Обучение модели машинного обучения с помощью перекрестной проверки
Узнайте, как использовать перекрестную проверку для обучения более надежных моделей машинного обучения в ML.NET.
Кросс-валидация — это методика обучения и оценки модели, которая разбивает данные на несколько секций и обучает несколько алгоритмов на этих секциях. Этот метод повышает надежность модели, удерживая данные вне процесса обучения. Кроме повышения производительности на многих неучитываемых наблюдениях, в средах с ограниченными данными он может быть эффективным инструментом для обучения моделей с меньшим набором данных.
Данные и модель данных
Используя данные из файла, который имеет следующий формат:
Size (Sq. ft.), HistoricalPrice1 ($), HistoricalPrice2 ($), HistoricalPrice3 ($), Current Price ($) 620.00, 148330.32, 140913.81, 136686.39, 146105.37 550.00, 557033.46, 529181.78, 513306.33, 548677.95 1127.00, 479320.99, 455354.94, 441694.30, 472131.18 1120.00, 47504.98, 45129.73, 43775.84, 46792.41 Данные можно моделировать с помощью класса, например, HousingData , и загружать в IDataView .
public class HousingData < [LoadColumn(0)] public float Size < get; set; >[LoadColumn(1, 3)] [VectorType(3)] public float[] HistoricalPrices < get; set; >[LoadColumn(4)] [ColumnName("Label")] public float CurrentPrice < get; set; >> Подготовка данных
Следует предварительно обработать данные перед их использованием для создания модели машинного обучения. В этом примере Size столбцы и HistoricalPrices объединяются в один вектор признаков, который выводится в новый столбец с именем Features с помощью Concatenate метода . Кроме получения данных в формате, ожидаемом алгоритмами ML.NET, сцепка столбцов оптимизирует последующие операции в конвейере, применяя операцию один раз для объединенного столбца, а не обрабатывая каждый отдельный столбец.
Как только столбцы объединяются в один вектор, NormalizeMinMax применяется к столбцу Features , чтобы получить Size и HistoricalPrices в одном и том же диапазоне 0–1.
// Define data prep estimator IEstimator dataPrepEstimator = mlContext.Transforms.Concatenate("Features", new string[] < "Size", "HistoricalPrices" >) .Append(mlContext.Transforms.NormalizeMinMax("Features")); // Create data prep transformer ITransformer dataPrepTransformer = dataPrepEstimator.Fit(data); // Transform data IDataView transformedData = dataPrepTransformer.Transform(data); Обучение модели с помощью кросс-валидации
Когда данные предварительно обработаны, пришло время для обучения модели. Во-первых, выберите алгоритм, который наиболее точно соответствует задаче машинного обучения. Поскольку прогнозируемое значение является числовым и непрерывным, задача — регрессия. Один из алгоритмов регрессии, реализуемый ML.NET, – алгоритм StochasticDualCoordinateAscentCoordinator . Для обучения модели с использованием кросс-валидации используется метод CrossValidate .
Несмотря на то что в этом примере используется модель линейной регрессии, CrossValidate применяется для всех других задач машинного обучения в ML.NET, за исключением обнаружения аномалий.
// Define StochasticDualCoordinateAscent algorithm estimator IEstimator sdcaEstimator = mlContext.Regression.Trainers.Sdca(); // Apply 5-fold cross validation var cvResults = mlContext.Regression.CrossValidate(transformedData, sdcaEstimator, numberOfFolds: 5); CrossValidate выполняет следующие действия.
- Разбивает данные на несколько секций по значению, указанному в параметре numberOfFolds . В результате каждая секция превратится в объект TrainTestData .
- Модель обучается на каждой из секций с помощью указанного алгоритма оценки машинного обучения в наборе данных для обучения.
- Эффективность каждой модели оценивается с помощью метода Evaluate на тестовом наборе данных.
- Для всех моделей возвращается сама модель, а также ее метрики.
Результат в cvResults сохраняется в коллекции объектов CrossValidationResult . Этот объект включает обученную модель, а также метрики, доступные через свойства Model и Metrics соответственно. В этом примере свойство Model имеет тип ITransformer , а свойство Metrics имеет тип RegressionMetrics .
Оценка модели
Метрики для разных обученных моделей доступны через свойства Metrics отдельного объекта CrossValidationResult . В этом случае метрика R-квадрат извлекается и сохраняется в переменной rSquared .
IEnumerable rSquared = cvResults .Select(fold => fold.Metrics.RSquared); Если проверить содержимое переменной rSquared , в выходных данных должно быть пять значений в диапазоне от 0 до 1, где близость к 1 означает, что эта модель лучше. С помощью таких метрик, как R-квадрат, отранжируйте модели от лучших к наихудшим. Затем выберите лучшую модель для прогнозов или дополнительных операций.
// Select all models ITransformer[] models = cvResults .OrderByDescending(fold => fold.Metrics.RSquared) .Select(fold => fold.Model) .ToArray(); // Get Top Model ITransformer topModel = models[0]; Совместная работа с нами на GitHub
Источник этого содержимого можно найти на GitHub, где также можно создавать и просматривать проблемы и запросы на вытягивание. Дополнительные сведения см. в нашем руководстве для участников.
Кросс-валидация
Кросс-валидация или скользящий контроль — процедура эмпирического оценивания обобщающей способности алгоритмов. С помощью кросс-валидации эмулируется наличие тестовой выборки, которая не участвует в обучении, но для которой известны правильные ответы.
Определения и обозначения
Пусть [math] X [/math] — множество признаков, описывающих объекты, а [math] Y [/math] — конечное множество меток.
[math]T^l = <(x_i, y_i)>_^, x_i \in X, y_i \in Y[/math] — обучающая выборка,
[math]Q[/math] — мера качества,
[math]\mu: (X \times Y)^l \to A, [/math] — алгоритм обучения.
Разновидности кросс-валидации
Валидация на отложенных данных (Hold-Out Validation)
Обучающая выборка один раз случайным образом разбивается на две части [math] T^l = T^t \cup T^ [/math]
![]()
После чего решается задача оптимизации:
[math]HO(\mu, T^t, T^) = Q(\mu(T^t), T^) \to min [/math] ,
Метод Hold-out применяется в случаях больших датасетов, т.к. требует меньше вычислительных мощностей по сравнению с другими методами кросс-валидации. Недостатком метода является то, что оценка существенно зависит от разбиения, тогда как желательно, чтобы она характеризовала только алгоритм обучения.
Полная кросс-валидация (Complete cross-validation)
- Выбирается значение [math]t[/math] ;
- Выборка разбивается всеми возможными способами на две части [math] T^l = T^t \cup T^ [/math] .
![]()
Здесь число разбиений [math]C_l^[/math] становится слишком большим даже при сравнительно малых значениях t, что затрудняет практическое применение данного метода.
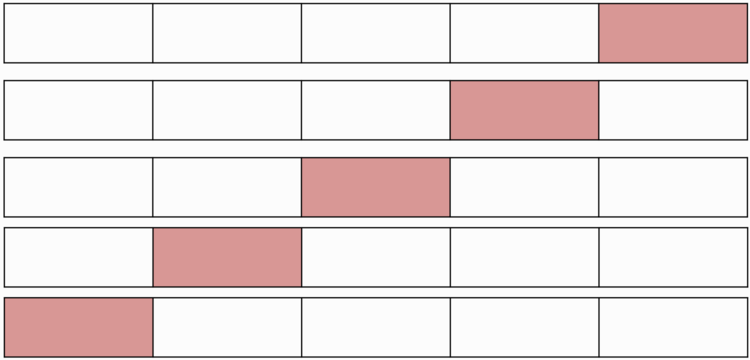
k-fold кросс-валидация
- Обучающая выборка разбивается на [math] k [/math] непересекающихся одинаковых по объему частей;
- Производится [math] k [/math] итераций. На каждой итерации происходит следующее:
- Модель обучается на [math] k — 1 [/math] части обучающей выборки;
- Модель тестируется на части обучающей выборки, которая не участвовала в обучении.
Каждая из [math]k[/math] частей единожды используется для тестирования. Как правило, [math]k = 10[/math] (5 в случае малого размера выборки).
[math]T^l = F_1 \cup \dots \cup F_k, |F_i| \approx \frac, \\ CV_k = \frac \sum_^ Q(\mu(T^l \setminus F_i),F_i) \to min [/math] .
# Пример кода для k-fold кросс-валидации: # Пример классификатора, cпособного проводить различие между всего лишь двумя # классами, "пятерка" и "не пятерка" из набор данных MNIST import numpy as np from sklearn.model_selection import StratifiedKFold from sklearn.datasets import fetch_openml from sklearn.base import clone from sklearn.linear_model import SGDClassifier mnist = fetch_openml('mnist_784', version=1) X, y = mnist["data"], mnist["target"] y = y.astype(np.uint8) X_train, X_test, y_train, y_test = X[:60000], X[60000:], y[:60000], y[60000:] y_train_5 = (y_train == 5) # True для всех пятерок, False для всех остальных цифр. Задача опознать пятерки y_test_5 = (y_test == 5) sgd_clf = SGDClassifier(random_state=42) # классификатор на основе метода стохастического градиентного спуска (Stochastic Gradient Descent SGD) # Разбиваем обучающий набора на 3 блока # выработку прогнозов и их оценку осуществляем на каждом блоке с использованием модели, обученной на остальных блоках skfolds = StratifiedKFold(n_splits=3, random_state=42) for train_index, test_index in skfolds.split(X_train, y_train_5): clone_clf = clone(sgd_clf) X_train_folds = X_train[train_index] y_train_folds = y_train_5[train_index] X_test_fold = X_train[test_index] y_test_fold = y_train_5[test_index] clone_clf.fit(X_train_folds, y_train_folds) y_pred = clone_clf.predict(X_test_fold) n_correct = sum(y_pred == y_test_fold) print(n_correct / len(y_pred)) # print 0.95035 # 0.96035 # 0.9604t×k-fold кросс-валидация
- Процедура выполняется [math]t[/math] раз:
- Обучающая выборка случайным образом разбивается на [math]k[/math] непересекающихся одинаковых по объему частей;
- Производится [math] k [/math] итераций. На каждой итерации происходит следующее:
- Модель обучается на [math] k — 1 [/math] части обучающей выборки;
- Модель тестируется на части обучающей выборки, которая не участвовала в обучении.
[math]T^l = F_ \cup \dots \cup F_ = \dots = F_ \cup \dots \cup F_, |F_| \approx \frac [/math] ,
Кросс-валидация по отдельным объектам (Leave-One-Out)
Выборка разбивается на [math]l-1[/math] и 1 объект [math]l[/math] раз.
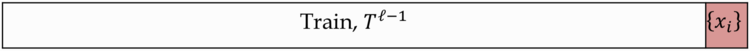
[math]LOO = \frac \sum_^ Q(\mu(T^l \setminus p_i),p_i) \to min [/math] , где [math]p_i = (x_i, y_i)[/math] .
Преимущества LOO в том, что каждый объект ровно один раз участвует в контроле, а длина обучающих подвыборок лишь на единицу меньше длины полной выборки.
Недостатком LOO является большая ресурсоёмкость, так как обучаться приходится [math]L[/math] раз. Некоторые методы обучения позволяют достаточно быстро перенастраивать внутренние параметры алгоритма при замене одного обучающего объекта другим. В этих случаях вычисление LOO удаётся заметно ускорить.
Случайные разбиения (Random subsampling)
Выборка разбивается в случайной пропорции. Процедура повторяется несколько раз.

Критерий целостности модели (Model consistency criterion)
Не переобученый алгоритм должен показывать одинаковую эффективность на каждой части.

Метод может быть обобщен как аналог [math] CV_ [/math] .
См. также
- Общие понятия
- Модель алгоритма и ее выбор
- Мета-обучение
Примечания
Источники информации
- Скользящий контроль — статья на MachineLearning.ru
- Model assessment and selection
Введение в кросс-валидацию k-fold

Перекрестная проверка (кросс-валидация или скользящий контроль) — это статистический метод, используемый для оценки модели машинного обучения на независимых данных.
Проверка обычно используется в прикладном машинном обучении для сравнения и выбора модели для данной проблемы прогнозного моделирования, потому что она проста для понимания, проста в реализации и приводит к оценке качесва, которые обычно имеют более низкую предвзятость, чем другие методы.
В этом уроке мы рассмотрим процедуру кросс-валидации k-fold для оценки качества моделей машинного обучения.
После завершения этого урока, вы будете знать:
- Как использовать k-fold кросс-валидацию для оценки квалификации модели на новых данных.
- общие тактики, которые можно использовать, чтобы выбрать значение k для набора данных.
- широко используемые вариации на перекрестной проверки, такие как стратифицированы (stratified) и repeated, которые доступны в библиотеки scikit-learn.
Урок состоит из 5 частей:
- k-Fold Кросс-Валидация
- Конфигурация k
- Рабочий пример
- Работы с API кросс-валидации
- Вариации на кросс-валидации
k-Fold кросс-Валидация
Перекрестная проверка — это процедура повторной выборки, используемая для оценки моделей машинного обучения на ограниченной выборке данных.
Процедура имеет один параметр, называемый k, который относится к числу групп, на которые должна быть разделена данная выборка данных. Таким образом, процедура часто называется перекрестной проверкой (кросс-валидацией) k-fold. При выборе определенного значения для k, оно может быть использовано вместо k в ссылке на модель, например, при k=10, становится 10-кратной перекрестной проверкой.
Перекрестная проверка в основном используется в прикладном машинном обучении для оценки квалификации модели машинного обучения на не используемых данных. То есть использовать ограниченную выборку (test sample) для оценки того, как модель будет работать в целом при использовании ее при прогнозирования на данных, не используемых во время обучения модели.
Это популярный метод, потому что он прост для понимания и потому, что это обычно приводит к менее предвзятой или менее оптимистичной оценки качества модели, чем другие методы, такие как обучение / тест .
Общая процедура заключается в следующем:
1. Перемешайте датасет случайным образом
2. Разделите датасет на k-групп
3. Для каждой уникальной выборки:
- Возьмите группу в качестве тестирования датасета
- Возьмите остальные группы в качестве выборки учебных данных
- Приготовьте модель на обучаемых выборках и оцените ее на тестовой выборке
- Сохраняйте оценку модели и отбросьте модель
4. Обобщите параметры качества модели с помощью выборки оценки моделей
Важно отметить, что каждое наблюдение в выборке данных назначается отдельной группе и остается в этой группе в течение всего срока действия процедуры. Это означает, что каждому образцу предоставляется возможность использоваться в наборе 1 раз и использоваться для обучения модели k-1 раз.
Отдельно стоит подчеркнуть, чтобы любая подготовка данных до подбора модели происходила на выборке учебных данных, заданных кросс-валидацией в цикле, а не на более широком наборе данных. Это также относится к любой настройке гиперпараметров. Невыполнение этих операций в цикле может привести к утечке данных и оптимистичной оценке качества модели.
Результаты кросс-валидации k-fold часто суммируются со средним итогом качества модели. Также хорошей практикой является включение показателя дисперсии оценок качества, таких как стандартное отклонение или стандартная ошибка.
Конфигурация параметра k
Значение k должно быть тщательно выбрано для выборки данных.
Плохо выбранное значение для k может привести к неправильному представлению о качестве модели, например, к оценке с высокой дисперсией (которая может сильно измениться на основе данных, используемых в соответствии с моделью), или к высокой предвзятости (например, переоценка качества модели).
Существуют три подхода для выбора значения параметра k:
- Представитель: Значение для k выбрано таким образом, что каждая группа подборка/тестовая группа данных достаточно велика, чтобы быть статистически репрезентативной для более широкого набора данных.
- k=10: Значение для k фиксируется до 10. Данное число было найдено в ходе экспериментов и обычно приводит к оценке качества модели с низкой предвзятостью небольшую дисперсии.
- k = n: Значение для k фиксируется на n, где n является размером набора данных, чтобы дать каждому тестовой группе возможность быть использованной в наборе данных.
k выбирают обычно 5 или 10, но нет формального правила. По мере того как k становится больше, разница в размере между тестовой выборкой и подмножествами resampling становится мала. По мере уменьшения этой разницы предвзятость к технике становится меньше.
Если выбрано значение для k, которое не делит датасет равномерно, то одна группа будет содержать оставшуюся часть примеров. Предпочтительно разделить исходный датасет на группы k с одинаковым количеством данных, так что выборка оценки качества моделей была эквивалентна.
Рабочий пример
Чтобы сделать процедуру перекрестной проверки конкретной, давайте посмотрим на пример спроработанных.
Представьте, что у нас есть выборка данных с 6 наблюдениями:
[0.1, 0.2, 0.3, 0.4, 0.5, 0.6]Первым шагом является выбор значения для k для определения количества выборок, используемых для разделения данных. Здесь мы будем использовать значение k=3. Это означает, что мы будем тасовать данные, а затем разделить данные на 3 группы. Поскольку у нас есть 6 наблюдений, каждая группа будет иметь равно 2 наблюдения.
subset1: [0,5, 0,2] subset2: [0,1, 0,3] subset3: [0,4, 0,6]Затем мы можем использовать образец, например, для оценки качества алгоритма машинного обучения.
Три модели обучаются и оцениваются с каждой раз дается шанс быть протянутой набор испытаний.
- Модель1: обучаем на subset1 и subset2, тестируем на subset3
- Модель2: обучаем на subset2 и subset3, тестируем на subset1
- Модель3: обучаем на subset1 и subset3, тестируем на subset2
После того, как они модели оцениваются, затем отбрасываются поскольку они послужили своей цели.
Оценки качества собираются для каждой модели и суммируются для использования.
API кросс-валидации
Мы не должны осуществлять k-fold проверки вручную. Библиотека scikit-learn предоставляет реализацию, которая поможет разделить датасет .
Метод KFold() из библиотеки scikit-learn может быть использован. Он принимает в качестве аргументов количество выборок на которое надо разбить датасет, следует ли перетасовывать датасет, и числовую затравку для псевдослучайного генератора чисел, используемого до перетасовки датасета.
Например, мы можем создать экземпляр, который разделяет набор данных на 3 выборки, перетасует их до разделения и использует значение 1 для генератора псевдослучайных чисел.
kfold = KFold(3, True, 1)Функция split() может быть вызвана на классе, в котором в качестве аргумента приводится выборка данных. При повторном вызове, split() будет возвращать выборки данных на которых идет обучение и тестовый выборка. В частности, возвращаются массивы, содержащие индексы, в исходный датасет, в можно указываются ссылки как на обучаемую выборку, так и на тестовую выборку на каждой итерации.
Например, мы можем перечислить разделения индексов для выборки данных с помощью созданного экземпляра KFold следующим образом:
#перечисление выборок датасета for train, test in kfold.split(data): print('train: %s, test: %s' % (train, test))Мы можем связать все это вместе с нашим датасетом, используемым в примере из предыдущего раздела.
# scikit-learn k-fold кросс-валидация from numpy import arrayfrom sklearn.model_selection import KFold # датасет data = array([0.1, 0.2, 0.3, 0.4, 0.5, 0.6]) # подготовьте кросс валидацию kfold = KFold(3, True, 1) # перечисление выборок датасета for train, test in kfold.split(data): print('train: %s, test: %s' % (data[train], data[test]))При выполнении примера выводятся конкретные наблюдения, выбранные для каждого поезда и тестового набора. Индексы используются непосредственно в исходном массиве данных для получения значений наблюдений.
train: [0.1 0.4 0.5 0.6], test: [0.2 0.3] train: [0.2 0.3 0.4 0.6], test: [0.1 0.5] train: [0.1 0.2 0.3 0.5], test: [0.4 0.6]Реализация перекрестной проверки k-fold в scikit-learn предоставляется в качестве компонентной операции в рамках более широких методов, таких как гиперпараметры модели поиска сетки и оценка модели на наборе данных.
Тем не менее, класс KFold может быть использован непосредственно для того, чтобы разделить набор данных до моделирования, чтобы все модели использовали одни и те же разделения данных. Это особенно полезно, если вы работаете с очень большим датасетом. Использование одних и тех же разделений между алгоритмами может иметь преимущества для статистических тестов, которые вы можете выполнить на данных позже.
Вариации на кросс-валидацию
Существует ряд вариаций процедуры перекрестной проверки k-fold.
Три часто используемых варианта:
- Обучение / Тест выборка: Самая крайность, это когда k = 2 (не 1) так, что одна выборка идет на обучение и одна и тест для оценки модели.
- LOOCV: Другая крайность, когда k равен общему размеру наблюдений в датасете. По-английски это называется leave-one-out cross-validation, или LOOCV для краткости.
- Стратифицированная выборка (stratified): разделение данных на складки может регулироваться такими критериями, чтобы каждая выборка имела одинаковую пропорцию наблюдений с заданным категоричным значением, например значением класса. Это называется стратифицированной перекрестной проверкой.
- Повторяющаяся выборка (repeated): k-fold перекрестная валидация повторяется n раз, и датасет перетасовывается на каждой итерации, что приводит к иной выборки данных.
Библиотека scikit-learn предоставляет набор реализации перекрестной проверки
Подведем итог
В этом уроке вы узнали про процедуру перекрестной проверки k-fold для оценки качества моделей машинного обучения.В частности, вы узнали:
- Что k-fold кросс валидация это процедура, используемая для оценки квалификации модели на новых данных.
- общие тактики, которые можно использовать, чтобы выбрать значение k для набора данных.
- широко используемые вариации кросс-валидации, такие как стратифицированные и повторяющиеся, которые доступны в scikit-learn.
Полезные ссылки:
- sklearn.model_selection.KFold() API
- sklearn.model_selection: Model Selection API
Что такое кросс-валидация
Перекрёстная проверка (кросс-валидация, Cross-validation) — метод оценки аналитической модели и её поведения на независимых данных. При оценке модели имеющиеся в наличии данные разбиваются на k частей. Затем на k−1 частях данных производится обучение модели, а оставшаяся часть данных используется для тестирования. Процедура повторяется k раз; в итоге каждая из k частей данных используется для тестирования. В результате получается оценка эффективности выбранной модели с наиболее равномерным использованием имеющихся данных.
Обычно кросс-валидация используется в ситуациях, где целью является предсказание, и хотелось бы оценить, насколько предсказывающая модель способна работать на практике. Один цикл кросс-валидации включает разбиение набора данных на части, затем построение модели на одной части (называемой тренировочным набором), и валидация модели на другой части (называемой тестовым набором). Чтобы уменьшить разброс результатов, разные циклы кросс-валидации проводятся на разных разбиениях, а результаты валидации усредняются по всем циклам.
Кросс-валидация важна для защиты от гипотез, навязанных данными («ошибки третьего рода»), особенно когда получение дополнительных данных затруднительно или невозможно.
Предположим, у нас есть модель с одним или несколькими неизвестными параметрами, и набор данных, на котором эта модель может быть оптимизирована (тренировочный набор). Процесс подгонки оптимизирует параметры модели и делает модель настолько подходящей под тренировочный набор, насколько это возможно. Если мы теперь возьмем независимый образец данных для валидации модели из того же источника, откуда мы взяли тренировочный набор данных, обычно обнаруживается, что модель описывает тестовые данные хуже, чем тренировочный набор. Это называется переподгонкой (overfitting), и особенно часто встречается в ситуациях, когда размер тренировочного набора невелик, или когда число параметров в модели велико. Кросс-валидация это способ оценить способность модели работать на гипотетическом тестовом наборе, когда такой набор в явном виде получить невозможно.
Распространенные типы кросс-валидации
Кросс-валидация по K блокам (K-fold cross-validation)
В этом случае исходый набор данных разбивается на K одинаковых по размеру блока. Из K блоков один оставляется для тестирования модели, а остающиеся K-1 блока используются как тренировочный набор. Процесс повторяется K раз, и каждый из блоков используется один раз как тестовый набор. Получаются K результатов, по одному на каждый блок, они усредняются или комбинируются каким-либо другим способом, и дают одну оценку. Преимущество такого способа перед случайным сэмплированием (random subsampling) в том, что все наблюдения используются и для тренировки, и для тестирования модели, и каждое наблюдение используется для тестирования в точности один раз. Часто используется кросс-валидация на 10 блоках, но каких-то определенных рекомендаций по выбору числа блоков нет.
В послойной кросс-валидации блоки выбираются таким образом, что среднее значение ответа модели примерно равно по всем блокам.
Валидация последовательным случайным сэмплированием (random subsampling)
Этот метод случайным образом разбивает набор данных на тренировочный и тестовый наборы. Для каждого такого разбиения, модель подгоняется под тренировочные данные, а точность предсказания оценивается на тестовом наборе. Результаты затем усредняются по всем разбиениям. Преимущество такого метода перед кросс-валидацией на K блоках в том, что пропорции тренировочного и тестового наборов не зависят от числа повторений (блоков). Недостаток метода в том, что некоторые наблюдения могут ни разу не попасть в тестовый набор, тогда как другие могут попасть в него более, чем один раз. Другими словами, тестовые наборы могут перекрываться. Кроме того, поскольку разбиения проводятся случайно, результаты будут отличаться в случае повторного анализа.
В послойном варианте этого метода, случайные выборки генерируются таким способом, при котором средний ответ модели равен по тренировочному и тестовому наборам. Это особенно полезно, когда ответ модели бинарен, с неравными пропорциями ответов по данным.
Поэлементная кросс-валидация (Leave-one-out, LOO)
Здесь отдельное наблюдение используется в качестве тестового набора данных, а остальные наблюдения из исходного набора – в качестве тренировочного. Цикл повторяется, пока каждое наблюдение не будет использовано один раз в качестве тестового. Это то же самое, что и K-блочная кросс-валидация, где K равно числу наблюдений в исходном наборе данных.
Оценка соответствия модели
Цель кросс-валидации в том, чтобы оценить ожидаемый уровень соответствия модели данным, независимым от тех данных, на которых модель тренировалась. Она может использоваться для оценки любой количественной меры соответствия, подходящей для данных и модели. Например, для задачи бинарной классификации, каждый случай в тестовом наборе будет предсказан правильно или неправильно. В этой ситуации коэффициент ошибки может быть использован в качестве оценки соответствия, хотя могут использоваться и другие оценки. Если предсказываемое значение распределено непрерывно, для оценки соответствия может использоваться среднеквадратичная ошибка, корень из среднеквадратичной ошибки или медианное абсолютное отклонение.
Применения кросс-валидации
Кросс-валидация может использоваться для сравнения результатов различных процедур предсказывающего моделирования. Например, предположим, что мы интересуемся оптическим распознаванием символов, и рассматриваем варианты использования либо поддерживающих векторов (Support Vector Machines, SVM), либо k ближайших соседей (k nearest neighbors, KNN). С помощью кросс-валидации мы могли бы объективно сравнить эти два метода в терминах относительных коэффициентов их ошибок классификаций. Если мы будем просто сравнивать эти методы по их ошибкам на тренировочной выборке, KNN скорее всего покажет себя лучше, поскольку он более гибок и следовательно более склонен к переподгонке по сравнению с SVM.
Кросс-валидация также может использоваться для выбора параметров. Предположим, у нас есть 20 параметров, которые мы могли бы использовать в модели. Задача – выбрать параметры, использование которых даст модель с лучшими предсказывающими способностями. Если мы будем сравнивать подмножества параметров по их ошибкам на тестовом наборе, лучшие результаты получатся при использовании всех параметров. Однако с кросс-валидацией, модель с лучшей способностью к обобщению обычно включает только некоторое подмножество параметров, которые достаточно информативны.
Вопросы вычислительной производительности
Большинство форм кросс-валидации достаточно просты для реализации, если имеется готовая реализация метода предсказания. В частности, метод предсказания нужен только в виде «черного ящика», нет нужды лезть в детали его реализации. Если метод предсказания достаточно ресурсоемок в тренировке, кросс-валидация может быть медленной, поскольку тренировка выполняется последовательно много раз. В некоторых случаях, таких как метод наименьших квадратов или ядерная регрессия, кросс-валидация может быть существенно ускорена предварительным вычислением некоторых значений, которые используются повторно на тренировке, или используя «правила обновления», такие как формулу Sherman-Morrison. Однако нужно быть осторожным, чтобы обеспечить полное отделение валидационного набора данных от тренировочного, иначе может случиться смещение (bias). Крайний пример ускорения кросс-валидации случается в случае линейной регрессии, где результаты кросс-валидациии имеют явную аналитическую форму, известную как PRESS (prediction residual error sum of squares).
Ограничения и неверное использование кросс-валидации
Кросс-валидация дает значимые результаты только когда тренировочный набор данных и тестовый набор данных берутся из одного источника, из одной популяции. В многих применениях предсказательных моделей структура изучаемой системы меняется со временем. Это может наводить систематические отклонения тренировочного и валидационного наборов данных. К примеру, если модель для предсказания цены акции тренируется на данных из определенного пятилетнего периода, нереалистично рассматривать последующий пятилетний период как выборку из той же самой популяции.
Если выполняется правильно, и наборы данных из одной популяции, кросс-валидация дает результат практически без смещений (bias). Однако, есть много способов использовать кросс-валидацию неправильно. В этом случае ошибка предсказания на реальном валидационном наборе данных скорее всего будет намного хуже, чем ожидается по результатам кросс-валидации.
Способы неверно использовать кросс-валидацию:
1. Использовать кросс-валидацию на нескольких моделях, и взять только результаты лучшей модели.
2. Проводить начальный анализ для определения наиболее информативного набора параметров, используя полный набор данных. Если отбор параметров требуется в модели предсказания, он должен проводиться последовательно на каждом тренировочном наборе данных. Если кросс-валидация используется для определения набора используемых моделью параметров, на каждом тренировочном наборе должна проводиться внутренняя кросс-валидация для определения набора параметров.
3. Позволять некоторым тренировочным данным попадать также и в тестовый набор – это может случиться из-за существования дублирующих наблюдений в исходном наборе.