Как конвертировать csv в excel в Jupyter Notebook
Ну что, начинаю тут вещать и собирать свои лайфхаки. Без них бы я не разобралась в том, что знаю сейчас.
В Jupyter’е есть как минимум с десяток классных функций упрощающих жизнь всем, для примера возьму импорт и экспорт датафреймов:
Импорт
pd.read_csv(filename) | Загрузить CSV file
pd.read_table(filename) | Из текстового файла с разделителями (например, TSV)
pd.read_excel(filename) | Загрузить Excel file
pd.read_sql(query, connection_object) | Загрузка из таблицы / базы данных SQL
pd.read_json(json_string) | Чтение из строки, URL или файла в формате JSON
pd.read_html(url) | Разбирает html URL, строку или файл и извлекает таблицы в список датафреймов
pd.read_clipboard() | Берет содержимое вашего буфера обмена и передает его в read_table()
pd.DataFrame(dict) | Словарь, ключи для имен столбцов, значения для данных в виде списков
Экспорт
df.to_csv(filename) | Записать в CSV file
df.to_excel(filename) | Записать в Excel file
df.to_sql(table_name, connection_object) | Записать в SQL table
df.to_json(filename) | Записать в JSON format
Сегодня расскажу немножко про боль при сохранении cvs в excel, ключевое почему не срабатывает просто сухое to_excel() — нужно сначала записать данные в эксель, а после сохранять.
Например у вас загружен в Jupyter csv с помощью pd.read_csv(filename)
Ниже будет перевод материала из вот этой статьи на медиуме, спасибо @Stephen Fordham.
У Стивена очень подробно все описано, даже с примером как в файл сохранить несколько датафреймов в разные вкладки. Я же представлю скрин того, как сохранить один датафрейм.
Опишу то что мы видим, чтобы использовать Pandas для записи объектов Dataframe в Excel, необходимо установить 2 библиотеки. Это библиотеки xlrd и openpyxl соответственно. Для удобства эти библиотеки можно установить, не выходя из Jupyter Notebook, просто добавив к команде префикс ! подписать с последующей установкой pip . Когда эта ячейка будет выполнена, вывод будет либо «Требование уже выполнено», либо установка будет выполнена автоматически.
Отвечаю на вопрос, почему у меня на скрине ! pip install openpyxl==3.0.1
При установке последней версии методом ! pip install openpyxl (ставится последняя версия 3.0.2) у меня возникает ошибка при выполнении сохранения TypeError: got invalid input value of type , expected string or Element
Собственно вопрос решается если ставить версию ниже
Далее все проще, как пишет Стивен в своей публикации — От Pandas Dataframe к Excel за 3 шага
- Чтобы начать процесс экспорта Pandas Dataframes в Excel, необходимо создать объект ExcelWriter. Это достигается с помощью метода ExcelWriter, который вызывается непосредственно из библиотеки панд. В этом методе я указываю имя файла Excel (в статье по ссылке автор выбрал Tennis_players, у меня же вы найдете games) и включаю расширение .xlsx. Этот шаг создает основную книгу экселя, в которую мы можем затем записать наши датафреймы.
- После этого я вызываю метод .to_excel на скрине выше. В методе .to_excel первым аргументом, который нужно указать, является объект ExcelWriter, за которым следует необязательный параметр имя листа. (я не использовала индекс, но в статье, на которую я ссылаюсь устанавливают аргумент index =False, по умолчанию, кстати, идет True) Проставляем аргумент ‘utf-8’ для параметра encoding для обработки любых специальных символов. Тоже самое можно повторить и для других датафреймов, единственное записывать их в разные листы, параметр sheet_name.
- Наконец, теперь, когда наши датафреймы поставлены в очередь для экспорта, мы вызываем метод save для объекта ExcelWriter, который мы назначили переменной my_excel_file.
Как загрузить файл csv с кириллицей в Jupyter notebook?
sazhyk, Мое решение: изначально надо файл сохранить в utf-8, потом как csv и все работает.

но есть новая проблема: при выводе данных добавляются нули после точки.
вопрос как их убрать.
те мне надо на выходе иметь: 2.26, 1.02. без лишних нулей
Dmitry, слишком мало входных данных вопроса. я же не знаю как вы получаете эти данные.
Dmitry @provocatorr Автор вопроса
import pandas as pd lists_and_loops_data_3 = pd.read_csv('lists_and_loops_data_3.csv') lists_and_loops_data_3Dmitry, я так понимаю, в исходных данных так и есть, и эти цифры импортируются как строки. Вы их сделайте типом float и работайте как с вещественными числами. Ну или используйте decimal. Там где надо можно округлить наверное.
Dmitry @provocatorr Автор вопроса
sazhyk, проблема в том что в файле есть цифра 2.26 а после импорта она становится 2.2600. Вопрос: как прописать импорт правильно чтоб было полное совпадение?
Как импортировать файл формата csv в python (panda)?
На что получил ошибку.
Пробовал закидывать файл в папку pandas (подпапка анаконды), не помогло. Пробовал также загрузить файл в окне стартовой страницы Jupiter- тоже не помогло. Ч.Я.Д.Н.Т.?
- Вопрос задан более трёх лет назад
- 2753 просмотра
1 комментарий
Простой 1 комментарий
Вам нужно прописать адрес расположения файла 131.csv или положить его в директорию, где находится файл Jupiter notebook..
Решения вопроса 1

Получил ошибку — нормально.
Скрыл её от нас — нехорошо.
Как мы тебе поможем?
Ответ написан более трёх лет назад
Нравится 3 4 комментария
Вениамин Белоусов @Venuhaha Автор вопроса
Просто мне казалось что я изначально делаю что-то не так. Так как в учебнике вообще этому не уделяется внимание, как 2+2. Не могу понять, как ему показать где лежит файл. Вообще все странно. Согласно учебнику- я пишу две строки кода и все.
Вот ошибка-
spoiler
--------------------------------------------------------------------------- ValueError Traceback (most recent call last) in () 1 import pandas ----> 2 data = pandas . read_csv ( "titanic.csv " , index_col="PassengerId " ) D:\Anaconda\lib\site-packages\pandas\io\parsers.py in parser_f(filepath_or_buffer, sep, delimiter, header, names, index_col, usecols, squeeze, prefix, mangle_dupe_cols, dtype, engine, converters, true_values, false_values, skipinitialspace, skiprows, nrows, na_values, keep_default_na, na_filter, verbose, skip_blank_lines, parse_dates, infer_datetime_format, keep_date_col, date_parser, dayfirst, iterator, chunksize, compression, thousands, decimal, lineterminator, quotechar, quoting, escapechar, comment, encoding, dialect, tupleize_cols, error_bad_lines, warn_bad_lines, skipfooter, skip_footer, doublequote, delim_whitespace, as_recarray, compact_ints, use_unsigned, low_memory, buffer_lines, memory_map, float_precision) 653 skip_blank_lines=skip_blank_lines) 654 --> 655 return _read(filepath_or_buffer, kwds) 656 657 parser_f.__name__ = name D:\Anaconda\lib\site-packages\pandas\io\parsers.py in _read(filepath_or_buffer, kwds) 409 410 try: --> 411 data = parser.read(nrows) 412 finally: 413 parser.close() D:\Anaconda\lib\site-packages\pandas\io\parsers.py in read(self, nrows) 1003 raise ValueError('skipfooter not supported for iteration') 1004 -> 1005 ret = self._engine.read(nrows) 1006 1007 if self.options.get('as_recarray'): D:\Anaconda\lib\site-packages\pandas\io\parsers.py in read(self, nrows) 1824 1825 names, data = self._do_date_conversions(names, data) -> 1826 index, names = self._make_index(data, alldata, names) 1827 1828 # maybe create a mi on the columns D:\Anaconda\lib\site-packages\pandas\io\parsers.py in _make_index(self, data, alldata, columns, indexnamerow) 1333 1334 elif not self._has_complex_date_col: -> 1335 index = self._get_simple_index(alldata, columns) 1336 index = self._agg_index(index) 1337 D:\Anaconda\lib\site-packages\pandas\io\parsers.py in _get_simple_index(self, data, columns) 1367 index = [] 1368 for idx in self.index_col: -> 1369 i = ix(idx) 1370 to_remove.append(i) 1371 index.append(data[i]) D:\Anaconda\lib\site-packages\pandas\io\parsers.py in ix(col) 1361 if not isinstance(col, compat.string_types): 1362 return col -> 1363 raise ValueError('Index %s invalid' % col) 1364 index = None 1365 ValueError: Index PassengerId invalidРуководство по Загрузка данных и выполнение запросов в кластере Apache Spark в Azure HDInsight
В этом руководстве описывается, как создать кадр данных из CSV-файла и как отправлять интерактивные запросы SQL Spark к кластеру Apache Spark в Azure HDInsight. В Spark кадр данных — это распределенная коллекция данных, упорядоченных в именованных столбцах. Она эквивалентна таблице в реляционной базе данных или фрейме данных в R/Python.
В этом руководстве описано следующее:
- Создание кадра данных из CSV-файла
- Выполнение запросов к кадру данных
Предварительные требования
Создание записной книжки Jupyter
Jupyter Notebook — это интерактивная среда Notebook, которая поддерживает различные языки программирования. Notebook позволяет работать с данными, объединять код с текстом Markdown и выполнять простые визуализации.
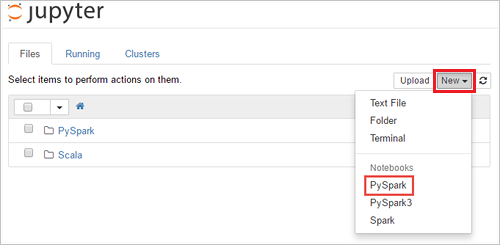
- Измените URL-адрес https://SPARKCLUSTER.azurehdinsight.net/jupyter , заменив SPARKCLUSTER именем кластера Spark. В веб-браузере введите измененный URL-адрес. При появлении запроса введите учетные данные для входа в кластер.
- На веб-странице Jupyter для кластеров Spark 2.4, выберите New (Создать)>PySpark, чтобы создать записную книжку. Для выпуска Spark 3.1 вместо этого выберите New (Создать)>PySpark3, чтобы создать записную книжку, поскольку ядро PySpark больше не доступно в Spark 3.1. Будет создана и открыта записная книжка с именем Untitled( Untitled.ipynb ).
Примечание Если записная книжка создается с использованием PySpark или ядра PySpark3, сеанс spark автоматически создается при выполнении первой ячейки кода. Вам не нужно явно создавать этот сеанс.
Создание кадра данных из CSV-файла
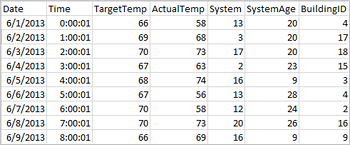
Приложения могут создавать кадры данных непосредственно из файлов или папок в удаленном хранилище, например в службе хранилища Azure или Azure Data Lake Storage, из таблицы Hive или из других источников данных, поддерживаемых Spark, таких как Azure Cosmos DB, Azure SQL DB, DW и т. д. На снимке экрана показан моментальный снимок файла hvac.csv, используемого в этом руководстве. CSV-файл содержит все кластеры HDInsight Spark. Эти данные демонстрируют колебания температуры в некоторых зданиях.
-
Вставьте следующий код в пустую ячейку записной книжки Jupyter Notebook и нажмите SHIFT+ВВОД для выполнения кода. Код импортирует типы, необходимые для этого сценария:
from pyspark.sql import * from pyspark.sql.types import * 
При запуске интерактивного запроса в Jupyter в заголовке окна веб-браузера или вкладки будет отображаться состояние (Busy) (Занято), а также название приложения. Кроме того, рядом с надписью PySpark в верхнем правом углу окна будет показан закрашенный кружок. После завершения задания он изменится на кружок без заливки.
# Create a dataframe and table from sample data csvFile = spark.read.csv('/HdiSamples/HdiSamples/SensorSampleData/hvac/HVAC.csv', header=True, inferSchema=True) csvFile.write.saveAsTable("hvac") Выполнение запросов к кадру данных
Когда таблица будет готова, выполните интерактивный запрос к данным.
-
В пустой ячейке приложения выполните следующий код:
%%sql SELECT buildingID, (targettemp - actualtemp) AS temp_diff, date FROM hvac WHERE date = \"6/1/13\" Отобразятся следующие табличные данные. 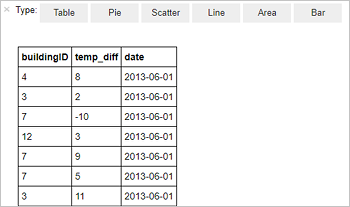
Очистка ресурсов
С HDInsight ваши данные и записные книжки Jupyter Notebook сохраняются в Службе хранилища Azure или Azure Data Lake Storage, что позволяет безопасно удалить неиспользуемый кластер. Плата за кластеры HDInsight взимается, даже когда они не используются. Так как затраты на кластер во много раз превышают затраты на хранилище, экономически целесообразно удалять неиспользуемые кластеры. Если вы планируете сразу приступить к следующему руководству, можно оставить кластер.
Откройте кластер на портале Azure и выберите Удалить.
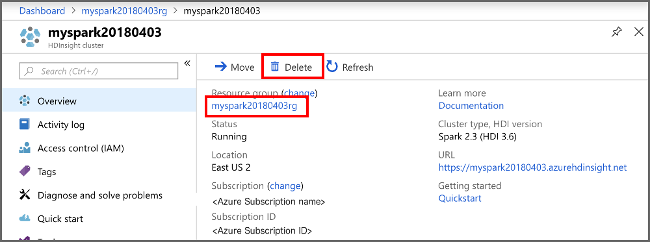
Кроме того, можно выбрать имя группы ресурсов, чтобы открыть страницу группы ресурсов, а затем щелкнуть Удалить группу ресурсов. Вместе с группой ресурсов вы также удалите кластер Spark в HDInsight и учетную запись хранения по умолчанию.
Дальнейшие действия
В этом учебнике описывается, как создать кадр данных из CSV-файла и как отправлять интерактивные запросы SQL Spark к кластеру Apache Spark в Azure HDInsight. Теперь переходите к следующей статье, в которой объясняется, как перенести зарегистрированные в Apache Spark данные в средство бизнес-аналитики, например в Power BI.