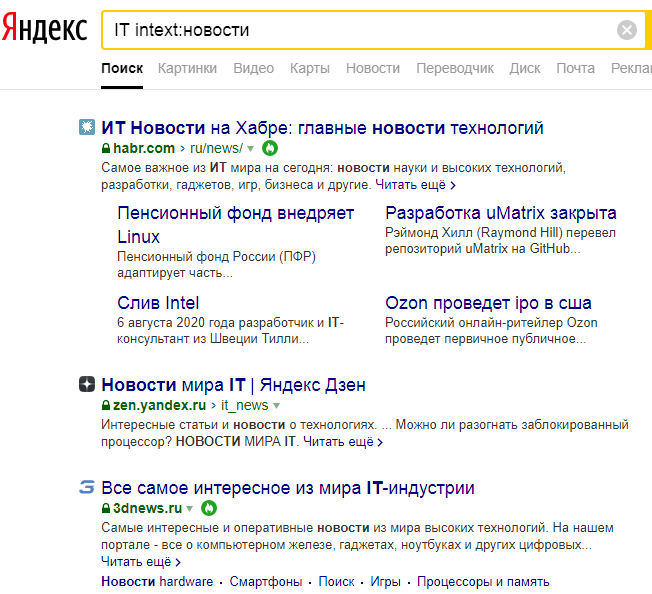 «image» Он подходит для нахождения картинок.
«image» Он подходит для нахождения картинок. 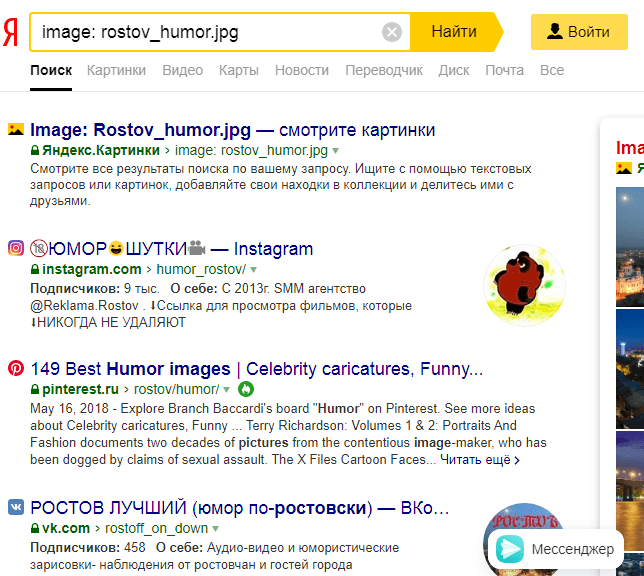 «anchormus» Выбирает страницы, на которых есть анкорные ссылки на музыку с таким же названием.
«anchormus» Выбирает страницы, на которых есть анкорные ссылки на музыку с таким же названием. 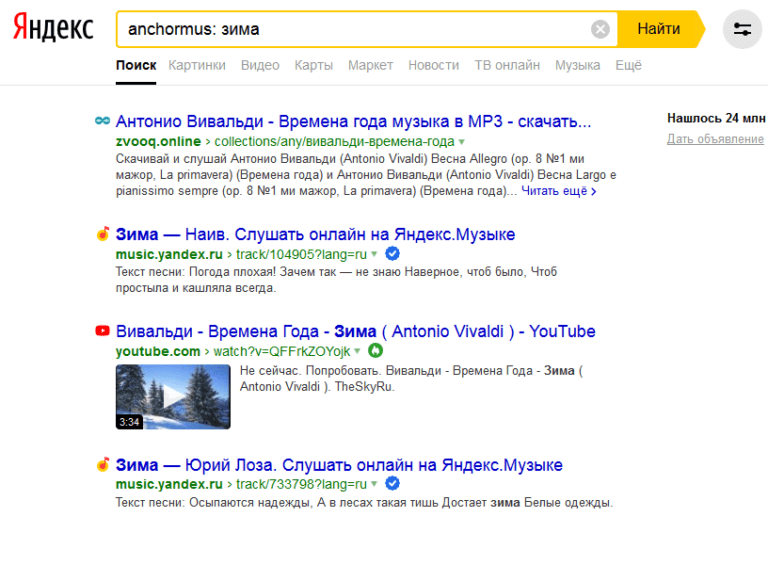
Логические
«!» Учитывается регистр и падеж, ищется строго заданная формулировка. 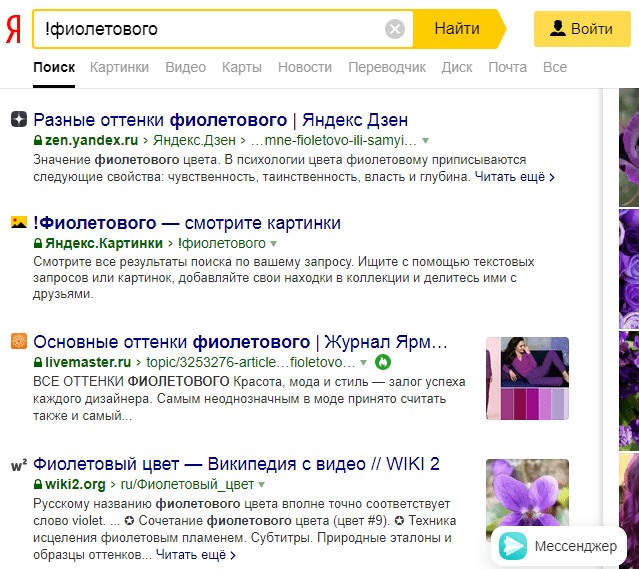 «!!» Позволяет найти страницы, на которых заданный оборот присутствует в любом падеже и форме.
«!!» Позволяет найти страницы, на которых заданный оборот присутствует в любом падеже и форме. 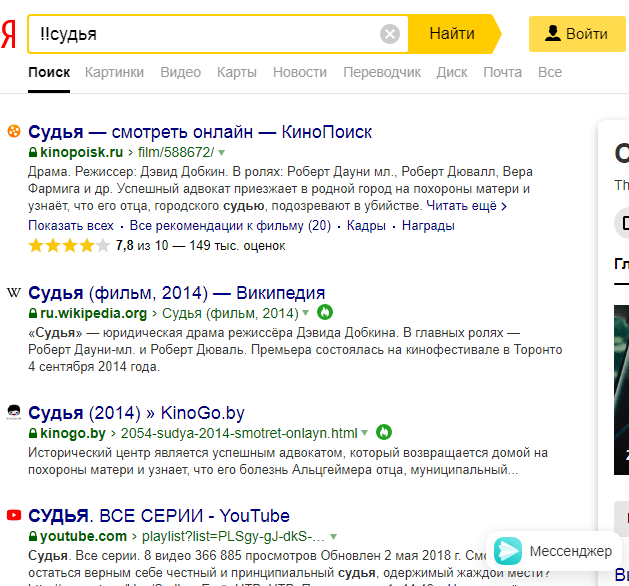 «&» Связывает высказывание в одно предложение.
«&» Связывает высказывание в одно предложение. 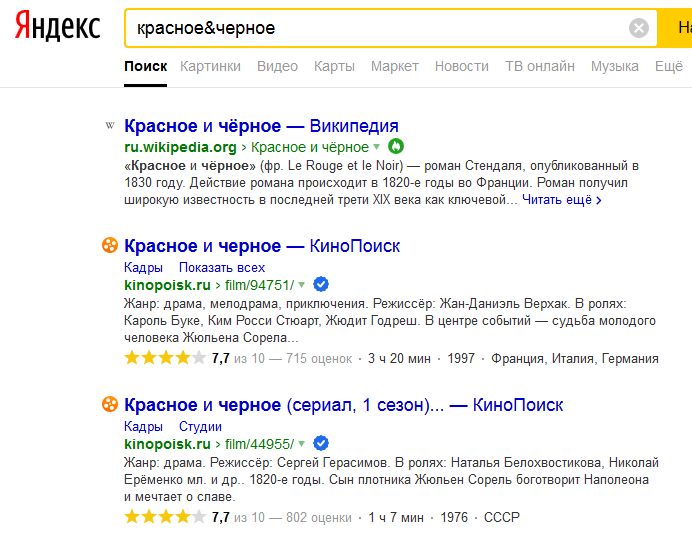 «&&» Находит компоненты в одном документе.
«&&» Находит компоненты в одном документе. 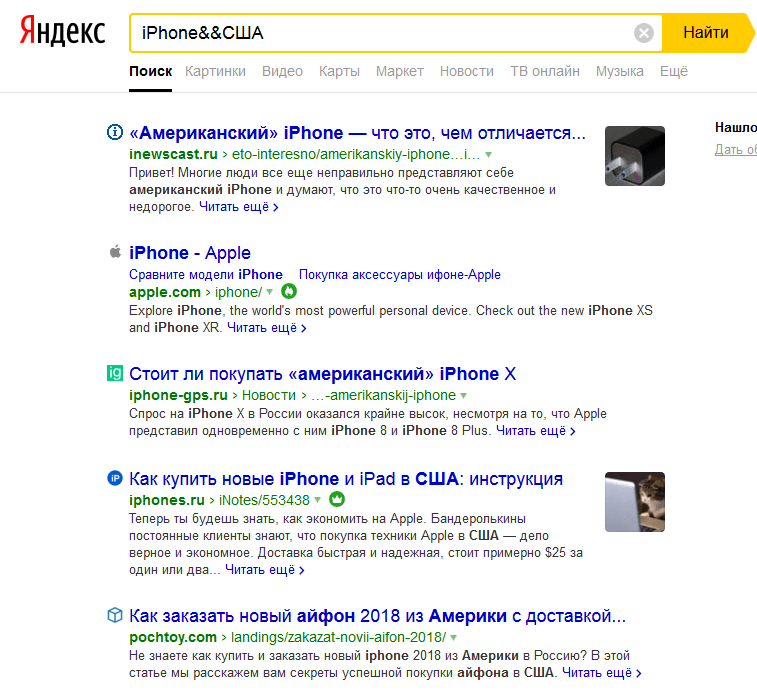 « Здесь покажутся ссылки, соответствующие вопросу юзера, которые подходят по формулировке до знаков. При этом остальные будут обязательно на открывшейся странице.
« Здесь покажутся ссылки, соответствующие вопросу юзера, которые подходят по формулировке до знаков. При этом остальные будут обязательно на открывшейся странице. 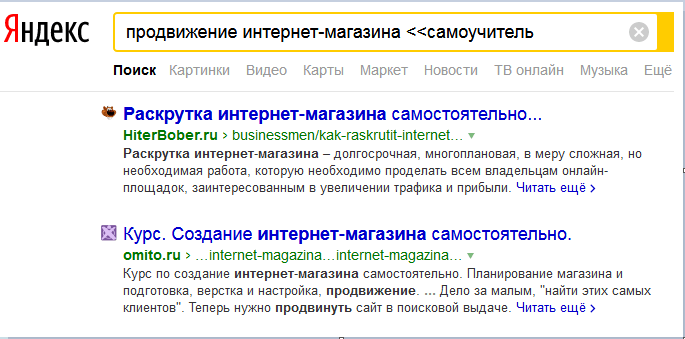 «/n» N – это количество слов, в пределах которых должно быть расположены все части фразы.
«/n» N – это количество слов, в пределах которых должно быть расположены все части фразы. 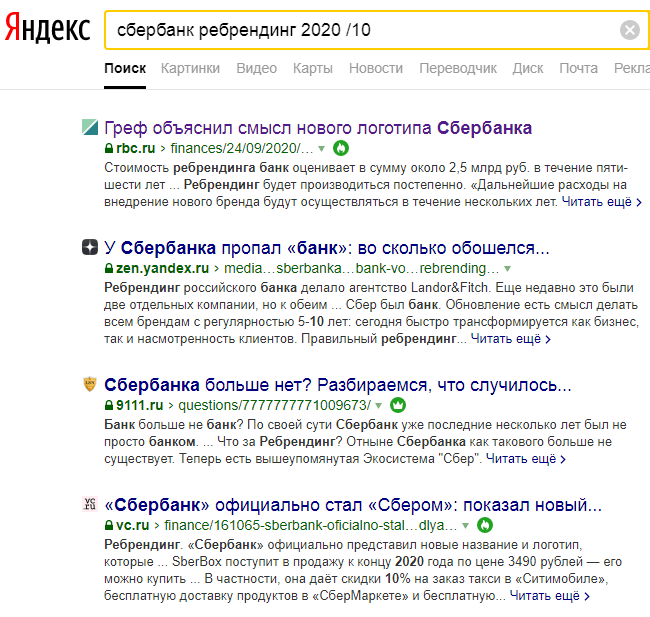 «/(m n)» Здесь можно задать рамки, а не максимальное значение, как в предыдущем случае.
«/(m n)» Здесь можно задать рамки, а не максимальное значение, как в предыдущем случае. 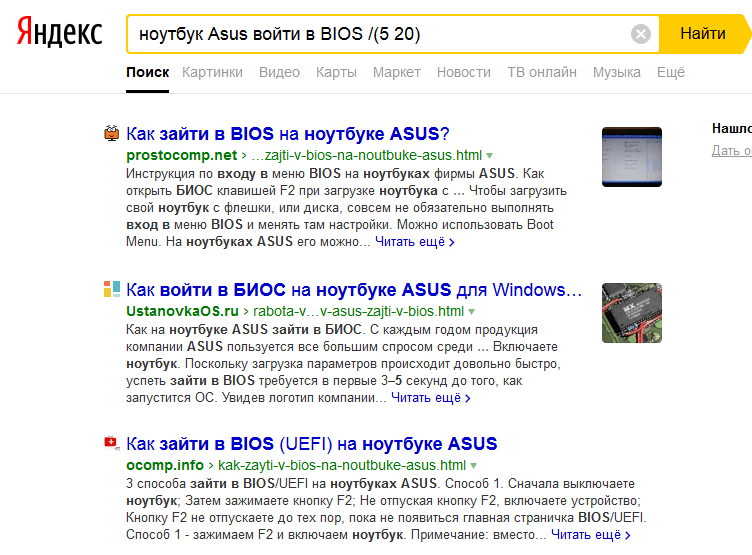 «&& /n« Это касается предложений, цифра показывает их количество.
«&& /n« Это касается предложений, цифра показывает их количество. 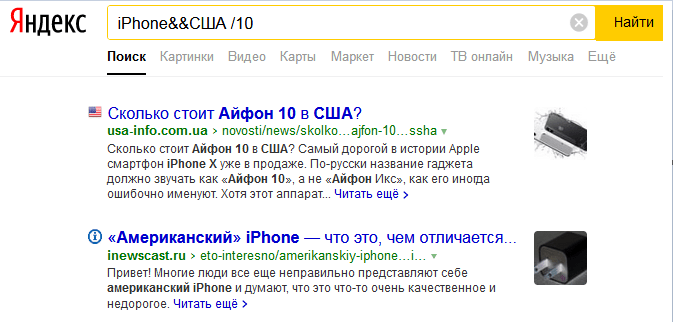 «( )» Круглые скобки группируют сложные фразы, ограничивают и выделяют другие спецсимволы.
«( )» Круглые скобки группируют сложные фразы, ограничивают и выделяют другие спецсимволы. 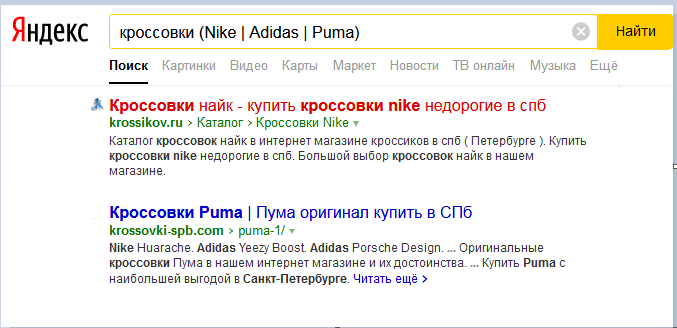
Операторы Google
Документные
«site» Показывает, где искать – сайт или домен. Используется вебмастерами, помогает сделать перелинковку. 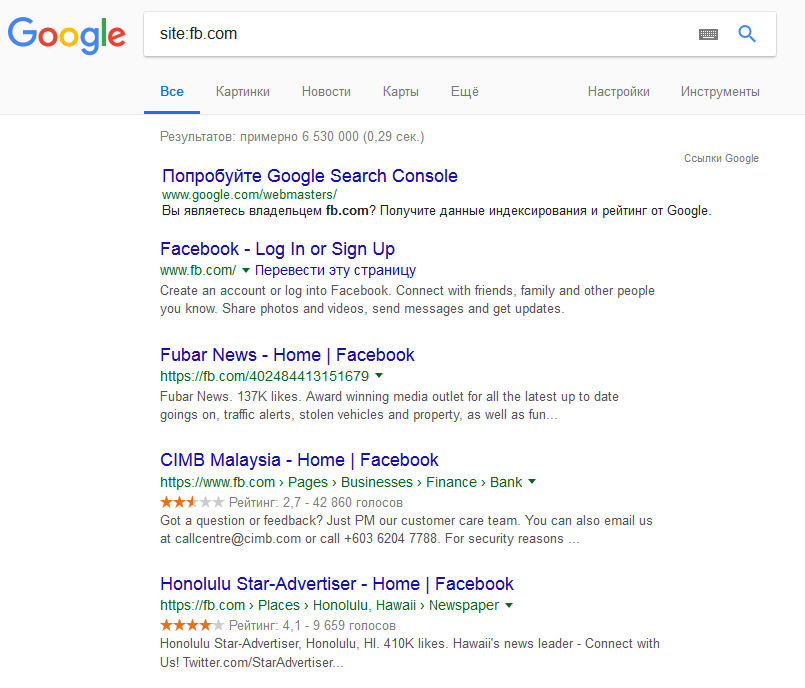 «link» Можно посмотреть, кто ссылается на вас или искомый портал в других пабликах.
«link» Можно посмотреть, кто ссылается на вас или искомый портал в других пабликах. 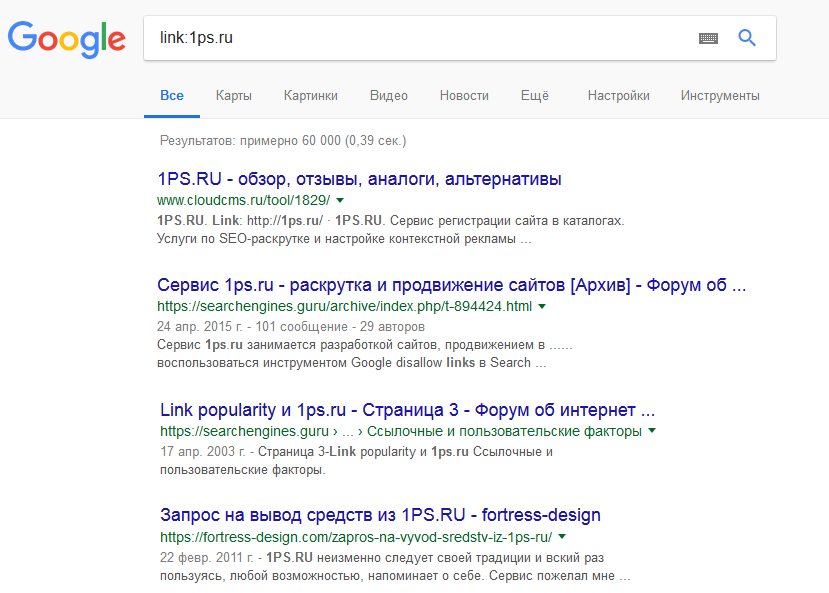 «related» Особенно востребован в узкоспециализированных тематиках, т.к. позволяет отыскать схожие темы и содержание. Он же поможет определить конкурентов.
«related» Особенно востребован в узкоспециализированных тематиках, т.к. позволяет отыскать схожие темы и содержание. Он же поможет определить конкурентов. 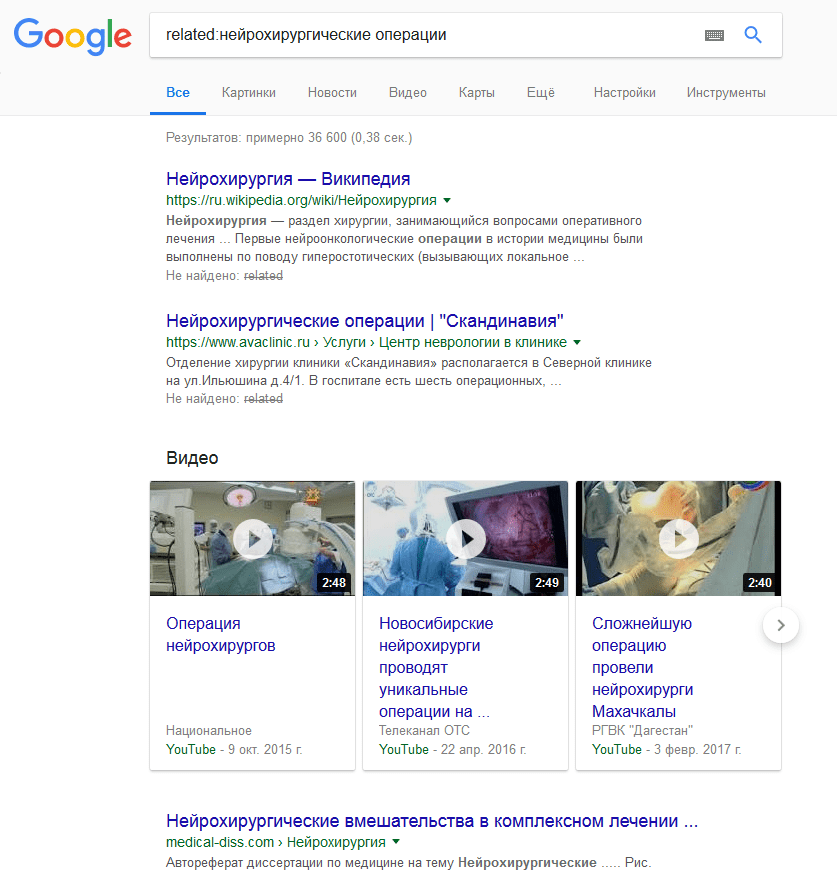 «file» Отделяет только заданный формат документа.
«file» Отделяет только заданный формат документа. 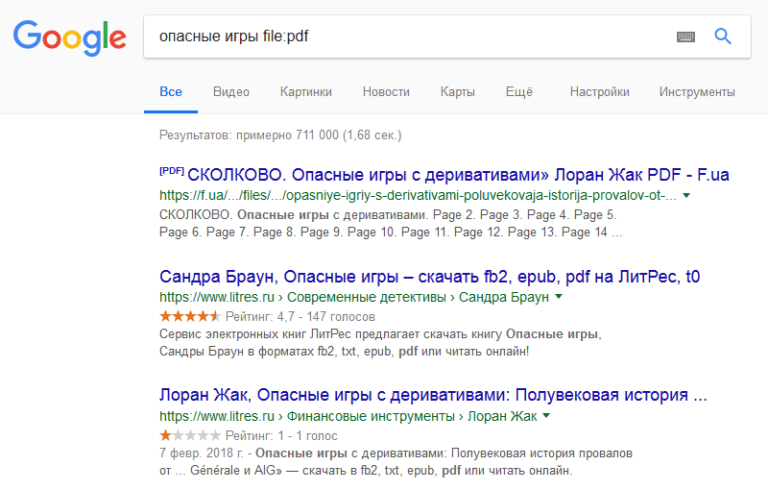 «define» Применяется, если требуется узнать значение выражения или термина. В итогах чаще всего выдаются словари или Википедия.
«define» Применяется, если требуется узнать значение выражения или термина. В итогах чаще всего выдаются словари или Википедия. 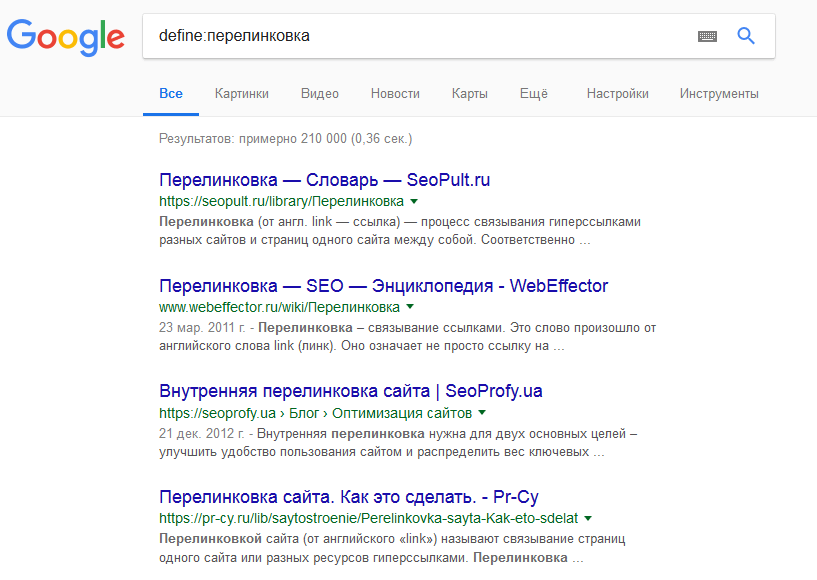 «loc» Отделяет местоположение, применяется для уточнения локации.
«loc» Отделяет местоположение, применяется для уточнения локации. 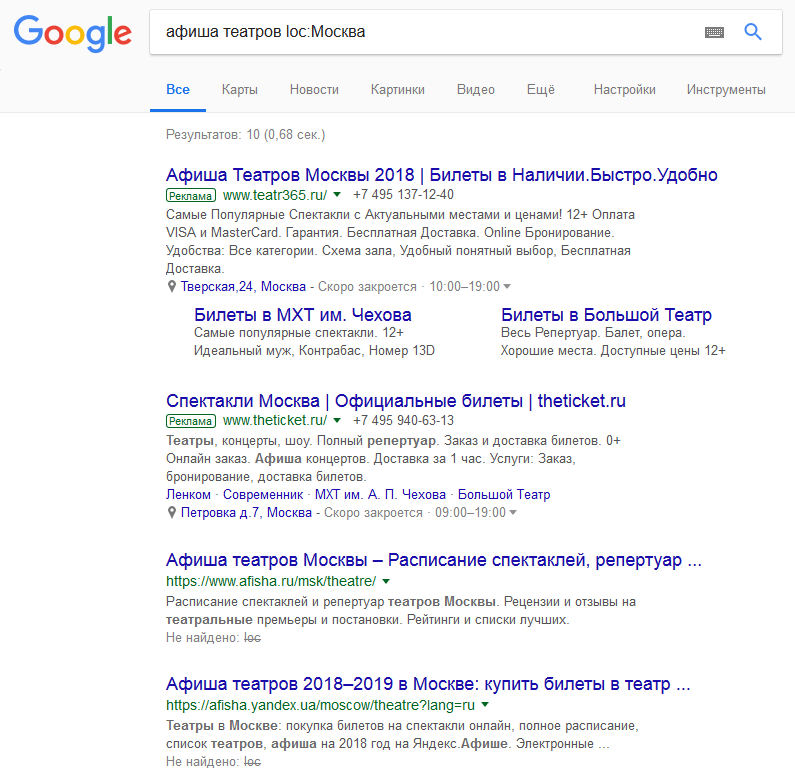 «date« Выбирает публикации с размещением указанное количество месяцев назад.
«date« Выбирает публикации с размещением указанное количество месяцев назад. 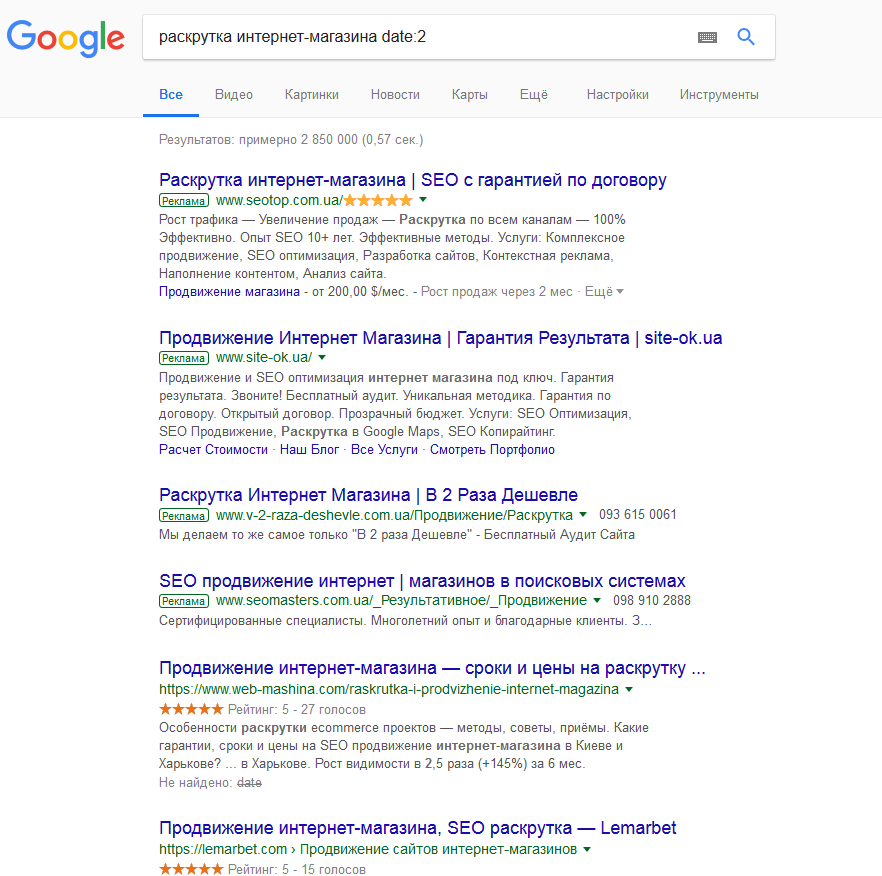 «source« Применяется в Google News. Он сужает поиск, учитывая выбранный источник, например, новостное издание.
«source« Применяется в Google News. Он сужает поиск, учитывая выбранный источник, например, новостное издание. 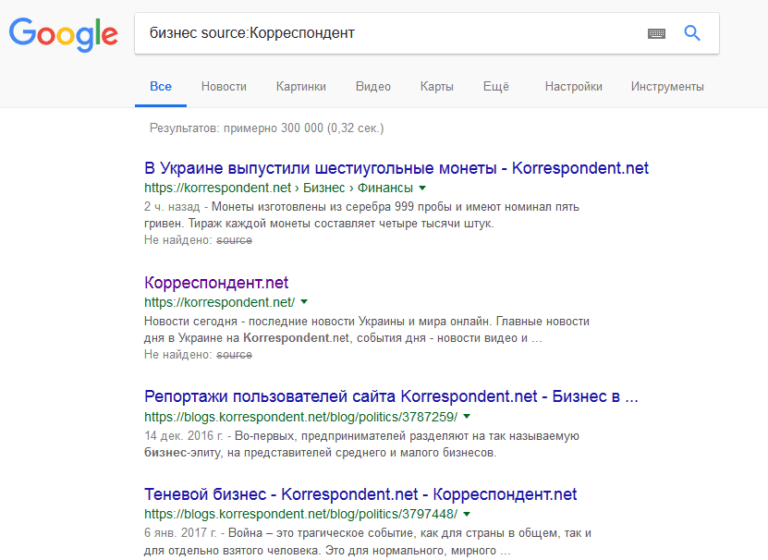 «allinurl« Введенный в поисковую строку текст будет разыскиваться в URL-адресах. Самый эффективный способ – написание на английском или латинице.
«allinurl« Введенный в поисковую строку текст будет разыскиваться в URL-адресах. Самый эффективный способ – написание на английском или латинице. 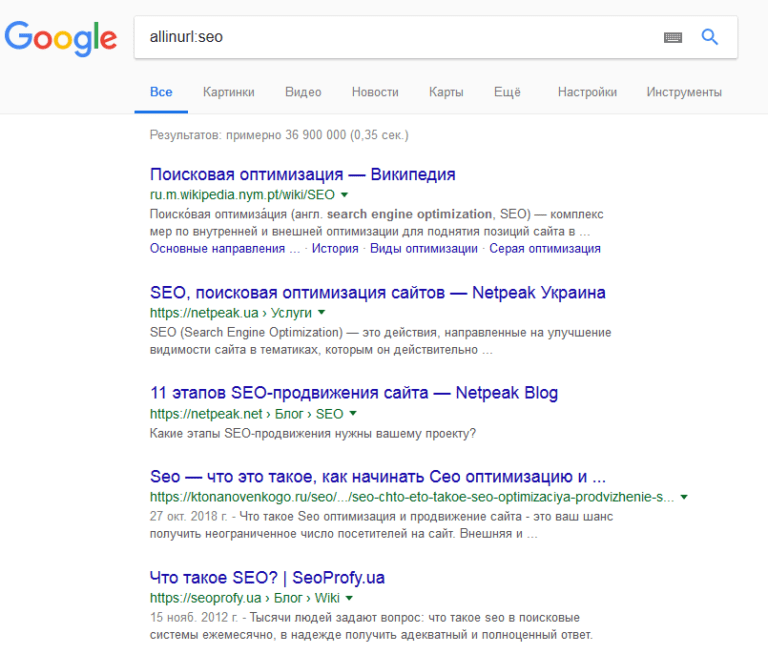 «inurl« Здесь речь идет об одном термине, указанном сразу после двоеточия.
«inurl« Здесь речь идет об одном термине, указанном сразу после двоеточия. 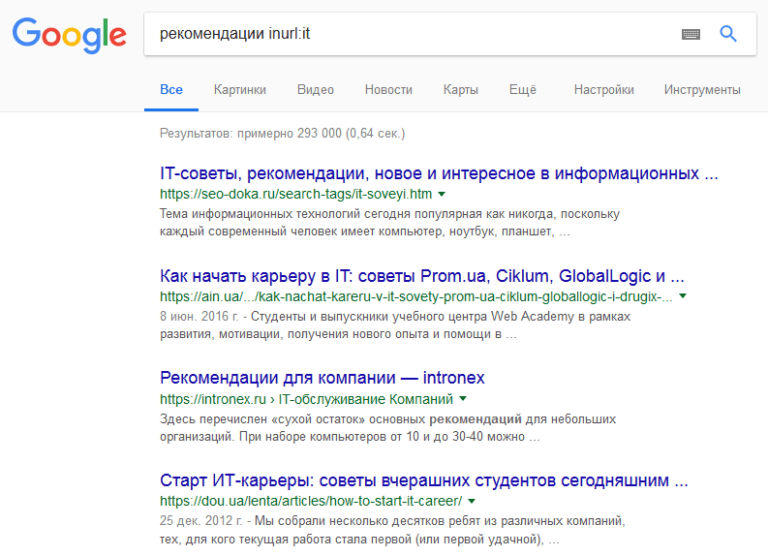 «allintext« Весь запрос обязательно должен присутствовать на найденной страничке.
«allintext« Весь запрос обязательно должен присутствовать на найденной страничке. 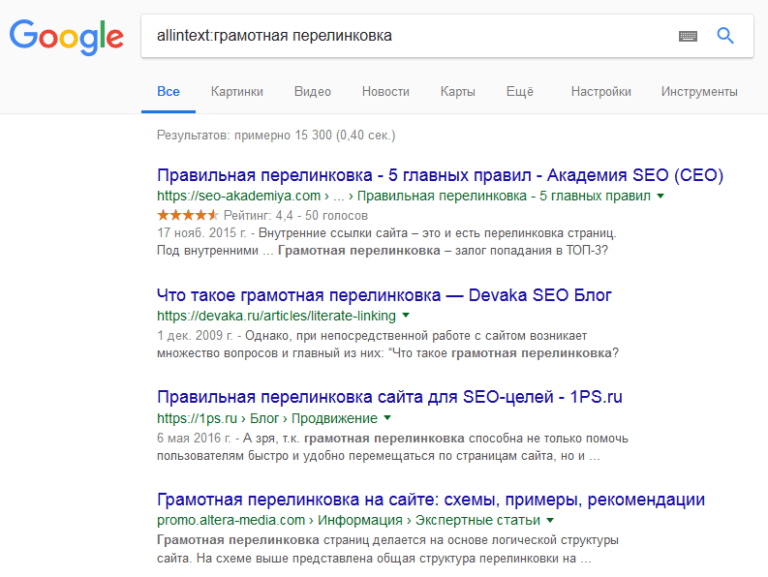 «intext« Аналог одноименной команды для Яндекса.
«intext« Аналог одноименной команды для Яндекса. 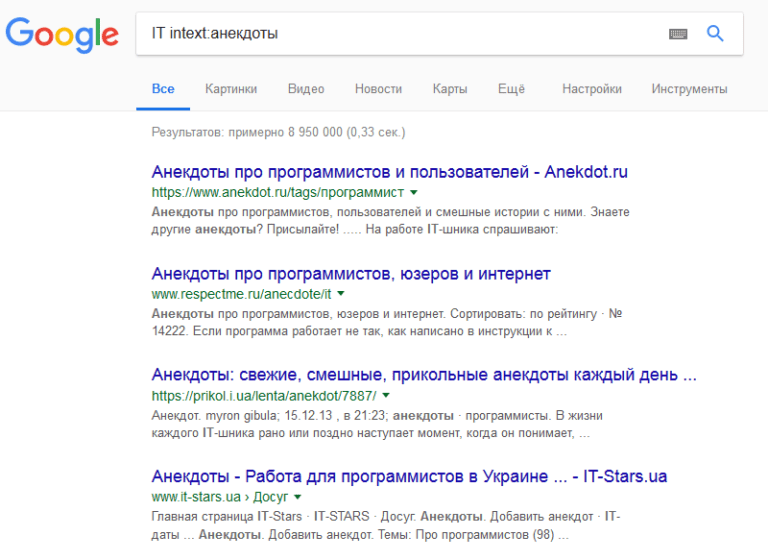 «allintitle« Точное вхождение в Title. Аналог яндексовского «title», но можно применять без скобок даже для выражений.
«allintitle« Точное вхождение в Title. Аналог яндексовского «title», но можно применять без скобок даже для выражений. 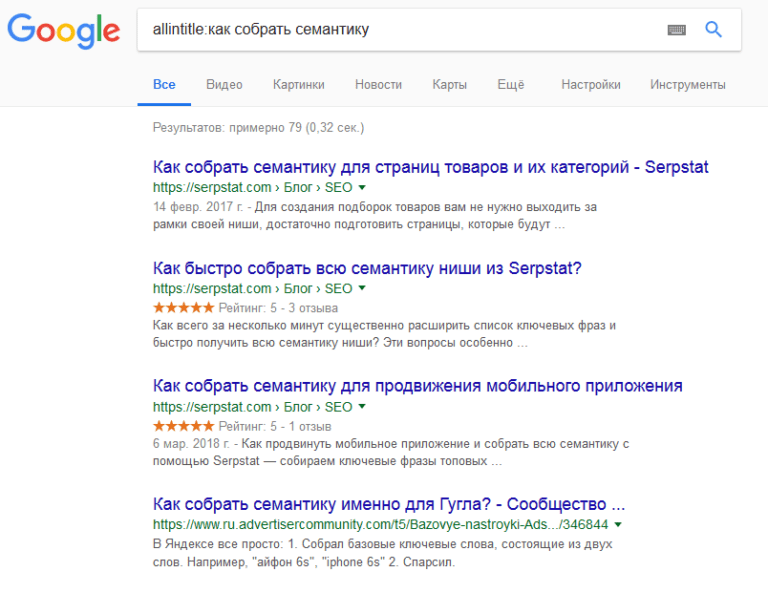 «intitle« Применим только для того, что написано сразу после двоеточия. Остальное распознается, как в обычном запросе.
«intitle« Применим только для того, что написано сразу после двоеточия. Остальное распознается, как в обычном запросе. 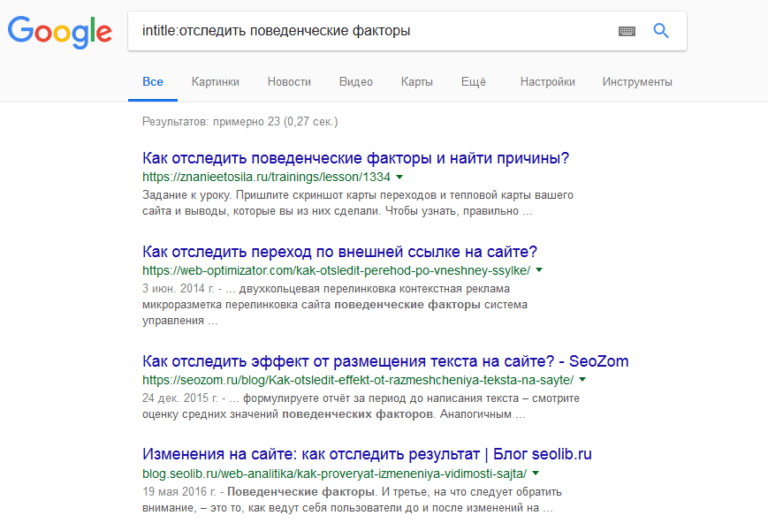 «cache« Данные ищутся в кэше, можно использовать для любых ресурсов. Например, для cache:fb.com результатом будет:
«cache« Данные ищутся в кэше, можно использовать для любых ресурсов. Например, для cache:fb.com результатом будет: 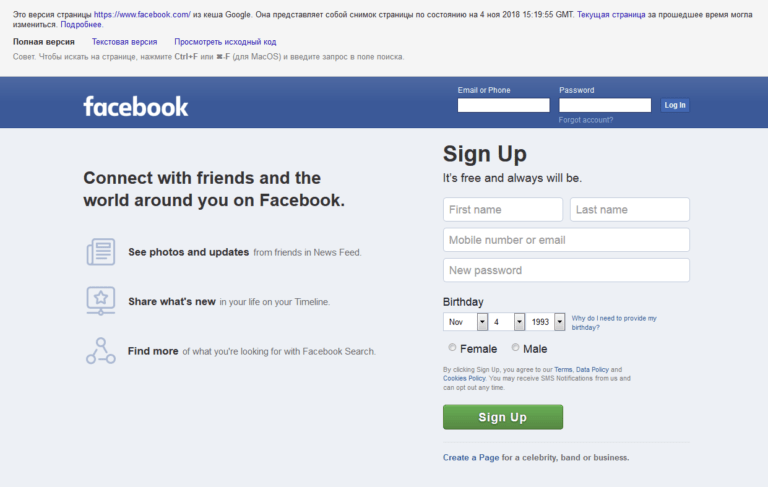 «info« Используется для проверки индексации странички.
«info« Используется для проверки индексации странички. 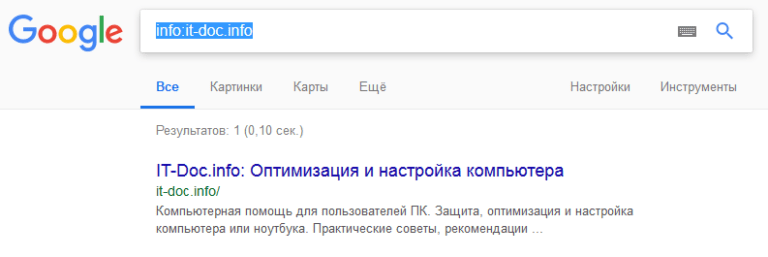 «allinanchor« Если в описании ссылки будут компоненты запроса, она попадет в выдачу.
«allinanchor« Если в описании ссылки будут компоненты запроса, она попадет в выдачу. 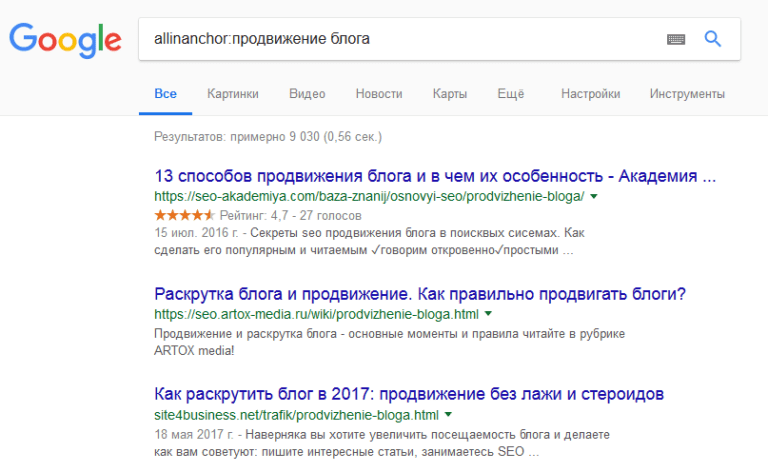 «inanchor« Команда та же, только вместо словосочетания можно использовать только одно название.
«inanchor« Команда та же, только вместо словосочетания можно использовать только одно название. 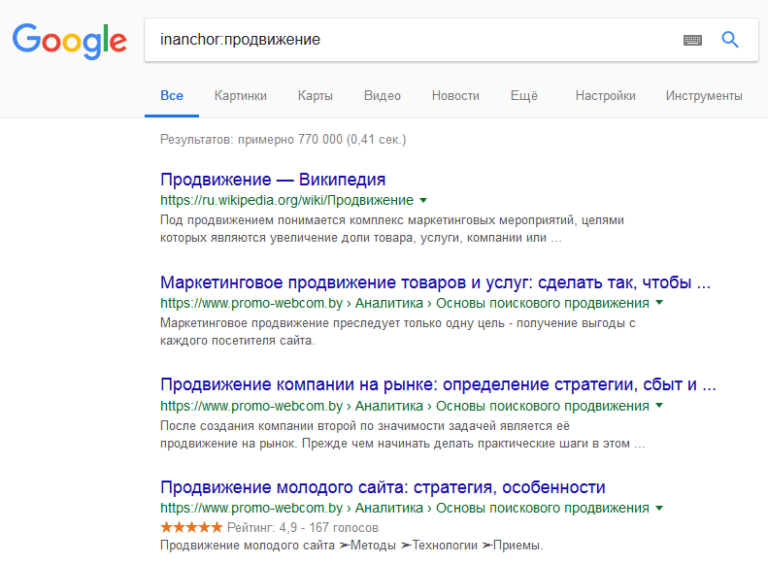
Логические
«OR« Аналог вертикального разделителя – «или». 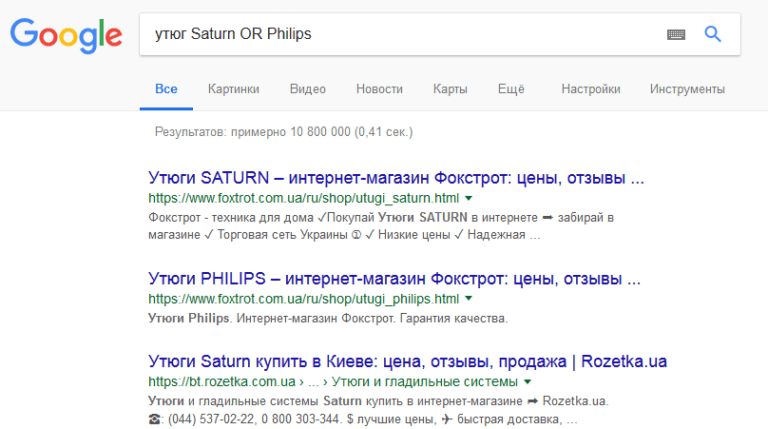 «..» Помогает искать с ограничениями по числам, например, мышку 500..2000 рублей
«..» Помогает искать с ограничениями по числам, например, мышку 500..2000 рублей 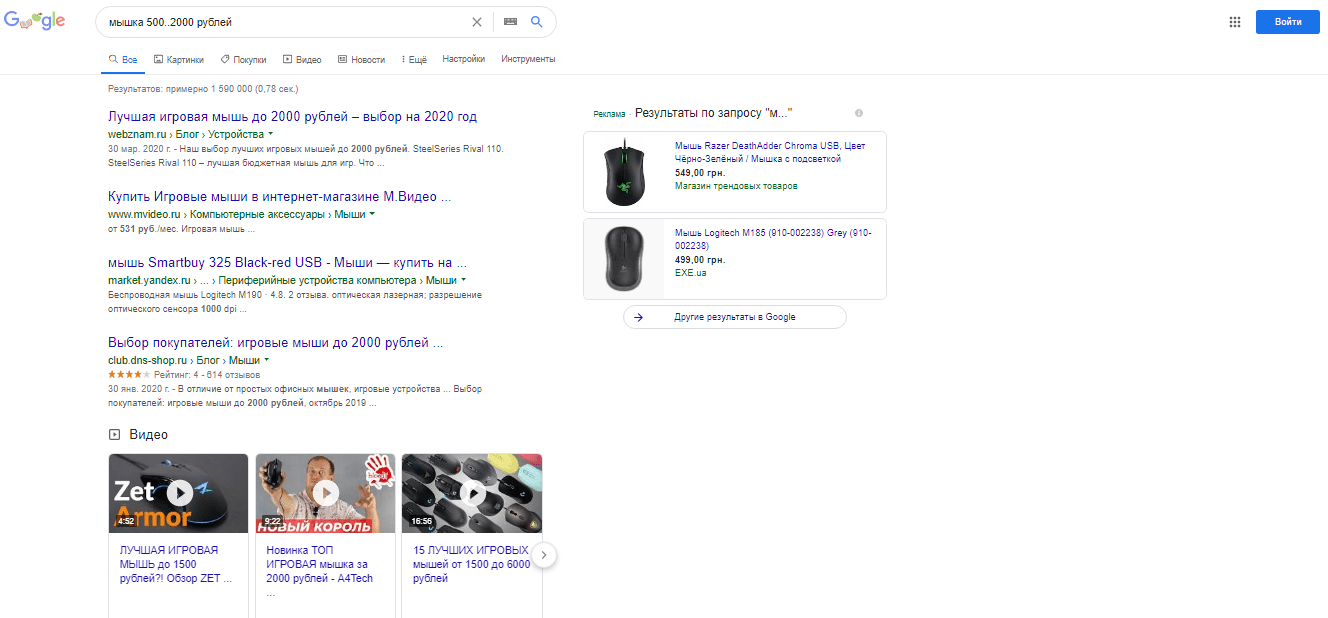 @ и # Это поиск по хештегам в социальных сетях.
@ и # Это поиск по хештегам в социальных сетях. 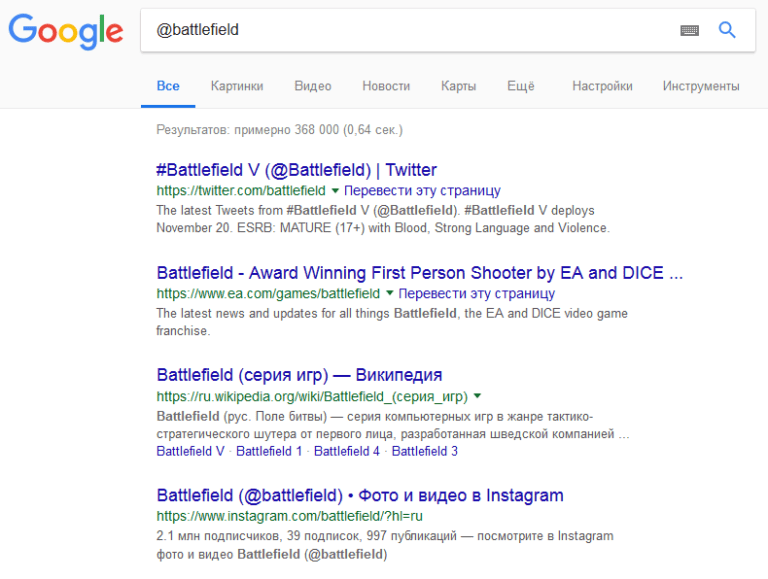
Лучшие комбинации
Чтобы повысить эффективность, предлагаем использовать сразу несколько лайфхаков. «Кавычки» и «date» Это поможет дать точный ответ на ваш вопрос и ограничить его временными рамками. 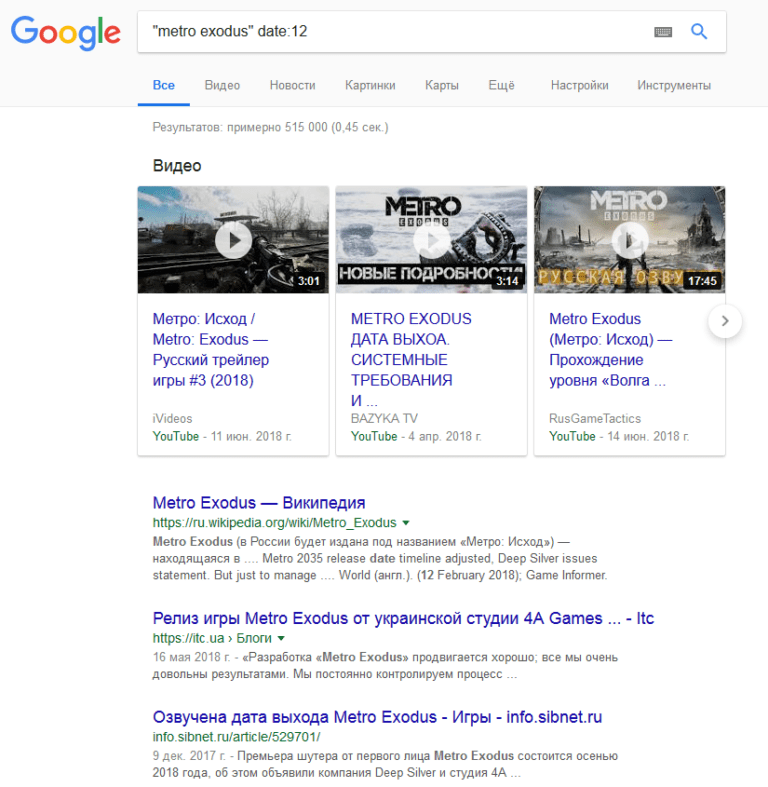 Запрос + «inurl» Это поможет найти отзывы о магазине, узнать мнение о курсах и пр.
Запрос + «inurl» Это поможет найти отзывы о магазине, узнать мнение о курсах и пр. 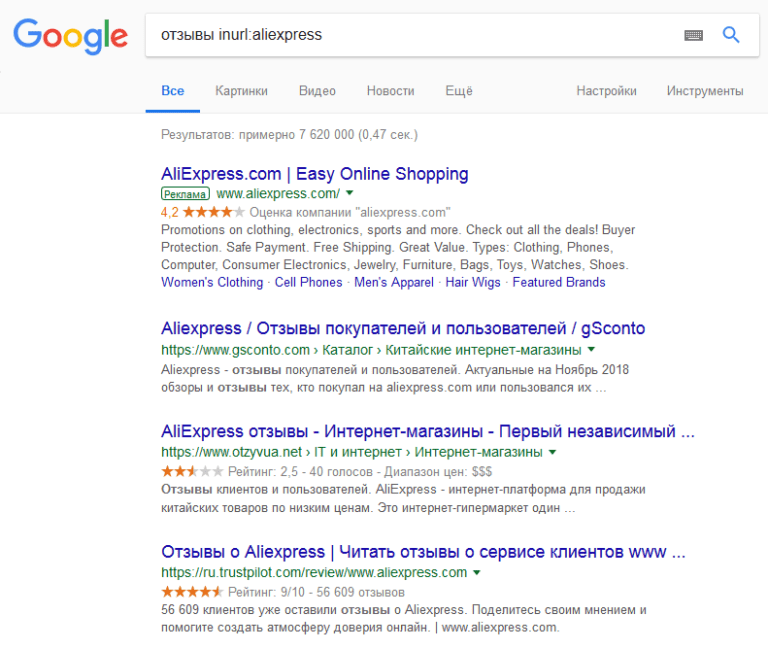 «Кавычки» и «site» Используется для поиска в блоге нужных данных, например, статьи автора или на определенную тематику.
«Кавычки» и «site» Используется для поиска в блоге нужных данных, например, статьи автора или на определенную тематику. 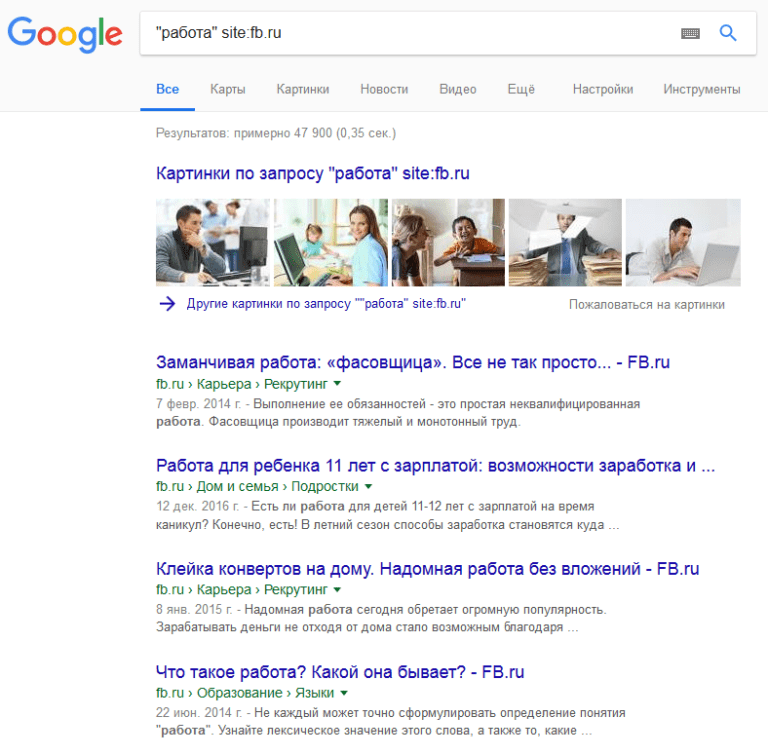 Комбинировать можно любые операторы, важно, чтобы они были предназначены для одной поисковой системы. Ежедневное использование их позволит облегчить себе работу, быстрее находить интересующую вас информацию, сделать проведенное за компьютером время более полезным. Если вы нашли выражения, обозначение которых не знаете, посмотрите, что они значат, в нашем словаре.
Комбинировать можно любые операторы, важно, чтобы они были предназначены для одной поисковой системы. Ежедневное использование их позволит облегчить себе работу, быстрее находить интересующую вас информацию, сделать проведенное за компьютером время более полезным. Если вы нашли выражения, обозначение которых не знаете, посмотрите, что они значат, в нашем словаре.
Google выдал: почему стали доступны документы пользователей в поисковиках
Пользователи стали жаловаться на то, что поиск «Яндекса» индексирует документы, созданные в Google Docs. «Яндекс» уже поменял правила поисковой выдачи, но, чтобы ситуация не повторилась, нужно изменить настройки в самом документе

Фото: Jaap Arriens / Zuma / Global Look Press
О том, что «Яндекс» стал индексировать содержание Google Docs, стало известно в среду, 4 июля, из сообщений интернет-пользователей в соцсетях. Сам «Яндекс» позже подтвердил, что вечером того же дня в службу поддержки компании начали обращаться пользователи с жалобами на доступность в поисковой выдаче документов из Google Docs. Среди них, например, были документы со списком паролей к различным ресурсам. В «Яндексе» подчеркнули, что поиск индексирует только те интернет-страницы, которые не защищены логином и паролем. Кроме того, страницы не попадают в выдачу, даже когда находятся в открытой части интернета, если администратор сайта, на котором они размещены, запретил их индексацию с помощью файла robots.txt. «Наша служба безопасности связывается сейчас с коллегами из Google, чтобы обратить их внимание на то, что в этих файлах может оказаться приватная информация», — говорил РБК представитель «Яндекса».

Представитель Google сообщил: «Поисковые системы могут индексировать только те документы, которые намеренно были сделаны их владельцами публичными, или когда кто-либо публикует ссылку на документ, владелец которого сделал его доступным для поиска и просмотра всем в интернете. Вы всегда можете изменить настройки доступа к вашим файлам и установить ограничения, что именно доступно для просмотра, комментирования или редактирования выбранным пользователям».
1. Как документы попали в поисковую выдачу
Google Docs — это бесплатный онлайн-офис, разработанный компанией Google. Облачное хранилище позволяет организовать удаленный доступ к размещенным на нем документам, а также обмениваться файлами. Опция сделать документ, размещенный в облаке, общедоступным — одна из основных для сервиса. Также пользователь может скрыть документ: тогда, кроме владельца файла, никто больше не получит к нему доступ. Если же пользователь делает документ общедоступным, то по ссылке, ведущей в файл, может пройти любой пользователь Сети, причем для этого ему не требуется аккаунт в Google Docs. Если пользователь видит, что созданный им документ просматривают люди из его списка контактов или анонимы (вместо аватара у них высвечиваются мордочки животных), значит, файл находится в общем доступе. Степень доступа устанавливается отдельно для каждого файла в настройках. Делясь файлом с другими, стоит обратить внимание на полномочия, которые будут иметь совладельцы документа. Для них можно выбрать статус редактора (разрешить менять доступ других пользователей, редактировать и скачивать файл), а можно ограничить функционал только просмотром документа и его комментированием. Владелец документа может сделать доступ к нему временным.
2. Когда поисковики начали индексировать документы Google Docs
По словам руководителя российского исследовательского центра «Лаборатории Касперского» Юрия Наместникова, все поисковые системы индексируют документы уже много лет и с определенной периодичностью появляются новости, что в поисковиках можно найти личные данные или документы, помеченные как секретные, причем хранящиеся как в облачных сервисах, так и на обычных сайтах организаций. Для поиска таких документов необходимо использовать специальные расширенные поисковые команды. «Ими пользуются, например, в рамках пентестов (тестов на проверку возможности взлома. — РБК), первичной киберразведки. Нередко этот легальный инструмент применяют киберпреступники, он позволяет находить информацию, которая обычным поиском не ищется. Нередко таким образом можно найти пароли и другую ценную информацию», — говорилось в сообщении фирмы по информационной безопасности Group IB в соцсетях. Руководитель департамента системных решений Group-IB Антон Фишман рассказал РБК, что расширенные поисковые запросы были всегда, но, чтобы в поиске отображались документы, необходимо было подбирать специальные команды. С какого-то момента в настройках поиска «Яндекса» появилась возможность искать по поддомену docs.google.com. Уточнить время появления эксперт не смог. «Зимой 2017 года (когда Group IB тестировала поиск «Яндекса». — РБК) такой возможности не было, когда она появилась — вчера или раньше, сказать сложно», — указал Фишман. По его словам, любая поисковая система постоянно совершенствует качество поиска, вносит изменения в свой движок и алгоритм индексации, поиска и выдачи результатов. 5 июля в 1:30 мск файлы Google Docs перестали отображаться в поисковой выдаче «Яндекса». Представитель российского поисковика не уточнил, как долго существовала эта опция и почему компания от нее отказалась.
3. Кто виноват
Group IB в своем сообщении в соцсетях указала, что ситуацию с Google Docs нельзя назвать утечкой конфиденциальных данных. «Это банальная халатность пользователей сервисов Google Docs и Google Drive (Google-диск — файловый хостинг, служба, предоставляющая пользователю место под его файлы и круглосуточный доступ к ним через интернет. — РБК). Когда вы создаете файл в Google Docs, у вас есть несколько опций по выбору доступа к нему. Если у вас в настройках стоит галочка напротив «общедоступно для поиска и просмотра», ваш файл может индексироваться поисковыми машинами. Google предупреждает пользователей о том, что поиск будет возможен. «Яндекс» также ничего не нарушает», — отмечалось в сообщении Group IB. В компании считают, что в том числе конфиденциальные документы стали общедоступными из-за небрежности пользователей и пренебрежения «элементарными правилами цифровой гигиены». Group IB порекомендовала пользователям, если они хотят сохранить приватность, проверить настройки доступа, которые они устанавливали на свои файлы, и убрать галочку напротив опции «доступно для поиска». Юрий Наместников также считает, что несправедливо возлагать ответственность за произошедшее на «Яндекс». «Робот ходит по ссылкам и индексирует все документы, которые он видит, и ему не запрещено трогать. Это задача владельцев веб-сервисов — правильно разграничить доступ», — отметил он. Если пользователь не хочет, чтобы при работе с документами в облаках, причем не только в сервисах Google, созданные ими документы/презентации/таблицы индексировались роботами, Наместников советует не ставить настройки доступа на «доступен всем». «Давайте права на просмотр и редактирование только тем, кому это действительно нужно, и предпочтительно давать доступ по приглашению, а не по ссылке», — указал представитель «Лаборатории Касперского».
В смысловой близости от. «Яндекс» представил новый поиск на основе алгоритма «Королев»
Крупнейшая поисковая система России «Яндекс» запустила новую версию поиска, в основе которой сопоставление смысла запроса и веб-страницы, сообщает компания. Новая версия поиска работает на алгоритме «Королев», который сравнивает семантические векторы поисковых запросов и веб-страниц полностью, а не только их заголовков.
«В прошлом году мы запустили новый алгоритм ранжирования „Палех“, в котором сделали первые шаги в сторону семантического поиска, а сегодня запускаем новый алгоритм ранжирования „Королев“. Почему мы выбрали такое название? Сергей Павлович Королев осуществил мечту человечества о полетах в космос. Для нас в „Яндексе“ сегодняшний запуск является таким же важным технологическим прорывом к мечте о поиске, который понимает пользователей», — сказал на презентации поиска руководитель службы релевантности лингвистики «Яндекс» Александр Сафронов.

Как это работает
Первые поисковые системы стали появляться в конце XX века. Тогда они были достаточно примитивными и даже в чем-то наивными. Они показывали пользователям страницы, которые содержат слова из запроса. Причем эти слова могли находиться далеко друг от друга и не быть связанными. Со временем алгоритмы ранжирования усложнялись, а точность ответов увеличивалась. Однако поиск оставался поиском лишь по словам.
«Со временем специалисты, которые занимаются поиском, стали все больше убеждаться в том, что для того, чтобы создать действительно хороший поиск, необходимо искать не по словам, а по смыслу, по-научному это называется семантический поиск», — отмечает Сафронов.
И специалисты «Яндекса» начали учить нейронные сети понимать смысл запросов.
«Чтобы обучать нейронную сеть, нам нужно показать ей много положительных и отрицательных примеров. Положительный пример — это запрос и текст страницы, которые связаны по смыслу. Отрицательный пример — это пара, которая по смыслу не связана. Чтобы текст получился, мы должны показать ей большое число примеров. Тут нам на помощь приходят пользователи», — поясняет Сафронов.
На основании пользовательского поведения специалисты и создают обучающие примеры, или эталоны, для нейронной сети. Например, если по какому-либо запросу пользователи очень часто кликают на одну и ту же страницу, то, вероятнее всего, запрос и текст страницы связаны по смыслу, то есть семантически.
«После тренировки наша модель имеет способность представлять текст в виде особого набора чисел. Мы называем этот набор чисел семантическим вектором. Он формируется последним скрытым слоем нейронной сети. Таким образом, подавая на вход нейронной сети любой текст, мы получаем соответствующий ему семантический вектор. В наших моделях мы обычно представляем текст в виде 300 чисел», — рассказывает Сафронов.
При этом чем ближе тексты по смыслу, тем больше будет сходство у чисел этих векторов. То есть, сравнивая семантические векторы, можно оценить смысловую близость текстов.

Что изменилось
В алгоритме «Королев» существенно увеличено влияние нейронных сетей на ранжирование. Так, их стали применять к тексту документа.
«Раньше у нас были модели, которые оценивают близость только запроса и заголовка страницы. А теперь мы внедрили модель, которая при оценке близости смотрит не только на заголовок, но и на тело страницы», — отметил Сафронов.
Другим нововведением стало количество страниц, в которых применяются нейронные сети. Раньше «Яндекс.Поиск» использовал нейронные сети только для 150 страниц, а в «Королеве» количество страниц, на которых высчитывается смысловая близость по запросу, достигает 200 тысяч.
Люди учат машины
Одна из проблем в работе с нейронными сетями — это найти образцовый пример, эталон, как делать правильно. Чтобы обучить новый поиск, специалистам «Яндекса» приходится самим определять такие эталоны. Сбором данных для машинного обучения в компании уже несколько лет занимаются специальные люди — асессоры. На сегодняшний день их около 1400—1500. Асессор получает случайный пользовательский запрос и документы, которые могли быть найдены по нему. И задача такого работника — оценить, насколько тот или иной документ может быть хорошим ответом на запрос пользователя.
«Чтобы собирать все больше данных, нам требовалось больше людей, — рассказывает руководитель обработки данных „Яндекса“ Ольга Мегорская. — Когда асессоров стало больше полутора тысяч, а их все равно не хватало, мы поняли, что надо что-то менять. Что технологии и области применения машинного обучения развиваются так быстро, что никакая команда не будет способна удовлетворить постоянно растущие потребности в обучающих данных».
И компания запустила краудсорсинговую платформу, на которой любой желающий может зарегистрироваться как исполнитель, найти интересные задания и выполнять их за вознаграждение. А любой заказчик, которому нужны данные для машинного обучения, может там же разместить заказы. Платформа получила название «Толока». Этим словом называли типичный для русской деревни общий сход людей, когда сообща все делали одно большое дело.
«На нашей платформе за несколько лет ее существования собралось уже больше одного миллиона толокеров. Сообща они сделали больше двух миллиардов оценок, которые пошли на обучение искусственного интеллекта», — заявляет Мегорская.

Неудобные вопросы
«„Яндекс“ ежедневно получает порядка 200 млн запросов. И треть из них задают один единственный раз, и больше никогда не задают. Это такие сложные запросы, на них нельзя хорошо отвечать при помощи пользовательской статистики», — рассказывает руководитель поиска «Яндекса» Андрей Стыскин.
Примером такого сложного запроса может быть поиск названия фильма «про космос, где отец общался с дочерью при помощи секундной стрелки» (спойлер: это про «Интерстеллар»).
«Ни в одном документе так не описывается этот фильм. Но благодаря технологии „Королев“ мы умеем понимаем суть описания из текста запроса и суть описания из документа и их сопоставлять. И умеем отвечать на такие сложные запросы», — поясняет Стыскин.
Говоря о том, что обновленный поисковик все-таки не умеет делать, Стыскин признался, что его команда испытывает сложности с поиском «информации, которой в интернете пока не существует»: неоцифрованные, закрытые библиотеки и соцсети, которые не дают данные для индексации.
Не так давно «Яндекс» презентовал и новый алгоритм машинного обучения — CatBoost, умеющий работать с алгоритмами.
Алиса Веселкова