AlexKorablev.ru

Александр Кораблев о разработке ПО, ИТ-индустрии и Python.
Почему Python такой популярный, если он такой медленный?
Опубликовано 14 December 2015 в Python
На Quora обсуждают почему Python такой популярный, хотя такой медленный. Тема конечно холиварная. Но порассуждать на нее интересно. Ведь Python действительно медленный.
Медленный, если сравнивать его с C/C++ или Java, или C#. Это факт. Python достаточно медленный скриптовый динамический язык программирования. Любая метрика покажет, что программа на C++ будет работать быстрее. Но есть у языков и другая не менее важная метрика: скорость разработки.
Вот тут динамические языки начинают выигрывать. Разрабатывать на Python, Ruby, JS быстрее, чем на Java. А скорость разработки — это прямая экономия для компании. Сегодня разработка продукта заканчивается только, если проект закрывают. В остальных случаях купить еще один инстанс у амазона дешевле, чем увеличить срок разработки какой-либо фичи на пару недель.
В добавок, высокая производительность — не самоцель. Программа должна решать задачу с приемлемой производительностью. Задач где производительность критичная не так много. И даже тогда правильный алгоритм влияет на скорость больше, чем выбор языка реализации.
Не стоит забывать, что процессор в последнее время далеко не всегда является узким местом. Скорее всего, производительность упрется в жесткий диск или сеть, чем в процессор.
Еще один плюс Python (теперь уже по сравнению «одноклассниками») — его простой и читаемый синтаксис. Я слышал много историй, когда ученые, далекие от программирования, предпочитали делать наброски вычислений на Python. Не из-за наличия SciPy/NumPy, а именно из-за того, что такую программу проще написать и объяснить коллегам. Программистам работающим в командах простой синтаксис то же в плюс.
Конечно «батарейки» важны. За это, пожалуй, любят питон ребята из Data Science. Наверняка, для статистических расчетов и анализа есть более интересные инструменты. Но данные для таких расчетов нужно еще извлечь и подготовить. А потом оказывается, что считать на Python так же удобно.
—
Возник вопрос? Мне всегда можно написать в Twitter: avkorablev
Понравилась статья? Поделись с друзьями!
Да, Python медленный, но меня это не волнует
Jun 2, 2017 08:11 · 2104 words · 10 minute read перевод python
Оригинал: ‘Yes, Python is Slow, and I Don’t Care’ by Nick Humrich; перевод был впервые опубликован на Хабрахабре.

Я беру паузу в моём обсуждении asyncio в Python, чтобы поговорить о скорости Python. Позвольте представиться, я — ярый поклонник Python, и использую его везде, где только удаётся. Одна из причин, почему люди выступают против этого языка, — то, что он медленный. Некоторые отказываются даже попробовать на нём поработать лишь из-за того, что «X быстрее». Вот мои мысли на этот счёт.
Производительность более не важна
Раньше программы выполнялись очень долго. Ресурсы процессора и памяти были дорогими, и время работы было важным показателем. А уж сколько платили за электричество! Однако, те времена давно прошли, потому что главное правило гласит:
Оптимизируйте использование своих самых дорогих ресурсов.
Исторически самым дорогим было процессорное время. Именно к этому подводят при изучению информатики, фокусируясь на эффективности различных алгоритмов. Увы, это уже не так — железо сейчас дёшево как никогда, а вслед за ним и время выполнения становится всё дешевле. Самым дорогим же становится время сотрудника, то есть вас. Гораздо важнее решить задачу, нежели ускорить выполнение программы. Повторюсь для тех, кто просто пролистывает статью:
Гораздо важнее решить задачу, нежели ускорить выполнение программы.
Вы можете возразить: «В моей компании заботятся о скорости. Я создаю веб-приложение, в котором все ответы приходят меньше, чем за x миллисекунд» или «от нас уходили клиенты, потому что считали наше приложение слишком медленным». Я не говорю, что скорость работы не важна совсем, я хочу лишь сказать, что она перестала быть самой важной; это уже не самый дорогой ваш ресурс.
Скорость — единственная вещь, которая имеет значение.
Когда вы употребляете слово «скорость» в контексте программирования, скорей всего вы подразумеваете производительность CPU. Но когда ваш CEO употребляет его применительно к программированию, то он подразумевает скорость бизнеса. Самая главная метрика — время выхода на рынок. В конечном счёте неважно насколько быстро работают ваши продукты, не важно на каком языке программирования они написаны или сколько требуется ресурсов для их работы. Единственная вещь, которая заставит вашу компанию выжить или умереть, — это время выхода на рынок. Я говорю больше не о том, насколько быстро идея начнёт приносить доход, а о том, как быстро вы сможете выпустить первую версию продукта. Единственный способ выжить в бизнесе — развиваться быстрее, чем конкуренты. Неважно, сколько у вас идей, если конкуренты реализуют их быстрее. Вы должны быть первыми на рынке, ну или как минимум не отставать. Чуть затормозитесь — и погибните.
Единственный способ выжить в бизнесе — развиваться быстрее, чем конкуренты.
Поговорим о микросервисах

Крупные компании, такие как Amazon, Google или Netflix, понимают важность быстрого развития. Они специально строят свой бизнес так, чтобы быстро вводить инновации. Микросервисы помогают им в этом. Эта статья не имеет никакого отношения к тому, следует ли вам строить на них свою архитектуру, но, по крайней мере, согласитесь с тем, что Amazon и Google должны их использовать. Микросервисы медленны по своей сути. Сама их концепция заключается в том, чтобы использовать сетевые вызовы. Иными словами, вместо вызова функции вы отправляетесь гулять по сети. Что может быть хуже с точки зрения производительности?! Сетевые вызовы очень медленны по сравнению с тактами процессора. Однако, большие компании по-прежнему предпочитают строить архитектуру на основе микросервисов. Я действительно не знаю, что может быть медленнее. Самый большой минус такого подхода — производительность, в то время как плюсом будет время выхода на рынок. Создавая команды вокруг небольших проектов и кодовых баз, компания может проводить итерации и вводить инновации намного быстрее. Мы видим, что даже очень крупные компании заботятся о времени выхода на рынок, а не только стартапы.
Процессор не является вашим узким местом
Если вы пишете сетевое приложение, такое как веб-сервер, скорее всего, процессор не является узким местом вашего приложения. В процессе обработки запроса будет сделано несколько сетевых обращений, например, к базе данных или кешу. Эти сервера могут быть сколь угодно быстрыми, но всё упрётся в скорость передачи данных по сети. Вот действительно классная статья, в которой сравнивается время выполнения каждой операции. В ней автор считает за один такт процессора одну секунду. В таком случае запрос из Калифорнии в Нью-Йорк растянется на 4 года. Вот такая вот сеть медленная. Для примерных расчётов предположим, что передача данных по сети внутри датацентра занимает около 3 мс, что эквивалентно 3 месяцам по нашей шкале отсчёта. Теперь возьмём программу, которая нагружает CPU. Допустим, ей надо 100 000 циклов, чтобы обработать один вызов, это будет эквивалентно 1 дню. Предположим, что мы пишем на языке, который в 5 раз медленнее — это займёт 5 дней. Для тех, кто готов ждать 3 месяца, разница в 4 дня уже не так важна.
В конечном счёте то, что python медленный, уже не имеет значения. Скорость языка (или процессорного времени) почти никогда не является проблемой. Google описал это в своём исследовании. А там, между прочим, говорится о разработке высокопроизводительной системы. В заключении приходят к следующему выводу:
Решение использовать интерпретируемый язык программирования в высокопроизводительных приложениях может быть парадоксальным, но мы столкнулись с тем, что CPU редко когда является сдерживающим фактором; выразительность языка означает, что большинство программ невелики и большую часть времени тратят на ввод-вывод, а не на собственный код. Более того, гибкость интерпретируемой реализации была полезной, как в простоте экспериментов на лингвистическом уровне, так и в предоставлении нам возможности исследовать способы распределения вычислений на многих машинах.
CPU редко когда является сдерживающим фактором.
Что, если мы всё-таки упираемся в CPU?
Что насчёт таких аргументов: «Всё это прекрасно, но что, если CPU становится узким местом и это начинает сказываться на производительности?» или «Язык x менее требователен к железу, нежели y»? Они тоже имеют место быть, однако вы можете масштабировать приложение горизонтально бесконечно. Просто добавьте серверов, и сервис будет работать быстрее 🙂 Без сомнения, Python более требователен к железу, чем тот же C, но стоимость нового сервера гораздо меньше стоимости вашего времени. То есть дешевле будет докупить ресурсов, а не бросаться каждый раз что-то оптимизировать.
Так что, Python быстрый?
На протяжении всей статьи я твердил, что самое важное — время разработчика. Таким образом, остается открытым вопрос: быстрее ли Python языка X во время разработки? Смешно, но я, Google и кое-кто ещё, могут подтвердить насколько продуктивен Python. Он скрывает так много вещей от вас, помогая сосредоточиться на основной вашей задаче и не отвлекаясь на всякие мелочи. Давайте рассмотрим некоторые примеры из жизни.
По большей части все споры вокруг производительности Python скатываются к сравнению динамической и статической типизации. Думаю, все согласятся, что статически типизированные языки менее продуктивны, но на всякий случай вот хорошая статья, объясняющая почему. Что касается непосредственно Python, то есть хороший отчёт об исследовании, в котором рассматривается, сколько времени потребовалось, чтобы написать код для обработки строк на разных языках.
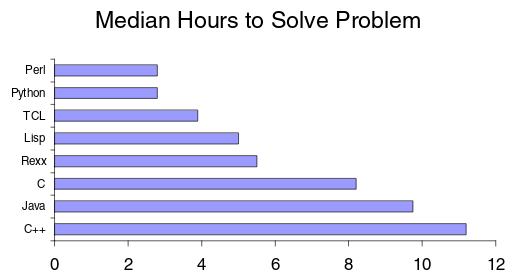
В представленном выше исследовании Python более чем в 2 раза продуктивнее Java. Многие другие также языки программирования дают похожий результат. Rosetta Code провёл довольно обширное исследование различий изучения языков программирования. В статье они сравнивают python с другими интерпретируемыми языками и заявляют:
Python, в целом, наиболее краток, даже в сравнении с функциональными языками (в среднем в 1,2-1,6 раза короче).
По-видимому, в реализации на Python будет как правило меньше строк кода, чем на каком-либо другом языке. Это может показаться ужасной метрикой, однако несколько исследований, в том числе и упомянутых выше, показывают, что время, затраченное на каждую строку кода, примерно одинаково на каждом языке. Таким образом, чем меньше строк кода, тем больше продуктивность. Даже сам codinghorror (программист на C#) написал статью о том, что Python более продуктивен.
Я думаю, будет справедливо сказать, что Python более продуктивен, чем многие другие языки программирования. В основном это связано с тем, что он поставляется «с батарейками», а также имеет множество сторонних библиотек на все случаи жизни. Вот небольшая статья, сравнивающая Python и X. Если вы мне не верите, можете сами убедиться насколько этот язык программирования прост и удобен. Вот ваша первая программа:
import __hello__ Но что, если скорость действительно важна?
Мои рассуждения выше могли сложить мнение, что оптимизация и скорость выполнения программы вообще не имеют значения. Во многих случаях это не так. Например, у вас есть веб-приложение и некоторый endpoint, который уж очень тормозит. У вас могут быть даже определённые требования на этот счёт. Наш пример строится на некоторых предположениях:
- есть некоторый endpoint, который выполняется медленно
- есть некоторые метрики, определяющие насколько медленными может быть обработка запросов
Мы не будем заниматься микро-оптимизацией всего приложения. Всё должно быть «достаточно быстро». Ваши пользователи могут заметить, если обработка запроса занимает секунды, но они никогда не заметят разницу между 35 мс и 25 мс. Вам нужно лишь сделать приложение «достаточно хорошим».
Дисклаймер
Должен заметить, что есть некоторые приложения, которые обрабатывают данные в реальном времени, которые нуждаются в микрооптимизации, и каждая миллисекунда имеет значение. Но это скорее исключение, чем правило.
Чтобы понять как оптимизировать, мы должны сначала понять что именно надо оптимизировать. В конце концов:
Любые улучшения, сделанные где-либо помимо узкого места, являются иллюзией. — Джин Ким.
Если оптимизация не устраняет узкого места приложения, то вы просто потратите впустую своё время и не решите реальную проблему. Вы не должны продолжать разработку, пока не исправите тормоза. Если вы пытаетесь оптимизировать нечто, не зная конкретно что, то вряд ли результат вас удовлетворит. Это и называется «преждевременной оптимизацией» — улучшение производительности без каких-либо метрик. Д. Кнуту часто приписывают следующую цитату, хотя он утверждает, что она не его:
Преждевременная оптимизация — корень всех зол.
Если быть точным, то более полная цитата:
Мы должны забыть об эффективности, скажем, на 97% времени: преждевременная оптимизация — корень всех зол. Однако мы не должны упускать наши возможности в этих критических 3%.
Другими словами, здесь говорится, что большую часть времени вам не нужно думать об оптимизации. Код и так хорош 🙂 А в случае, когда это не так, нужно переписать не более 3% Вас никто не похвалит, если вы сделаете обработку запроса на несколько наносекунд быстрее. Оптимизируйте то, что поддаётся измерению.
Преждевременная оптимизация, как правило, заключается в вызове более быстрых методов или использовании специфичных структур данных из-за их внутренней реализации. В университете нас учили, что если два алгоритма имеют одну асимптотику Big-O, то они эквивалентны. Даже если один из них в 2 раза медленнее. Компьютеры сейчас настолько быстры, что вычислительную сложность пора измерять на большом количестве данных. То есть, если у вас есть две функции O(log n), но одна в два раза медленнее другой, то это не имеет большого значения. По мере увеличения размера данных они обе начинают показывать примерно одно и то же время выполнения. Вот почему преждевременная оптимизация — это корень всего зла; Это тратит наше время и практически никогда не помогает нашей общей производительности.
В терминах Big-O все языки программирования имеют сложность O(n), где n — кол-во строк кода или инструкций. Не имеет значения, насколько медленным будет язык или его виртуальная машина — все они имеют общую асимптоту. В соответствии с этим рассуждением можно сказать, что «быстрый» язык программирования всего лишь преждевременно оптимизированный, причём непонятно по каким метрикам.
Оптимизируя Python
Что мне нравится в Python, так это то, что он позволяет оптимизировать небольшой участок кода за раз. Допустим, у вас есть метод на Python, который вы считаете своим узким местом. Вы оптимизировали его несколько раз, возможно, следуя советам отсюда и отсюда, и теперь пришли к выводу, что уже сам Python является узким местом. Но он имеет возможность вызова кода на C, а это означает, что вы можете переписать этот метод на C, чтобы уменьшить проблему с производительностью. Вы без проблем можете использовать этот метод вместе с остальным кодом.
Это позволяет писать хорошо оптимизированные методы узких мест на любом языке, который компилируется в ассемблерный код, то есть вы продолжаете писать на Python большую часть времени и переходите к низкоуровневому программированию лишь вам это действительно нужно.
Существует также язык Cython, который является надмножеством Python. Он представляет из себя смесь с типизированным C. Любой код Python является также валидным кодом и на Cython, который транслируется в C. Вы можете смешивать типы C и утиную типизацию. Используя Cython, вы получаете прирост производительности только в узком месте, не переписывая весь остальной код. Так делает, например, EVE Online. Эта MMoRPG использует только Python и Cython для всего стека, проводя оптимизацию только там, где это требуется. Кроме того, есть и другие способы. Например, PyPy — реализация JIT Python, которая может дать вам значительное ускорение во время выполнения долгоживущих приложений (например, веб-сервера), просто путем замены CPython (реализация по умолчанию) на PyPy.
Итак, основные моменты:
- оптимизируйте использование самого дорогого ресурса — то есть вас, а не компьютера;
- выбирайте язык/фреймворк/архитектуру, которая позволяет вам разрабатывать продукты как можно быстрее. Не стоит выбирать язык программирования лишь потому, что программы на нём работают быстро;
- если у вас проблемы с производительностью — определите, где именно;
- и, скорее всего, это не ресурсы процессора или Python;
- если это всё же Python (и вы уже оптимизировали алгоритм), реализуйте проблемное место на Cython/C;
- и побыстрее возвращайтесь к основной работе.
«Python медленный» и другие мифы об уходящей эпохе

Когда я был маленьким, программирование было простым. У моего друга был компьютер и там были Basic и Assembly. Вы можете написать свою программу на языке Basic, что проще, но ваша программа будет работать медленно, или вы можете написать что-то на ассемблере, что будет сложнее, но ваша программа будет работать значительно быстрее.
Объяснение этому тоже было простое. Basic был интерпретатором, чтобы запустить вашу программу, он должен был просматривать ваш код каждый раз, когда вы его вызываете, и интерпретировать его построчно. Если он говорит «PRINT X», интерпретатор должен найти переменную с именем «X», найти подпрограмму, которая выполняет печать, и вызвать найденную подпрограмму для найденной переменной. n n Сборка была, ну, сборкой. Он тоже каким-то образом интерпретировал вашу программу, но только один раз, когда вы запускали ассемблер. После этого ваша программа будет выполняться без интерпретации. Программы, требующие интерпретации, работают медленнее, чем программы, не требующие интерпретации. Если, конечно, это равнозначные программы. n n А в Basic и Assembly они обычно были. Basic — императивный язык, даже не слишком дружественный к структурному программированию. Даже такая базовая вещь, как «функция», является там не встроенной языковой конструкцией, а шаблоном: «GOSUB. RETURN», очень похожим на «call. ret» в ассемблере. n n Теперь перенесемся на 30 лет вперед. Языков предостаточно. Компьютеры повсюду. Программирование перестало быть простым. Мой отдел зарабатывает себе на хлеб, переписывая код исследователя, изначально написанный на Python, на C++ для повышения производительности, потому что общеизвестно, что Python интерпретируется и работает медленно, а C++ компилируется и быстро. Но каким-то образом с каждым годом эта переделка становится все труднее и труднее выиграть какое-либо выступление. Что-то меняется и меняется быстро. Общеизвестное, однако, не меняется, поэтому мы продолжаем переписывать. n n Но теперь мы вынуждены оптимизировать все как сумасшедшие, чтобы оправдать то, что мы делаем. Приходит алгоритм на Python, переписываем его эквивалентно на C++, и вдруг он становится в 3 раза медленнее. Это. не то, для чего мы здесь. Поэтому мы реконструируем алгоритм, чтобы добиться обещанного прироста производительности. И в большинстве случаев, поскольку исследователи вообще не заботятся о производительности, а с точки зрения алгоритмов они оставляют некоторые низко висящие плоды, это работает. n n Тем не менее, весь этот бизнес теперь выглядит как афера. Мы делаем код медленнее, переписывая его на C++, чтобы мы могли сделать его быстрее, реинжиниринг кода. Почему бы нам тогда не перепроектировать его непосредственно в Python? Ах! Дело в том, что мы не знаем Python. Мы немного знаем Python, достаточно, чтобы читать и понимать, но недостаточно, чтобы делать на нем сверхбыстрые программы. n n Итак, что нужно знать?
Библиотеки
Большинство библиотек Python написаны на C или Fortran. Ядро NumPy написано на C; Pandas — в Cython и C; SciPy — на Фортране, C и частично на C++. У них нет причин быть медленнее, чем то, что было написано на C++, Rust или Julia. Хотя они могут быть быстрее. n n В нашей компании мы обслуживаем как облачные сервисы, так и настольные приложения. А пользователи десктопов злятся, когда новая версия их любимого приложения перестает работать на их железе без всякой видимой причины. Таким образом, мы сохраняем наши настольные сборки целевыми. Очень старый, как до Nehalem старый. Таким образом, никто не злится, но и не получает удовольствия от SSE3.
Конечно, вычислительная библиотека, созданная для надлежащей цели, обычно будет быстрее, чем эквивалентная библиотека, созданная для обычного компьютера 15-летней давности с ограниченными суперскалярными возможностями.
Хорошая новость заключается в том, что если вы создаете для облака, вы можете выбрать в качестве целевой платформы сборки именно тот компьютер, который вы приобретете, и тогда ваши библиотеки C++ будут работать с той же скоростью, что и библиотеки Python, а может быть, даже немного медленнее. немного быстрее.
Компиляторы
Честно говоря, весь спор о том, какой язык быстрее, смехотворен. Язык — это не компилятор и не интерпретатор, это то, чем он является — язык: набор правил, определяющих, как мы должны сообщать компьютеру, что мы хотим делать. Язык — это всего лишь набор правил, спецификация. И ничего больше.
Само различие между интерпретацией и компиляцией осталось в прошлом веке. В настоящее время существуют интерпретаторы C, такие как IGCC, PicoC или CCons, и есть компиляторы Python. Компиляторы JIT, такие как [PyPy], и классические компиляторы с компиляцией перед запуском, такие как Codon (который также поддерживает JIT, если вы хотите, чтобы была скомпилирована только часть вашего кода).
Codon построен на LLVM, той же инфраструктуре, на которой построены Rust, Julia или Clang. Код, созданный с помощью Codon, работает, плюс-минус, с тем же уровнем производительности, что и созданный с помощью любого из них. Могут быть недостатки производительности из-за сборки мусора Python или больших собственных типов данных, но мы больше не говорим о 100x или 10x. LLVM творит чудеса. он превращает код Python в машинный код для вас.
Существуют также мифы о своевременной компиляции или JIT. Некоторые говорят, что он превосходит обычную технику компиляции перед запуском, потому что он всегда компилируется для архитектуры, имеющейся у пользователей, и, таким образом, оптимально использует ее. Некоторые говорят, что по-прежнему существуют накладные расходы на компиляцию, которые при своевременной компиляции также ложатся на пользователей. Из-за этого программы работают медленнее, так как они должны запускаться и компилироваться одновременно.
Проблема обоих мифов в том, что они оба правдивы и бесполезны. Да, JIT обычно компилирует в лучший машинный код, если вы не создаете свои двоичные файлы явно для целевой машины, что, кстати, происходит довольно регулярно при развертывании в облаке. И да, во время выполнения есть штраф за компиляцию, но он незначителен, если время выполнения измеряется месяцами, что, опять же, при развертывании в облаке не является чем-то неслыханным.
Так что есть плюсы и минусы. Что важно, Python (в частности, Codon) поддерживает режимы компиляции перед запуском и JIT, поэтому вы можете выбрать то, что больше всего соответствует вашим потребностям. Традиционные компиляторы, такие как Clang, не имеют параметра JIT.
Numba и его модель ядра
Говоря о JIT, Numba, вероятно, является самой революционной технологией в мире сверхбыстрого программирования на Python. Это компилятор, но он нацелен только на выбранные ядра, а не на всю программу. Вы, конечно, можете выбрать, что компилировать и для какой платформы. В этой настройке вы можете запускать части своего кода на ЦП, а остальные — на GPGPU.
Технически можно создавать серверные части для других специализированных устройств, таких как TPU от Google или даже фотонный ускоритель. Такого бэкенда пока нет, ребята решили выкатить собственную библиотеку. Но, что симптоматично, они также решили предоставить интерфейс для фотонного компьютера на Python, чтобы вы могли беспрепятственно взаимодействовать с Pytorch, Tensorflow или ONNX.
Так что Лайтматерии еще нет. Но Нвидиа есть. Они предоставили свой бэкэнд CUDA для Numba, и теперь вы можете писать ядра на Python и запускать их на оборудовании NVidia с максимальной эффективностью. В С++ этого нет. Однако существует диалект CU, исходящий от NVidia, который, конечно же, расширяет C++ именно в этом отношении. В Python вам не нужно расширять сам язык. Поскольку Numba работает как JIT-компилятор ядра, добавление бэкенда — это всего лишь вопрос исправления библиотеки.
Итак, модель ядра ориентирована на гетерогенные вычисления. Вы можете запускать фрагменты кода на разных устройствах, что само по себе приятно. Но есть еще одно измерение неоднородности, о котором вы, возможно, не задумывались. С моделью ядра вы можете ориентироваться на разные ядра для разных контекстов вычислений и не обязательно для аппаратных устройств. Это означает, что если вы хотите, чтобы одно ядро было быстрым, но не особенно точным, вы можете собрать его с опцией «-fast-math». Но если в каком-то другом контексте вы хотите, чтобы это ядро было точным, а не быстрым, вы можете пересобрать тот же самый код без компромиссов.
Это то, чего трудно достичь с помощью традиционных компиляторов, где вы не можете изменить параметры компиляции в середине единицы перевода. Что ж, в модели ядра каждое ядро представляет собой собственную единицу трансляции.
Заключение
Python не медленный. Ни это быстро. Это просто язык, набор правил и ключевых слов. Но есть много людей, которые привыкли к этим правилам и этим ключевым словам. Им удобно писать на Python, и они заинтересованы в том, чтобы сделать Python для них лучше.
Эта пользовательская база достаточно велика, чтобы привлечь как новые стартапы с революционными технологиями, такими как Lightmatter и их фотонные компьютеры, так и хорошо зарекомендовавшие себя компании с многолетним опытом в области высокопроизводительных вычислений, такие как NVidia. Все эти люди вкладывают огромные средства в то, чтобы сделать Python лучше. не в язык, конечно, а в среду. Среда, в которой писать сверхбыстрые программы лишь немногим сложнее, чем медленные одноразовые программы.
В целом они делают огромный прогресс. Python становится быстрее с каждым годом. На данный момент забудьте о фотонных компьютерах, если можете, программы, написанные на Python, часто работают наравне с программами, написанными на Julia, C++ или Rust. Но Python не останавливался на достигнутом. Он работает быстрее, чем традиционные компиляторы, и становится удобнее для пользователя.
Будьте готовы к тому, что через несколько лет компиляторы Python: PyPy, Numba или что-то совершенно новое, будут заимствовать методы у Spiral или Herbie, чтобы генерировать код настолько более эффективно, что ни один традиционный компилятор не мог приблизиться к этому. В конце концов, написать новый JIT-бэкэнд на Python гораздо проще, чем переосмыслить всю инфраструктуру LLVM.
Почему ИИ пишут на питоне, если он медленный? [закрыт]
Закрыт. На этот вопрос невозможно дать объективный ответ. Ответы на него в данный момент не принимаются.
Хотите улучшить этот вопрос? Переформулируйте вопрос так, чтобы на него можно было дать ответ, основанный на фактах и цитатах.
Закрыт 3 месяца назад .
Зачем это делают? Питон это довольно медленный язык
- python
- искусственный-интеллект
Отслеживать
25.5k 4 4 золотых знака 21 21 серебряный знак 36 36 бронзовых знаков
задан 12 окт 2023 в 8:32
ИИ обучается и выполняется не на питоне, это просто удобное высокоуровневое АПИ, а внутри там обычный C/C++ и код для видеокарт
12 окт 2023 в 8:36
Библиотеки машинного обучения используют Си, Фортран даже, и Си++. Обертка в виде Питона позволяет обеспечить удобство работы.
12 окт 2023 в 8:41
1 ответ 1
Сортировка: Сброс на вариант по умолчанию
По поводу питона сказано:
Прежде всего, Python — язык с открытым исходным кодом. Это означает, что он доступен для любых модификаций, которые разработчики сочтут нужными. Этот язык программирования постоянно развивается, что упрощает его синтаксис и повышает его эффективность. Во-вторых, существует большое количество готовых к использованию библиотек, которые помогают ускорить написание кода. Например, TensorFlow широко применяется для машинного обучения и работы с наборами данных; scikit — для обучения моделей машинного обучения; PyTorch — для обработки речи и для компьютерного зрения. Это ощутимое преимущество, которое может помочь ускорить разработку и сэкономить ресурсы, поскольку позволяет применять готовые решения вместо их создания с нуля.